

1 数据库操作 (所以命令可大小写,规范为大写)
创建数据库:(数据库名开头不能为数字)
create database db2;(注意添加结尾的分号)
删除数据库:
drop database db1;
查看数据库列表:
show databases;
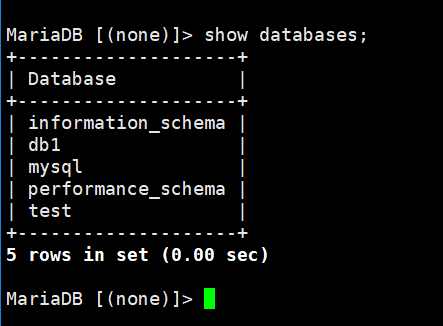
进入其中的某个数据库:
use db1;
进入某个数据库后查看此库里有那些表:
show tables;
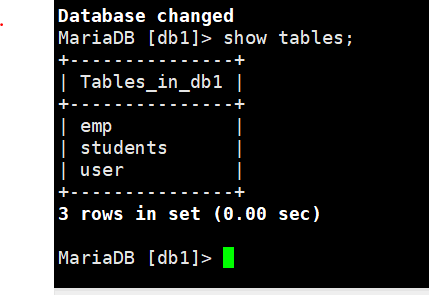
在数据库中使用bsah的命令:stem/\! +bash命令 (stem ls /etc /或者\! ls /etc/)
数据库的终端命令可查看帮助:> help
查看支持所有字符集:SHOW CHARACTER SET;
查看支持所有排序规则:SHOW COLLATION;
获取命令使用帮助: mysql> HELP KEYWORD;
2 .创建表 (数据库下存放各种表)
创建表:CREATE TABLE
(1) 直接创建 新表:
create table students ( id tinyint unsigned not null primary key,name char(10) not null,sex char(1),phone char(11) );
(第一项为创建的id,采用最小的整数,不为空,且为主键;第二项为姓名;给定十个字符;第四个为性别,给一个字符;第五项为电话号码,设定为11个字符)
create table emp ( id int unsigned auto_increment primary key,name char(4) not null ,sex char(1) default ‘m’,adress char(20) );
auto_increment:数字自动递增;unsigned 放在int定义数字的后面
小结:一个汉字,字母数字在char里都算一个字符。primary key放在最后;添加各种修饰符要注意前后顺序,如上例中,如果将修饰符的顺序更改则会报错不能生成此表;
(2) 通过查询现存表创建新的表,连数据一起创建了。
create table user select user,host,password from mysql.user;
mysql.user:mysql是一个库,user是其库里的一个表
(3) 通过复制现存的表的表结构创建,但不复制数据
create table user1 like mysql.user;
3 .表操作
查看创建的表结构:
desc students;
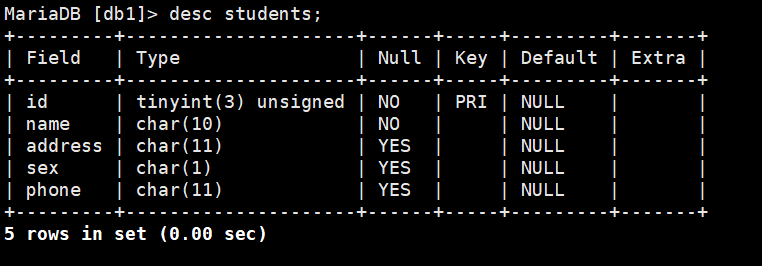
查看库里的表;(首先进入到此库中然后查看)
show tables;
删除库里的某个表: (首先还是要进入到存放此表的库里,查看后删除)
drop table students
级联删除;
如果某两个表之间是相互关连的关系,是不能删除其中一个的,会报提示错误。
查看单个表状态:
show table status like ‘students’\G; (表名必须要加引号)
查看库中所有表的状态:
show table status from db1\G; (G 为竖列查看)
对创建好的表进行修改:(一般表创建好后不建议去修改它,会造成数据的丢失)
对已经创建好的表添加一个字段:
alter table students add address char (11) after name;
对students表添加一个地址的字段,定义地址字段的格式,在name 字段后添加;
对已经创建好的表删除某个字段:
alter table students drop address
对students表删除一个 字段
ALTER TABLE s1 CHANGE COLUMN phone mobile char(11); (对phone字段改名并重新定义数据类型)
数据类型 :
选择正确的数据类型对于获得高性能至关重要,
三大原则:
更小的通常更好,尽量使用可正确存储数据的最小数据类型
简单就好,简单数据类型的操作通常需要更少的CPU周期
尽量避免NULL,包含为NULL的列,对MySQL更难优化
具体内容查看30天的第二个视频
1、整数的范围(找自己表合适的使用,使用越大的范围占用的内存空间越大)
tinyint 1个字节 范围(-128~127)
smallint 2个字节 范围(-32768~32767)
mediumint 3个字节 范围(-8388608~8388607)
int 4个字节 范围(-2147483648~2147483647) (无论是几都要占用4个字节)
bigint 8个字节 范围(+-9.22*10的18次方) (无论是几都要占用8个字节)
取值范围如果加了unsigned,则最大值翻倍,如tinyint unsigned的取值范围为(0~255) 取正整数。
2、浮点型(float和double),近似值
float(m,d) 单精度浮点型 8位精度(4字节) m总个数,d小数位
double(m,d) 双精度浮点型16位精度(8字节) m总个数,d小数位
设一个字段定义为float(6,3),如果插入一个数123.45678,实际数据库里存的是 123.457,但总个数还以实际为准,即6位
3、定点数
在数据库中存放的是精确值,存为十进制 decimal(m,d) 参数m<65 是总个数,d<30且 d<m 是小数位
4 .字符串(char,varchar,_text)
char(n) 固定长度,最多255个字符 (常用的定义表字符的长度最少时4个字符,与下面的比效率高)
varchar(n)可变长度,最多65535个字符 (同上最少可以为一个字符减少空间的使用,但效率低)
tinytext 可变长度,最多255个字符
text 可变长度,最多65535个字符
mediumtext 可变长度,最多2的24次方-1个字符
longtext 可变长度,最多2的32次方-1个字符
BINARY(M) 固定长度,可存二进制或字符,长度为0-M字节
VARBINARY(M) 可变长度,可存二进制或字符,允许长度为0-M字节
修饰符
所有类型:
• NULL 数据列可包含NULL值
• NOT NULL 数据列不允许包含NULL值
• DEFAULT 默认值 • PRIMARY KEY 主键
• UNIQUE KEY 唯一键
• CHARACTER SET name 指定一个字符集 数值型
• AUTO_INCREMENT 自动递增,适用于整数类型 (数字自动增长不需要手动在添加了)
• UNSIGNED 无符号
4 .对表进行添加信息,删除信息,等操作
1 . 向表里添加记录;
insert students values(1,’bai’,’beijing’,’m’,’100233′);
字符要加引号。
添加后的表:select * from students (*代表查看表里的所有的内容)
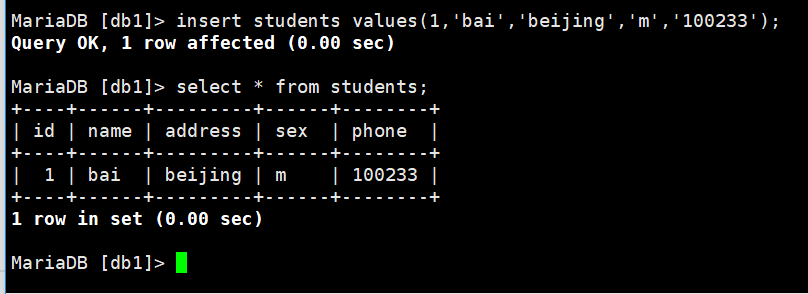
另一种方式添加记录:
insert students(id,name) values(2,’wang’);对指定的某个字段进行添加,字段和要赋值的内容要相对应。
其他没有指定的字段内容默认为null
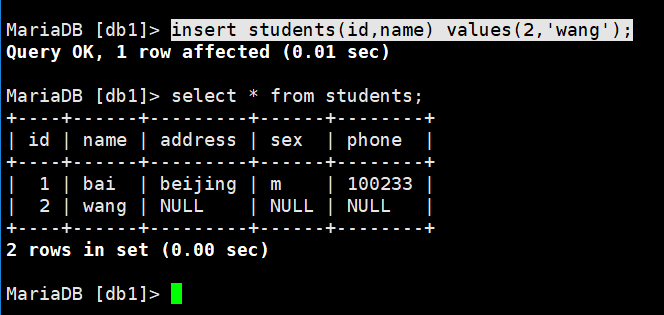
也可同时添加多行记录:
insert students values(3,’li’,’shanghai’,’f’,’100010′),(4,’zhang’,’hefei’,’f’,’121212′);
最后一种批量将旧表中的某些数据插入到新表的指定的字段当中:
insert emp(name,adress) select user,host from user2;
emp为新表,user2为所查的表。将user2表的两项内容,user和host赋值到要插入表emp的name和user2两个字段中。
2 . update; 更改表里的某行记录的某一个字段:
update students set sex=’m’,phone=’44444′ where id=2;
where id=2 (修改的指定范围;既将id=2的哪一行的两个字段更改掉)
如果where不写系统会默认更改,所有行的sex和phone的字段。
如果where查询的字段有多个相同的,但只想更改其中的两个可以增加限制,但此限制只能按顺序选定,
update student set sex=’m’ where sex=’f’ limit2; (按顺序只更改前两个后面的满足条件也不更改了)
3 . 对表里的内容进行删除:
truncate table students (快速删除整个表,且不可恢复)
delete from students where id=4; (删除id=4的哪一行)
delete from students;如果不写where限定条件,默认会删除此表的所有内容,如果在配置文件里面添加
vim /etc/my.cnf.d/mysql-clients.cnf
[mysql]
safe-updates
添加此行内容就不会删除所有的内容了。
5 .SELECT (搜索查询)
select * from students where sex=’m’;(查询表里的所有字段,限定条件为,sex=m)
select id,name from students where sex=’m’; (查看表里的某些特定的字段,限定条件为sex=m)
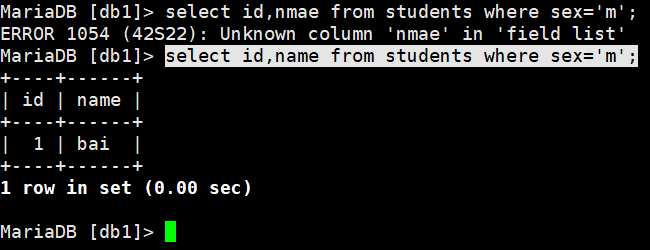
限定条件可以加多个:
select * from students where sex=’m’ and id=2
WHERE子句:
指明过滤条件以实现“选择”的功能:
过滤条件:布尔型表达式 算术操作符:+, -, *, /, % 比较操作符:=, !=, <>, <=>, >, >=, <, <=
BETWEEN min_num AND max_num (在两者之间)select * from students where id between 2 and 4 ;
IN (element1, element2, …) select * from students where sex in (‘f’,’m’,null);
IS NULL (表示的为空,查找是遇到null的不能写=号只能用is)
select * from students where sex is null;
IS NOT NULL (表示的为非空,查找是也不能用=号只能用is)
select * from students where sex is not null;
逻辑操作符:
NOT (取反)
AND (并且)
OR (或者)
XOR (异或)
select * from students where id>2; (查找id号大于2的行)
select * from students where not id>2;(id>2并取反,即是查找id<=2的行)
模糊搜索查询:
LIKE:
%: 任意长度的任意字符
_:任意一个个字符
select * from students where name like ‘%w%’ (name字段包含有w的)
字段显示可以使用别名
格式;字段名as字段的别名 (前面为字段的名称后面为定义的别名,只是用于显示)
select name as 姓名,sex as 性别 from students where sex is not null;
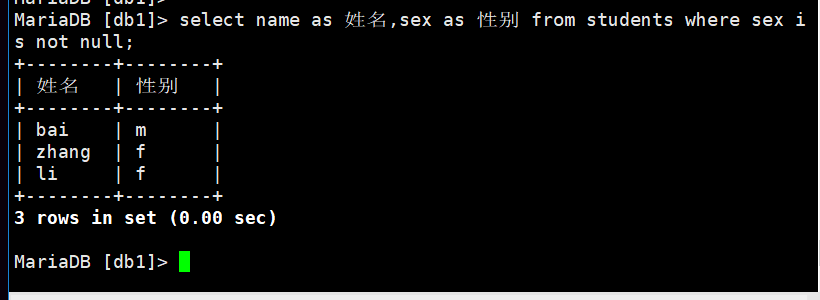
6 .分组:
GROUP:根据指定的条件把查询结果进行“分组”以用于做“聚合”运算
avg(), max(), min(), count(), sum() (平均值;最大值;最小值;组里成员的个数;总和;)
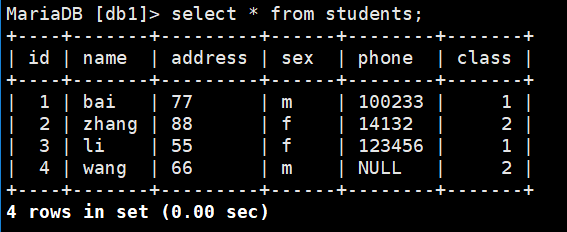
下面是此表的内容:

select sex from students group by sex; (一旦做分组前后的sex应该是相互关连的,不能随便写了)
select sex,max(address) from students group by sex; (以性别为分组统计address中的最大值)
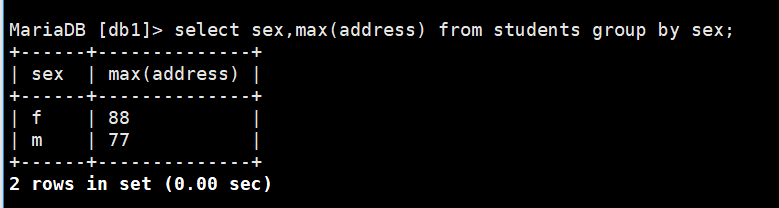
max(address) 把max换成avg统计以性别为分组的平均成绩;换成sum 为男女组的总成绩;等等;
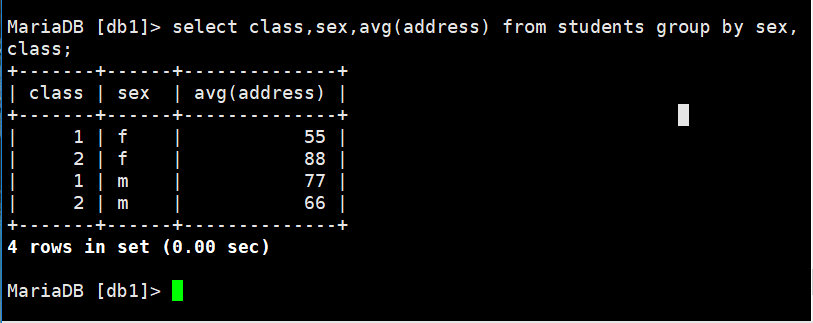
统计上图中一班和二班男女生的平均成绩:
select class,sex,avg(address) from students group by sex,class; (group分组根据多个条件)
统计效果如下图所示:
HAVING: 对分组聚合运算后的结果指定的限定条件 :
select sex,class,avg(address) from students group by class,sex having avg(address) > 80;(一班和二班男女生的平均成绩:并加限定条件,大于80分的,此处的限定条件就不能用where了,语法要求在分组后加限定条件只能用having )
ORDER BY: 根据指定的字段对查询结果进行排序
升序:ASC
降序:DESC
select * from students order by age asc; (对表中对其age组进行升序排列)
select * from students order by age desc;(对表中对其age组进行降序排列)
select sex,class,avg(address) from students group by class,sex asc; (分组时可以如此使用升序排列)
select sex,class,avg(address) from students group by class,sex desc; (分组时可以如此使用降序排列)
小结:如果有null的想要将其排在最后:可以在分的组名上添加—
例如:select sex,class,avg(address) from students group by -sex desc ;(此实例中只按性别进行分组)
7 .多表查询 (多个表关连进行查询)
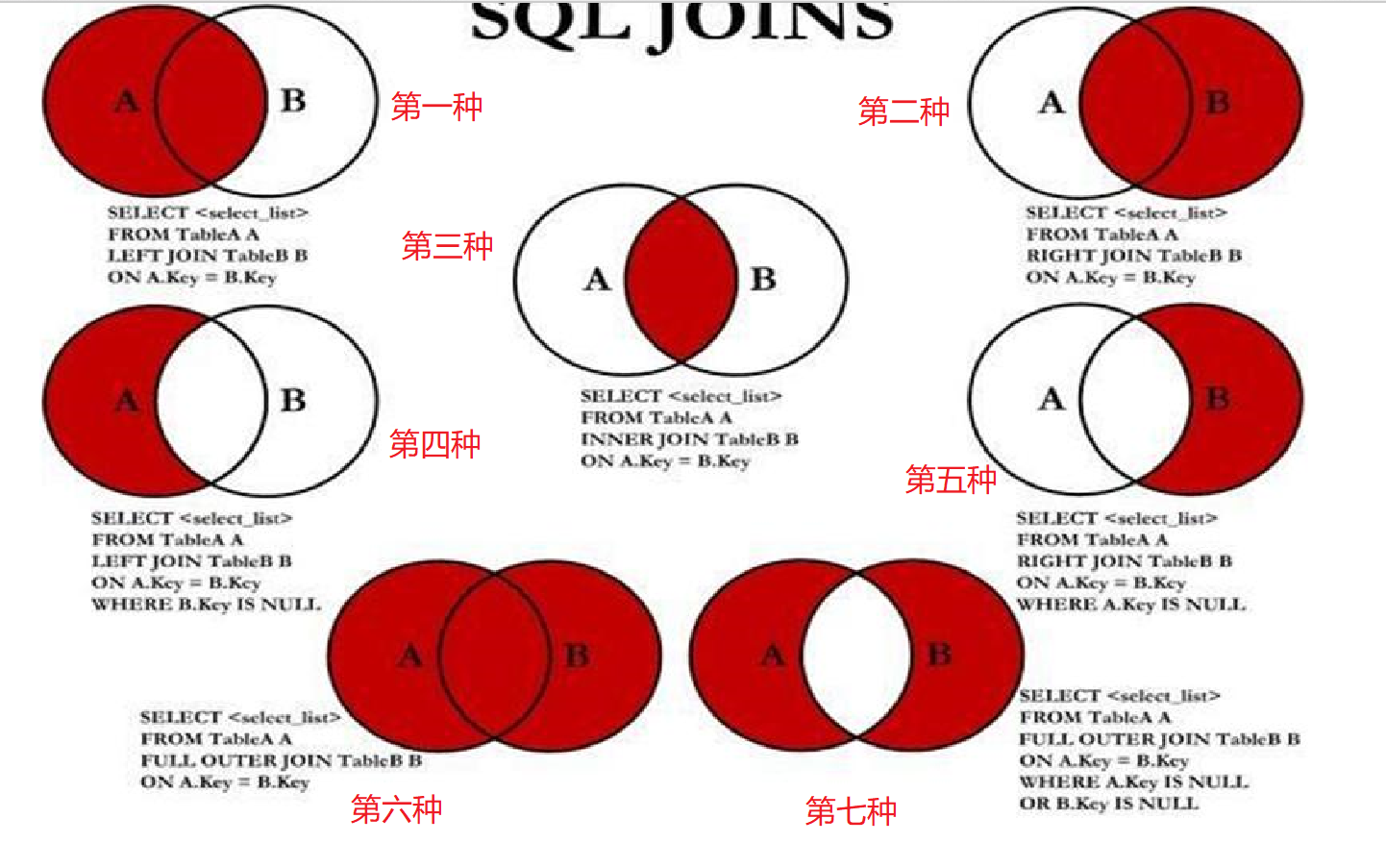
上图为多表联系的7中结构:
如何将写的数据库程序导入到mysql表中:
第一种方法:mysql < /hellodb_innodb.sql (没有进入数据库前)
第二种方法:source hellodb_innodb.sql (在进入数据库后)
上图中的结构分析:
第三种为:内连接
select s.name,t.name from students as s,teachers as t where s.teacherid=t.tid; (取交集老旧的写法)
(s.name中,s为后面students的别名,组和使用为了确保它是students的name的字段的唯一性,以免其他表中有相同的字段,t.name也是此意思;where后面的限制条件为:students表中的teacherid=teachers表中的tid;要显示的内容为:students表中的name和teachers表中的tid)
现在一般采用较新的写法:
select s.name as student_name,t.name as teacher_nameb from students as s inner join teachers as t on s.teacherid=t.tid;
用inner join …on 代替where;
其中inner join前面是一个表后面是一个表然后在on后面添加条件。
inner join 可以取多个表的交集 ;
例如:表A inner join 表B on 条件1 inner join 表C on 条件2 ;(等依次类推)
(将A和B先查询后在和C进行内连接的查询)
select * from students cross join teachers;(笛卡尔乘积):两张表的记录完全组和一遍类似于{1,2,3}{4,5,,6} (交叉组和各种可能)
子查询:(将一个查询的结果定义为一个限定的条件)
select * from students where age > (select avg(age) from students);(括号里的为查询平均年龄作为限定条件来使用)
第一种为;左外连接 (左边的全部都要,右边只要交集的部分;交集的部分按条件规则来取)
select s.name as student_name,t.name as teacher_name from students as s left outer join teachers as t on s.teacherid=t.tid; (此为左边的表全部留下来) (右边的表只留交集)
第二种为:右外连接(右边的全部都要,左边的只要交集)
select s.name as student_name,t.name as teacher_name from students as s right outer join teachers as t on s.teacherid=t.tid; (此为左边表只要交集) (此为表的右边全部都要)
第四种为:左内连接
第五种为;右内连接
第六种为:
第七种为:
练习 (单表查询的)
导入hellodb.sql生成数据库
两种方法:
第一种:mysql < /hellodb_innodb.sql (没有进入数据库前)
第二种:source hellodb_innodb.sql (在进入数据库后)
(1) 在students表中,查询年龄大于25岁,且为男性的同学的名字和年龄
select name,age from students where age>25 and gender=’m’;
select name,age from students where age>25 and gender=’m’ order by age; (对查询的结果在进行年龄的排序)
(2) 以ClassID为分组依据,显示每组的平均年龄
select avg(age),classid from students group by classid ;
(3) 显示第2题中平均年龄大于30的分组及平均年龄
elect avg(age),classid from students group by classid having avg(age) > 30;
(group分组时如果需要添加限定条件只能用having )
(4) 显示以L开头的名字的同学的信息
select * from students where name like ‘l%’;
(5) 显示TeacherID非空的同学的相关信息
select * from students where teacherid is not null;
(当遇到null时必须使用is 不能用=号了)
select * from students where not teacherid is null; (反向使用也是可以的)
(6) 以年龄排序后,显示年龄最大的前10位同学的信息
select * from students order by age desc limit 10;
(先反向排序后在限定只查找前十位的信息)
(7) 查询年龄大于等于20岁,小于等于25岁的同学的信息
select * from students where age>20 and age<=25;
(并且的限定条件用and)
小结:对于select搜索查询;题目要得到的显示结果应该写在select……….from students 之间;
搜所的限定条件写在where 后面;做题的思路如是;
练习:(多表查询)
导入hellodb.sql,以下操作在students表上执行
1、以ClassID分组,显示每班的同学的人数
select count(classid) as sum ,classid from students group by classid;
(as后面为定义的别名)
2、以Gender分组,显示其年龄之和
select sum(age),gender from students group by gender;
3、以ClassID分组,显示其平均年龄大于25的班级
elect avg(age) as ping,classid from students group by classid having ping > 25 and classid is not null;
4、以Gender分组,显示各组中年龄大于25的学员的年龄之和
select gender,sum(age) from (select * from students where age > 25) as t group by gender;
(第一次搜索的表作为第二次查询的表必须要添加别名,否则无法执行)
5、显示前5位同学的姓名、课程及成绩
select name,score,course from students as st inner join scores as sc inner join courses as co on st.stuid=sc.stuid and co.courseid=sc.courseid limit 10;
(因为每个名字都是重复的所以xuan)
6、显示其成绩高于80的同学的名称及课程;
select st.name as student_name,sc.score as score,course from students as st inner join scores as sc inner join courses as co on st.stuid=sc.stuid and co.courseid=sc.courseid and score > 80;
7、求前8位同学每位同学自己两门课的平均成绩,并按降序排列
8、显示每门课程课程名称及学习了这门课的同学的个数
9、如何显示其年龄大于平均年龄的同学的名字
10、如何显示其学习的课程为第1、2,4或第7门课的同学的名字
11、如何显示其成员数最少为3个的班级的同学中年龄大于同班同学平均年龄的同学
12、统计各班级中年龄大于全校同学平均年龄的同学
本文来自投稿,不代表Linux运维部落立场,如若转载,请注明出处:http://www.178linux.com/100509

