

1. B/S交互过程
浏览器(Browser)和服务器(Web Server)的交互过程:

1、 浏览器向服务器发出HTTP请求(Request)。
2、 服务器收到浏览器的请求数据,经过分析处理,向浏览器输出响应数据(Response)。
3、 浏览器收到服务器的响应数据,经过分析处理,将最终结果显示在浏览器中。
下图是一份浏览器请求数据和服务器响应数据的快照:

关于浏览器和服务器数据交互过程非常简单,很容易理解。我想从事Web开发的人员都很清楚,在此不再赘述,仅供参考。
2. Apache概述
Apache是目前世界上使用最为广泛的一种Web Server,它以跨平台、高效和稳定而闻名。按照去年官方统计的数据,Apache服务器的装机量占该市场60%以上的份额。尤其是在 X(Unix/Linux)平台上,Apache是最常见的选择。其它的Web Server产品,比如IIS,只能运行在Windows平台上,是基于微软.Net架构技术的不二选择。
Apache并不是没有缺点,它最为诟病的一点就是变得越来越重,被普遍认为是重量级的 WebServer。所以,近年来又涌现出了很多轻量级的替代产品,比如lighttpd,nginx等等,这些WebServer的优点是运行效率很 高,但缺点也很明显,成熟度往往要低于Apache,通常只能用于某些特定场合,。
3. Apache组件逻辑图
Apache是基于模块化设计的,总体上看起来代码的可读性高于php的代码,它的核心代码 并不多,大多数的功能都被分散到各个模块中,各个模块在系统启动的时候按需载入。你如果想要阅读Apache的源代码,建议你直接从main.c文件读 起,系统最主要的处理逻辑都包含在里面。MPM(Multi -Processing Modules,多重处理模块)是Apache的核心组件之 一,Apache通过MPM来使用操作系统的资源,对进程和线程池进行管理。Apache为了能够获得最好的运行性能,针对不同的平台 (Unix/Linux、Window)做了优化,为不同的平台提供了不同的MPM,用户可以根据实际情况进行选择,其中最常使用的MPM有 prefork和worker两种。至于您的服务器正以哪种方式运行,取决于安装Apache过程中指定的MPM编译参数,在X系统上默认的编译参数为 prefork。由于大多数的Unix都不支持真正的线程,所以采用了预派生子进程(prefork)方式,象Windows或者Solaris这些支持 线程的平台,基于多进程多线程混合的worker模式是一种不错的选择。对此感兴趣的同学可以阅读有关资料,此处不再多讲。Apache中还有一个重要的 组件就是APR(Apache portable Runtime Library),即Apache可移植运行库,它是一个对操作系统调用的抽象库,用来实现Apache内部组件对操作系统的使用,提高系统的可移植性。 Apache对于php的解析,就是通过众多Module中的php Module来完成的。

Apache的逻辑构成以及与操作系统的关系
4. Apache的生命周期
这一节的内容会与php模块的载入有关,您可以略微关注一下。以下是Apache的生命周期(prefork模式)示意图。

5. Apache的两种工作模式
Apache服务的两种工作模式:prefork和worker
prefork的工作原理及配置
1)工作原理: 一个单独的控制进程(父进程)负责产生子进程,这些子进程用于监听请求并作出应答。Apache总是试图保持一些备用的 (spare)或是空闲的子进程用于迎接即将到来的请求。这样客户端就无需在得到服务前等候子进程的产生。在Unix系统中,父进程通常以root身份运行以便邦定80端口,而 Apache产生的子进程通常以一个低特权的用户运行。User和Group指令用于配置子进程的低特权用户。运行子进程的用户必须要对他所服务的内容有读取的权限,但是对服务内容之外的其他资源必须拥有尽可能少的权限。 2) 配置说明:
如果不用“–with-mpm”显式指定某种MPM,prefork就是Unix平台上缺省的MPM。它所采用的预派生子进程方式也是Apache 1.3中采用的模式。prefork本身并没有使用到线程,2.0版使用它是为了与1.3版保持兼容性;另一方面,prefork用单独的子进程来处理不同的请求,进程之间是彼此独立的,这也使其成为最稳定的MPM之一。
若使用prefork,在make编译和make install安装后,使用“httpd -l”来确定当前使用的MPM,应该会看到prefork.c(如果看到worker.c说明使用的是worker MPM,依此类推)。再查看缺省生成的httpd.conf配置文件,里面包含如下配置段:
<IfModule prefork.c> StartServers 5 MinSpareServers 5 MaxSpareServers 10 MaxClients 150 MaxRequestsPerChild 0 </IfModule>
prefork的具体工作原理是,控制进程在最初建立“StartServers”个子进程后,为了满足MinSpareServers设置的需要创建一个进程,等待一秒钟,继续创建两个,再等待一秒钟,继续创建四个……如此按指数级增加创建的进程数,最多达到每秒32个,直到满足MinSpareServers设置的值为止。这就是预派生(prefork)的由来。这种模式可以不必在请求到来时再产生新的进程,从而减小了系统开销以增加性能。
当并发量请求数到达MaxClients(如256)时,而空闲进程只有10个。apache为继续增加创建进程。直到进程数到达256个。
当并发量高峰期过去了,并发请求数可能只有一个时,apache逐渐删除进程,直到进程数到达MaxSpareServers为止。
StartServers:指定服务器启动时建立的子进程数量,prefork默认为5。
MinSpareServers :指定空闲子进程的最小数量,默认为5。假如当前空闲子进程数少于MinSpareServers ,那么Apache将以最大每秒一个的速度产生新的子进程。此参数不要设的太大。
MaxSpareServers:设置了最大的空闲进程数,默认为10。如果空闲进程数大于这个值,Apache父进程会自动kill掉一些多余子进程。这个值不要设得过大,但如果设的值比MinSpareServers小,Apache会自动把其调整为MinSpareServers+1。如果站点负载较大,可考虑同时加大MinSpareServers和MaxSpareServers。
MaxRequestsPerChild:设置的是每个子进程可处理的请求数。每个子进程在处理了“MaxRequestsPerChild”个请求后将自动销毁。0意味着无限,即子进程永不销毁。虽然缺省设为0可以使每个子进程处理更多的请求,但如果设成非零值也有两点重要的好处:
◆ 可防止意外的内存泄漏;
◆ 在服务器负载下降的时侯会自动减少子进程数。
因此,可根据服务器的负载来调整这个值。个人认为10000左右比较合适。
MaxClients:是这些指令中最为重要的一个,设定的是Apache可以同时处理的请求,是对Apache性能影响最大的参数。
其缺省值150是远远不够的,如果请求总数已达到这个值(可通过ps -ef|grep http|wc -l来确认),那么后面的请求就要排队,直到某个已处理请求完毕。这就是系统资源还剩下很多而HTTP访问却很慢的主要原因。系统管理员可以根据硬件配置和负载情况来动态调整这个值。
虽然理论上这个值越大,可以处理的请求就越多,但在Apache1.3默认的最大只能设置为256(这是个硬限制)。如果把这个值设为大于256,那么Apache将无法起动。事实上,256对于负载稍重的站点也是不够的。如果要加大这个值,必须在“configure”前手工修改的源代码树下的src/include/httpd.h中查找256,就会发现“#define HARD_SERVER_LIMIT 256”这行。把256改为要增大的值(如4000),然后重新编译Apache即可。
但在Apache 2.0中,新加入了ServerLimit指令,可以突破最大请求数为256的限制。 使得无须重编译Apache就可以加大MaxClients。下面是prefork配置段:
<IfModule prefork.c> ServerLimit 2000 StartServers 10 MinSpareServers 10 MaxSpareServers 15 MaxClients 1000 MaxRequestsPerChild 10000 </IfModule>
ServerLimit:上述配置中,ServerLimit的最大值是2000,对于大多数站点已经足够。如果一定要再加大这个数值,对位于源代码树下server/mpm/prefork/prefork.c中以下两行做相应修改即可:
#define DEFAULT_SERVER_LIMIT 256 #define MAX_SERVER_LIMIT 2000
此时必须 MaxClients ≤ ServerLimit ≤ 2000. 即prefork的默认并发量最大是2000。
ServerLimit 生效前提:必须放在其他指令的前面,同时要想改变这个硬限制必须完全停止服务器然后再启动服务器(直接重启是不行的)。
worker的工作原理及配置
工作原理:每个进程能够拥有的线程数量是固定的。服务器会根据负载情况增加或减少进程数量。一个单独的控制进程(父进程)负责子进程的建立。每个子进程能够建立ThreadsPerChild数量的服务线程和一个监听线程,该监听线程监听接入请求并将其传递给服务线程处理和应答。Apache总是试图维持一个备用(spare)或是空闲的服务线程池。这样,客户端无须等待新线程或新进程的建立即可得到处理。在Unix中,为了能够绑定80端口,父进程一般都是以root身份启动,随后,Apache以较低权限的用户建立子进程和线程。User和Group指令用于配置Apache子进程的权限。虽然子进程必须对其提供的内容拥有读权限,但应该尽可能给予他较少的特权。另外,除非使用了suexec ,否则,这些指令配置的权限将被CGI脚本所继承。
相对于prefork,worker是2.0 版中全新的支持多线程和多进程混合模型的MPM。由于使用线程来处理,所以可以处理相对海量的请求,而系统资源的开销要小于基于进程的服务器。但是,worker也使用了多进程,每个进程又生成多个线程,以获得基于进程服务器的稳定性。这种MPM的工作方式将是Apache 2.0的发展趋势。
在configure -with-mpm=worker后,进行make编译、make install安装。在缺省生成的httpd.conf中有以下配置段:
<IfModule worker.c> StartServers 2 MaxClients 150 MinSpareThreads 25 MaxSpareThreads 75 ThreadsPerChild 25 MaxRequestsPerChild 0 </IfModule>
worker的工作原理是:由主控制进程生成“StartServers”个子进程,每个子进程中包含固定的ThreadsPerChild线程数,各个线程独立地处理请求。同样,为了不在请求到来时再生成线程,MinSpareThreads和MaxSpareThreads设置了最少和最多的空闲线程数;而MaxClients设置了所有子进程中的线程总数。如果现有子进程中的线程总数不能满足负载,控制进程将派生新的子进程。
StartServers:服务器启动时建立的子进程数,默认值是"3"。
ServerLimit:服务器允许配置的进程数上限。这个指令和ThreadLimit结合使用配置了MaxClients最大允许配置的数值。任何在重启期间对这个指令的改变都将被忽略,但对MaxClients的修改却会生效。
MinSpareThreads :最小空闲线程数,默认值是"75"。这个MPM将基于整个服务器监控空闲线程数。假如服务器中总的空闲线程数太少,子进程将产生新的空闲线程。
MaxSpareThreads:配置最大空闲线程数。默认值是"250"。这个MPM将基于整个服务器监控空闲线程数。假如服 务器中总的空闲线程数太多,子进程将杀死多余的空闲线程。MaxSpareThreads的取值范围是有限制的。Apache将按照如下限制自动修正您配置的值:worker需要其大于等于MinSpareThreads加上ThreadsPerChild的和
MinSpareThreads和MaxSpareThreads这两个参数对Apache的性能影响并不大,可以按照实际情况相应调节。
ThreadLimit:每个子进程可配置的线程数上限。这个指令配置了每个子进程可配置的线程数ThreadsPerChild上限。任何在重启期间对这个指令的改变都将被忽略,但对ThreadsPerChild的修改却会生效。默认值是"64".
ThreadsPerChild:是worker MPM中与性能相关最密切的指令。ThreadsPerChild的最大缺省值是64。如果负载较大,64也是不够的。这时要显式使用ThreadLimit指令,它的最大缺省值是20000。上述两个值位于源码树server/mpm/worker/worker.c中的以下两行:
#define DEFAULT_THREAD_LIMIT 64 #define MAX_THREAD_LIMIT 20000
这两行对应着ThreadsPerChild和ThreadLimit的限制数。最好在configure之前就把64改成所希望的值。注意,不要把这两个值设得太高,超过系统的处理能力,从而因Apache不起动使系统很不稳定。
Worker模式下所能同时处理的请求总数是由子进程总数乘以ThreadsPerChild值决定的,应该大于等于MaxClients。如果负载很大,现有的子进程数不能满足时,控制进程会派生新的子进程。默认最大的子进程总数是16,加大时也需要显式声明ServerLimit(最大值是20000)。这两个值位于源码树server/mpm/worker/worker.c中的以下两行:
#define DEFAULT_SERVER_LIMIT 16 #define MAX_SERVER_LIMIT 20000
需要注意的是,如果显式声明了ServerLimit,那么它乘以ThreadsPerChild的值必须大于等于MaxClients,而且MaxClients必须是ThreadsPerChild的整数倍,否则Apache将会自动调节到一个相应值(可能是个非期望值)。下面是worker配置段:
<IfModule worker.c> StartServers 3 MaxClients 2000 ServerLimit 25 MinSpareThreads 50 MaxSpareThreads 200 ThreadLimit 200 ThreadsPerChild 100 MaxRequestsPerChild 0 </IfModule>
通过上面的叙述,可以了解到Apache 2.0中prefork和worker这两个重要MPM的工作原理,并可根据实际情况来配置Apache相关的核心参数,以获得最大的性能和稳定性。
MaxClients:允许同时伺服的最大接入请求数量(最大线程数量)。任何超过MaxClients限制的请求都将进入等候 队列。默认值是"400",16 (ServerLimit)乘以25(ThreadsPerChild)的结果。因此要增加MaxClients的时候,您必须同时增加 ServerLimit的值。
ThreadsPerChild:每个子进程建立的常驻的执行线程数。默认值是25。子进程在启动时建立这些线程后就不再建立新的线程了。
MaxRequestsPerChild:配置每个子进程在其生存期内允许伺服的最大请求数量。到达MaxRequestsPerChild的限制后,子进程将会结束。假如MaxRequestsPerChild为"0",子进程将永远不会结束。
将MaxRequestsPerChild配置成非零值有两个好处:
1.能够防止(偶然的)内存泄漏无限进行,从而耗尽内存。
2.给进程一个有限寿命,从而有助于当服务器负载减轻的时候减少活动进程的数量。
注意
对于KeepAlive链接,只有第一个请求会被计数。事实上,他改变了每个子进程限制最大链接数量的行为。
6.Apache的运行
Apache运行分为启动阶段和运行阶段。
5.1. 启动阶段
在启动阶段,Apache主要进行配置文件解析(例如http.conf以及Include指令设定的配置文件等)、模块加载(例如mod_php.so,mod_perl.so等)和系统资源初始化(例如日志文件、共享内存段等)工作。
在这个阶段,Apache为了获得系统资源最大的使用权限,将以特权用户root(X系统)或超级管理员administrator(Windows系统)完成启动。
Apache和“php处理机”的装配过程就是在这个阶段完成的。
“php处理机”就是负责解释和执行你的php代码的系统模块。这个名字是我特意创造的,目的是为了帮助你理解本节的内容,后面的章节还会给出更专业的名称。
你单独做过php的安装配置吗?
如果你做过类似的工作,下面的内容很容易理解;如果你没有做过,可以尝试安装一下,有助于加深你的理解。不过,我的文章向来深入浅出,我会尽量把这个过程讲得更浅显一些。其实php的安装非常简单,如果你很感兴趣的话,可以到网上随便搜一篇安装指南,按步骤照做就可以了。
把php最终集成到Apache系统中,还需要对Apache进行一些必要的设置。这里,我们就以php的mod_php5 SAPI运行模式为例进行讲解,至于SAPI这个概念后面我们还会详细讲解。
假定我们安装的版本是Apache2 和 Php5,那么需要编辑Apache的主配置文件http.conf,在其中加入下面的几行内容:
Unix/Linux环境下:
LoadModule php5_module modules/mod_php5.so
AddType application/x-httpd-php .php
注:其中modules/mod_php5.so 是X系统环境下mod_php5.so文件的安装位置。
Windows环境下:
LoadModule php5_module d:/php/php5apache2.dll
AddType application/x-httpd-php .php
注:其中d:/php/php5apache2.dll 是在Windows环境下php5apache2.dll文件的安装位置。
这两项配置就是告诉Apache Server,以后收到的Url用户请求,凡是以php作为后缀,就需要调用php5_module模块(mod_php5.so/ php5apache2.dll)进行处理。
这个过程可以参考以下的示意图:

Apache启动阶段的源码包含在server/main.c中,我整理了一下源码中的对应关系:

不熟悉unix/linux的同学可能会问so文件(mod_php5.so)是个什么样的文件?
unix/linux下,so后缀文件是一个DSO文件,DSO与windows系统下的dll是等价概念,都是把一堆函数封装在一个二进制文件中。调用它们的进程把它们装入内存后,会将其映射到自己的地址空间。
DSO全称为Dynamic Shared Object,即动态共享对象。DLL全称为Dynamic Link Library 即动态链接库。
Apache 服务器的体系结构的最大特点,就是高度模块化。如果你为了追求处理效率,可以把这些dso模块在apache编译的时候静态链入,这样会提高Apache 5%左右的处理性能。
5.2、运行阶段
5.2.1 运行阶段概述
在运行阶段,Apache主要工作是处理用户的服务请求。
在这个阶段,Apache放弃特权用户级别,使用普通权限,这主要是基于安全性的考虑,防止由于代码的缺陷引起的安全漏洞。象微软的IIS就曾遭受“红色代码(Code Red)”和“尼姆达(Nimda)”等恶意代码的溢出攻击。
2.2 运行阶段流程
Apache将请求处理循环分为11个阶段,依次是:Post-Read-Request,URI Translation,Header Parsing,Access Control,Authentication,Authorization,MIME Type Checking,FixUp,Response,Logging,CleanUp。

Apache Hook机制
Apache的Hook机制是指:Apache 允许模块(包括内部模块和外部模块,例如mod_php5.so,mod_perl.so等)将自定义的函数注入到请求处理循环中。换句话说,模块可以在 Apache的任何一个处理阶段中挂接(Hook)上自己的处理函数,从而参与Apache的请求处理过程。
mod_php5.so/ php5apache2.dll就是将所包含的自定义函数,通过Hook机制注入到Apache中,在Apache处理流程的各个阶段负责处理php请求。
关于Hook机制在Windows系统开发也经常遇到,在Windows开发既有系统级的钩子,又有应用级的钩子。常见的翻译软件(例如金山词霸等等)的 屏幕取词功能,大多数是通过安装系统级钩子函数完成的,将自定义函数替换gdi32.dll中的屏幕输出的绘制函数。
Apache请求处理循环详解
Apache请求处理循环的11个阶段都做了哪些事情呢?
1、Post-Read-Request阶段
在正常请求处理流程中,这是模块可以插入钩子的第一个阶段。对于那些想很早进入处理请求的模块来说,这个阶段可以被利用。
2、URI Translation阶段
Apache在本阶段的主要工作:将请求的URL映射到本地文件系统。模块可以在这阶段插入钩子,执行自己的映射逻辑。mod_alias就是利用这个阶段工作的。
3、Header Parsing阶段
Apache在本阶段的主要工作:检查请求的头部。由于模块可以在请求处理流程的任何一个点上执行检查请求头部的任务,因此这个钩子很少被使用。mod_setenvif就是利用这个阶段工作的。
4、Access Control阶段
Apache在本阶段的主要工作:根据配置文件检查是否允许访问请求的资源。Apache的标准逻辑实现了允许和拒绝指令。mod_authz_host就是利用这个阶段工作的。
5、Authentication阶段
Apache在本阶段的主要工作:按照配置文件设定的策略对用户进行认证,并设定用户名区域。模块可以在这阶段插入钩子,实现一个认证方法。
6、Authorization阶段
Apache在本阶段的主要工作:根据配置文件检查是否允许认证过的用户执行请求的操作。模块可以在这阶段插入钩子,实现一个用户权限管理的方法。
7、MIME Type Checking阶段
Apache在本阶段的主要工作:根据请求资源的MIME类型的相关规则,判定将要使用的内容处理函数。标准模块mod_negotiation和mod_mime实现了这个钩子。
8、FixUp阶段
这是一个通用的阶段,允许模块在内容生成器之前,运行任何必要的处理流程。和Post_Read_Request类似,这是一个能够捕获任何信息的钩子,也是最常使用的钩子。
9、Response阶段
Apache在本阶段的主要工作:生成返回客户端的内容,负责给客户端发送一个恰当的回复。这个阶段是整个处理流程的核心部分。
10、Logging阶段
Apache在本阶段的主要工作:在回复已经发送给客户端之后记录事务。模块可能修改或者替换Apache的标准日志记录。
11、CleanUp阶段
Apache在本阶段的主要工作:清理本次请求事务处理完成之后遗留的环境,比如文件、目录的处理或者Socket的关闭等等,这是Apache一次请求处理的最后一个阶段。
模块的注入Apache的过程可以参考源码中server/core.c文件: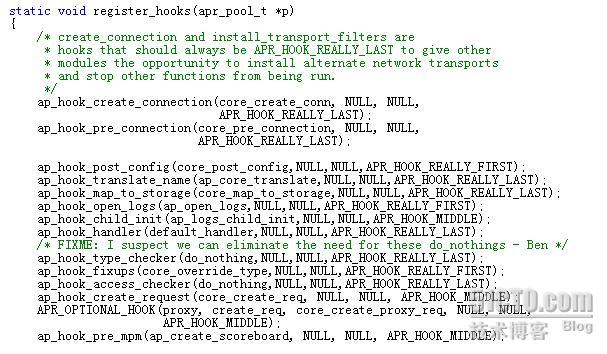
mod_php5.so/ php5apache2.dll注入到Apache的函数中,最重要的就是Response阶段的处理函数。
6. Apache的性能调优
假如apache的配置
<IfModule prefork.c>
StartServers 8
MinSpareServers 5
MaxSpareServers 20
MaxClients 256
MaxRequestsPerChild 4000
</IfModule>
在没有启用serverlLimit的情况下,使用ab测试:
ab -n 10000 -c 1000 http://192.168.1.191/test.php

如果继续保持同样的并发量继续测试(测试完后马上继续测试),由于apache的大部分子进程还没有被kill掉,创建子进程的时间就是少了,即有部分子进程已经预派生出来了。即n=20000(ab -n 20000-c 1000 http://192.168.1.191/test.php)时,时间应该不是137 *2 = 274S.
如果过一段时间在测试,即等apache kill进程,直到进程数等于MaxSpareServers (20)再测试,时间还是差不多的(137s左右)。
如果n=40000(ab -n 40000 -c 1000 http://192.168.1.191/test.php)观察服务器 apache的进程数:ps -ef | grep httpd | wc -l 。当apache的进程数到达256个后不再增加。
如果配置serverLimit
<IfModule prefork.c>
serverLimit 1000
StartServers 8
MinSpareServers 5
MaxSpareServers 20
MaxClients 1000
MaxRequestsPerChild 4000
</IfModule>
apache的进程就可以突破256的限制了。
调优设置:
1)如果服务器只是的某个时段的并发量很多,设置serverLimit ,并修改MaxClients 。
2)如果服务器持续性地高负载,可考虑同时加大MinSpareServers和MaxSpareServers。
转自:http://blog.csdn.net/hguisu/article/details/7395181
原创文章,作者:s19930811,如若转载,请注明出处:http://www.178linux.com/3047

