

一. MariaDB or MySQL基础知识
层次模型 –> 网状模型 –> (Codd) 关系模型
DBMS –> RDBMS
RDBMS:
范式:第一范式、第二范式、第三范式;
表:row, column;
关系运算:
选择
投影
数据库:表、索引、视图(虚表)、SQL、存储过程、存储函数、触发器、事件调度器;
DDL:CREATE,ALTER,DROP
DML:INSERT/UPDATE/DELETE/SELECT
约束:
主键约束:惟一、非空;一张表只能有一个;
惟一键约束:惟一,可以存在多个;
外键约束:参考性约束;
检查性约束:check;
三层模型:
物理层 –> SA
逻辑层 –> DBA
视图层 –> Coder
实现:
Oracle, DB2, Sybase, Infomix, SQL Server;
MySQL, MariaDB, PostgreSQL, SQLite;
===========================================================
二. MySQL
1. 版本: 5.1 –> 5.5 –> 5.6 –> 5.7 –> 8.0
MariaDB:5.5.x –> 10.x
2. 特性:
插件式存储引擎
单进程多线程
3. 安装MySQL:
OS Vendor:rpm
MySQL:
source code:cmake
binary package:
i686, x86_64;
glibc VERSION
prepackage:rpm, deb
os, arch,
4. 服务端程序:
mysqld, mysqld_safe, mysqld_multi
客户端程序:
mysql, mysqldump, mysqlbinlog, mysqldmin, …
非客户端类程序:
myisamchk, myisampack, …
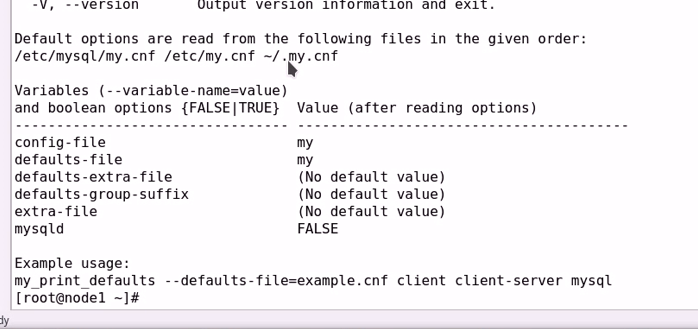
5. 配置文件:
读取多处的多个配置文件,而且会以指定的次序的进行;
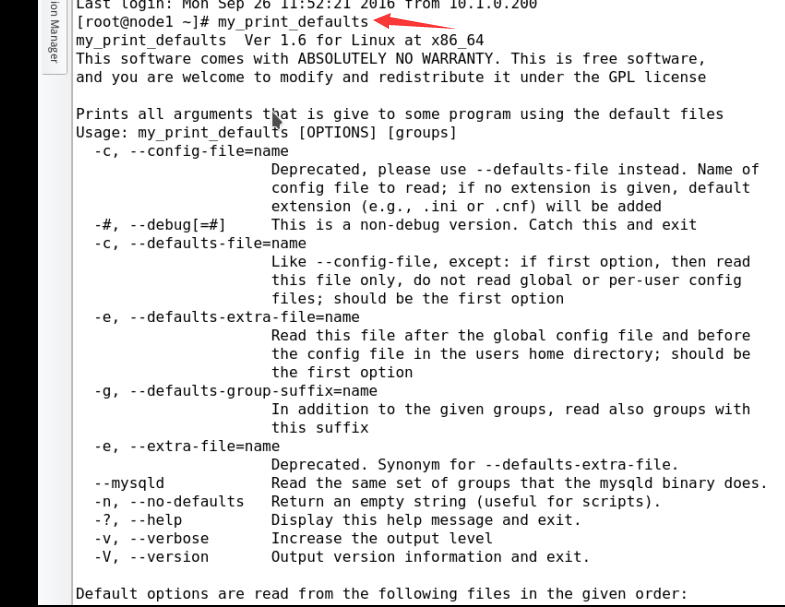
命令: my_print_defaults
#用于显示mysql 相关配置以及选项:
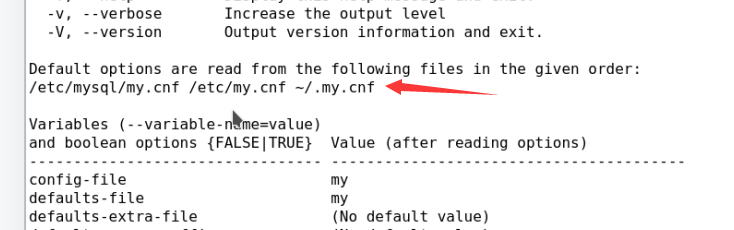
配置文件加载顺序: /etc/mysql/my.cnf /etc/my.cnf ~/.my.cnf
#Default options are read from the following files in the given order:
不同的配置文件中出现同一参数且拥有不同值时,后读取将为最终生效值;
修改默认读取的配置文件(mysqld_safe命令):
–defaults-file=file_name
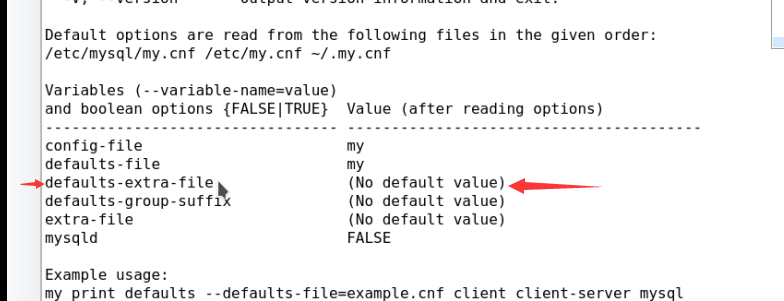
于读取的默认配置文件之外再加载一个文件:
–defaults-extra-file=path
6. 配置文件格式:ini风格的配置文件,能够为mysql的各种应用程序提供配置信息:
[mysqld]
[mysqld_safe]
[mysqld_multi]
[server]
[mysql]
[mysqldump]
[client]
…
PARAMETER = VALUE
PARAMETER:
innodb_file_per_table
innodb-file-per-table
7. 程序文件:
服务端程序:mysqld_safe, mysqld_multi
客户端程序:mysql, mysqldump, mysqladmin
工具程序:myisampack, …
====================================================
三. mysql 交互式CLI工具
( mysql –> mysql protocol –> mysqld )
1. mysql [options] db_name
常用选项:
–host=host_name, -h host_name:服务端地址;
–user=user_name, -u user_name:用户名;
–password[=password], -p[password]:用户密码;
–port=port_num, -P port_num:服务端端口;
–protocol={TCP|SOCKET|PIPE|MEMORY}:
本地通信:基于本地回环地址进行请求,将基于本地通信协议;
Linux:SOCKET
Windows:PIPE,MEMORY
非本地通信:使用非本地回环地址进行的请求; TCP协议;
–socket=path, -S path
–database=db_name, -D db_name:
–compress, -C:数据压缩传输
–execute=statement, -e statement:非交互模式执行SQL语句;
–vertical, -E:查询结果纵向显示;
2. 客户端以及服务端命令:
客户端命令:于客户端执行;
服务端命令:SQL语句,需要一次性完整地发往服务端,语句必须有结束符";"
? (\?) Synonym for `help'.
clear (\c) Clear the current input statement.
connect (\r) Reconnect to the server. Optional arguments are db
and host.
delimiter (\d) Set statement delimiter.
edit (\e) Edit command with $EDITOR.
ego (\G) Send command to mysql server, display result vertically.
exit (\q) Exit mysql. Same as quit.
go (\g) Send command to mysql server.
help (\h) Display this help.
nopager (\n) Disable pager, print to stdout.
notee (\t) Don't write into outfile.
pager (\P) Set PAGER [to_pager]. Print the query results via PAGER.
print (\p) Print current command.
prompt (\R) Change your mysql prompt.
quit (\q) Quit mysql.
rehash (\#) Rebuild completion hash.
source (\.) Execute an SQL script file. Takes a file name as an
argument.
status (\s) Get status information from the server.
system (\!) Execute a system shell command.
tee (\T) Set outfile [to_outfile]. Append everything into given
outfile.
use (\u) Use another database. Takes database name as
argument.
charset (\C) Switch to another charset. Might be needed for
processing binlog with multi-byte charsets.
warnings (\W) Show warnings after every statement.
nowarning (\w) Don't show warnings after every statement.
3. mysql命令的使用帮助:
# man mysql
# mysql –help –verbose
4. sql脚本运行:
mysql [options] [DATABASE] < /PATH/FROM/SOME_SQL_SCRIPT
=======================================================
四. mysqld服务器程序:工作特性的定义方式
1.
服务器参数/变量:设定MySQL的运行特性;
mysql> SHOW GLOBA|[SESSION] VARIABLES [LIKE clause];
状态(统计)参数/变量:保存MySQL运行中的统计数据或状态数据;
mysql> SHOW GLOBA|[SESSION] STATUS [LIKE clause];
#显示全局 | 会话级别的 状态信息;
eg:
SHOW GLOBA VARIABLES;
#显示全局变量
SHOW SESSION VARIABLES;
#显示会话级别的变量
—————————————————————————————–
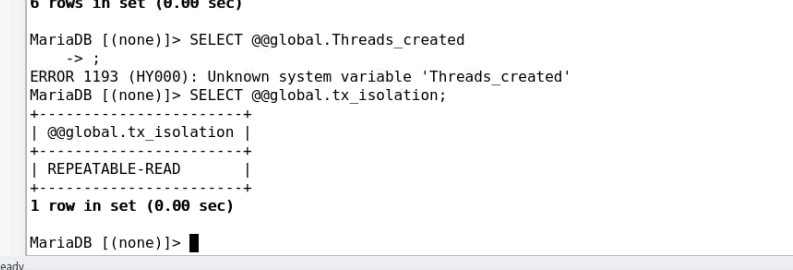
显示单个变量设定值的方法:
mysql> SELECT @@[global.|session.]system_var_name
%:匹配任意长度的任意字符;
_:匹配任意单个字符;
eg:
—————————————————————————————–
变量/参数级别:
全局:为所有会话设定默认;
会话:跟单个会话相关;会话建立会从全局继承;
—————————————————————————————–
服务器变量的调整方式:
运行时修改:
global:仅对修改后新建立的会话有效;
#且仅有拥有全局权限(管理权限)的用户才能修改;
session:仅对当前会话有效,且立即生效;
—————————————————————————————–
启动前通过配置文件修改:
重启后生效;
注意: 强烈建议在启动前修改对应参数, 部分值,是在数据库初始化时候生效,
若启用后再修改,可能会发生错误
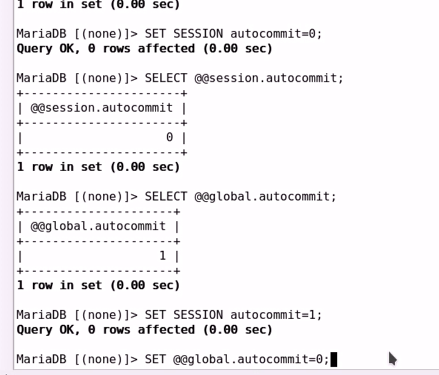
2 . 运行时修改变量值操作方法:
mysql> HELP SET
SET [GLOBAL | SESSION] system_var_name = expr
SET [@@global. | @@session. | @@]system_var_name = expr
注意: 仅对新创建的会话有效,对当前会话无效
eg:
3. 安装完成后的安全初始化:
mysql_secure_installation
4. 运行前常修改的参数:
innodb_file_per_table=ON
#每个表都使用独立的文件存放
skip_name_resolve=ON
#跳过名字解析,防止名字反解的时候无法实现而报错
========================================================
五. MySQL的数据类型:
1. 数据类型:
字符型
数值型
日期时间型
内建类型
2. 字符型:
CHAR(#), BINARY:定长型;CHAR不区分字符大小写,而BINARY区分;
VARCHAR(#), VARBINARY:变长型
TEXT:TINYTEXT,TEXT,MEDIUMTEXT,LONGTEXT
BLOB:TINYBLOB,BLOB,MEDIUMBLOB, LONGBLOB
3. 数值型:
浮点型:近似
FLOAT
DOUBLE
REAL
BIT
4.整型:精确
INTEGER:TINYINT,SMALLINT,MEDIUMINT,INT,BIGINT
DECIMAL
5. 日期时间型:
日期:DATE
时间:TIME
日期j时间:DATETIME
时间戳:TIMESTAMP
年份:YEAR(2), YEAR(4)
6. 内建:
ENUM:枚举
ENUM('Sun','Mon','Tue','Wed')
SET:集合
7. 类型修饰符:
字符型:NOT NULL,NULL,DEFALUT ‘STRING’,CHARACET SET
‘CHARSET’,COLLATION ‘collocation'
整型:NOT NULL, NULL, DEFALUT value, AUTO_INCREMENT,
UNSIGNED
日期时间型:NOT NULL, NULL, DEFAULT
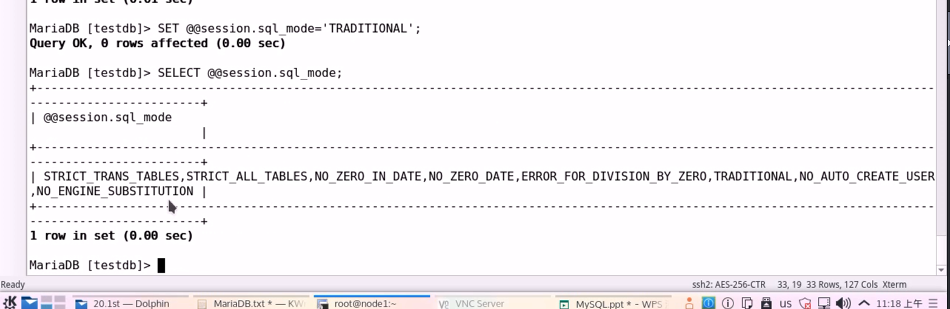
8. SQL MODE:定义mysqld对约束等违反时的响应行为等设定;
常用的MODE:
TRADITIONAL
#传统模式,当违反了数据定义规则,都不允许写入;
STRICT_TRANS_TABLES
#仅对事务型表严格限定;
STRICT_ALL_TABLES
#对所有表做严格限定;
9. 修改方式:
mysql> SET GLOBAL sql_mode='MODE';
mysql> SET @@global.sql_mode='MODE';
=========================================================
六. SQL:DDL,DML 语句
1). DDL:
mysql> HELP Data Definition
2. DDL 涉及命令:
CREATE, ALTER, DROP
DATABASE, TABLE
INDEX, VIEW, USER
FUNCTION, FUNCTION UDF, PROCEDURE, TABLESPACE, TRIGGER,
SERVER
3. 数据库操作:
CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] db_name CHARACTER
SET [=] charset_name COLLATE [=] collation_name
ALTER {DATABASE | SCHEMA} [db_name] CHARACTER SET [=]
charset_name COLLATE [=] collation_name
DROP {DATABASE | SCHEMA} [IF EXISTS] db_name
4. 表操作:
CREATE
(1) CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
(create_definition,…)
[table_options]
[partition_options]
CREATE TABLE [IF NOT EXISTS] tble_name (col_name
data_typ|INDEX|CONSTRAINT);
table_options:
ENGINE [=] engine_name
查看支持的所有存储引擎:
mysql> SHOW ENGINES;
查看指定表的存储引擎:
mysql> SHOW TABLE STATUS LIKE clause;
ROW_FORMAT [=]
{DEFAULT|DYNAMIC|FIXED|COMPRESSED|REDUNDANT|COMPACT}
(2) CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
[(create_definition,…)]
[table_options]
[partition_options]
select_statement
直接创建表,并将查询语句的结果插入到新创建的表中;
(3) CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
{ LIKE old_tbl_name | (LIKE old_tbl_name) }
复制某存在的表的结构来创建新的空表;
DROP:
DROP [TEMPORARY] TABLE [IF EXISTS] tbl_name [, tbl_name];
ALTER:
ALTER TABLE tbl_name
[alter_specification [, alter_specification] …]
可修改内容:
(1) table_options
(2) 添加定义:ADD
字段、字段集合、索引、约束
(3) 修改字段:
CHANGE [COLUMN] old_col_name new_col_name
column_definition [FIRST|AFTER col_name]
MODIFY [COLUMN] col_name column_definition
[FIRST | AFTER col_name]
(4) 删除操作:DROP
字段、索引、约束
表重命名:
RENAME [TO|AS] new_tbl_name
查看表结构定义:
DESC tbl_name;
查看表定义:
SHOW CREATE TABLE tbl_name
查看表属性信息:
SHOW TABLE STATUS [{FROM | IN} db_name] [LIKE
'pattern' | WHERE expr]
5. 索引:
创建:
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name [index_type]
ON tbl_name (index_col_name,…)
查看:
SHOW {INDEX | INDEXES | KEYS} {FROM | IN} tbl_name [{FROM | IN}
db_name] [WHERE expr]
删除:
DROP INDEX index_name ON tbl_name
索引类型:
聚集索引、非聚集索引:索引是否与数据存在一起;
主键索引、辅助索引
稠密索引、稀疏索引:是否索引了每一个数据项;
BTREE(B+)、HASH、R Tree、FULLTEXT
BTREE:左前缀;
EXPLAIN:分析查询语句的执行路径;
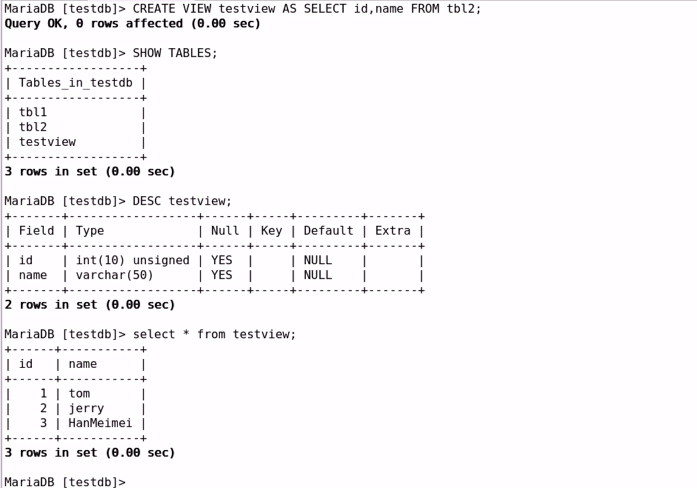
6. 视图:VIEW
虚表:存储下来的SELECT语句;
#即在基表(原表)的基础上,再创建一个临时的新表,将SELECT执行的结果保存
#到此表中
且,虚表时候可以修改,取决于基表中的剩余字段的约束部分;
示例:

创建:
CREATE VIEW view_name [(column_list)] AS select_statement
修改:
ALTER VIEW view_name [(column_list)] AS select_statement
删除:
DROP VIEW [IF EXISTS] view_name [, view_name] …
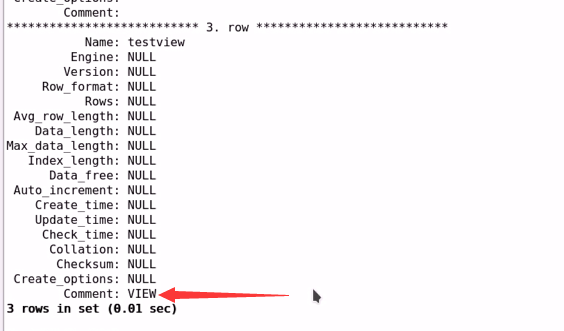
SHOW TABLES STATUS\G;
#可以查看表状态,并可以用于区分哪些是虚表;
======================================================
2). DML:
mysql> HELP Data Manipulation
1. 涉及命令:
INSERT/REPLACE, DELETE, SELECT, UPDATE
INSERT/REPLACE,DELETE,UPDATE,SELECT
2. INSERT:
单行插入
批量插入
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name [(col_name,…)]
{VALUES | VALUE} ({expr | DEFAULT},…),(…),…
[ ON DUPLICATE KEY UPDATE
col_name=expr
[, col_name=expr] … ]
Or:
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name
SET col_name={expr | DEFAULT}, …
[ ON DUPLICATE KEY UPDATE
col_name=expr
[, col_name=expr] … ]
Or:
INSERT [LOW_PRIORITY | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name [(col_name,…)]
SELECT …
[ ON DUPLICATE KEY UPDATE
col_name=expr
[, col_name=expr] … ]
3. DELETE:
DELETE FROM tbl_name [WHERE where_condition] [ORDER BY …] [LIMIT
row_count]
注意:一定要有限制条件,否则将清空整个表;
限制条件:
[WHERE where_condition]
[ORDER BY …] [LIMIT row_count]
4. UPDATE:
UPDATE table_reference SET col_name1={expr1|DEFAULT} [, col_name2=
{expr2|DEFAULT}] …
[WHERE where_condition]
[ORDER BY …]
[LIMIT row_count]
注意:一定要有限制条件,否则将修改整个表中指定字段的数据;
限制条件:
[WHERE where_condition]
[ORDER BY …] [LIMIT row_count]
注意:sql_safe_updates变量可阻止不带条件更新操作;
——————————————————————————————
3). SELECT:
(1) SELECT语句的执行流程:
FROM (找表)–> WHERE(子集) –> Group By(过滤分组,用于聚合) –> Having(描述
group by 的结果再过滤) –> Order BY(排序) –> SELECT(挑选字段) –> Limit (显示限定)
#先取行,再去字段;
(2) Query Cache:缓存查询的执行结果;
缓存的组织形式:
key:查询语句的hash值;
value:查询语句的执行结果;
SQL语句的编写方式:
SELECT name FROM tbl2;
select name from tbl2;
#mysql中,表名区分大小写,但是关键字不区分;
注意:这两种情况下,缓存时的hash值是不一样的,因此,需要严格限定sql语句的编写,
以提高缓存命中率;
查询执行路径:
请求–>查询缓存
请求–>查询缓存–>解析器–>预处理器–>优化器–>查询执行引擎–>存储引
擎–>缓存–>响应
(3) 单表查询:
SELECT
[ALL | DISTINCT | DISTINCTROW ]
[SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS]
select_expr [, select_expr …]
[FROM table_references
[WHERE where_condition]
[GROUP BY {col_name | expr | position}
[ASC | DESC], … [WITH ROLLUP]]
[HAVING where_condition]
[ORDER BY {col_name | expr | position}
[ASC | DESC], …]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
用法:
SELECT col1, col2, … FROM tble_name;
SELECT col1, col2, … FROM tble_name WHERE clause;
SELECT col1, col2, … FROM tble_name [WHERE clause] GROUP BY
col_name [HAVING clause];
#以指定字段分组,再做聚合;
DISTINCT:数据去重;
缓存相关:
SQL_CACHE:显式指定缓存查询语句的结果;
SQL_NO_CACHE:显式指定不缓存查询语句的结果;
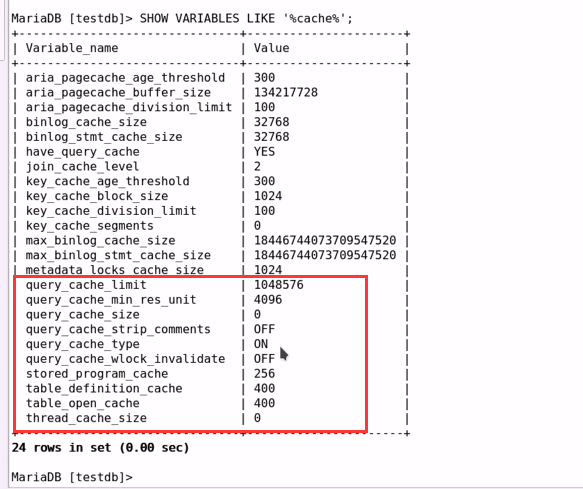
query_cache_type服务器变量有三个值:
ON:启用;
SQL_NO_CACHE:不缓存;默认符合缓存条件都缓存;
OFF:关闭;
DEMAND:按需缓存;
SQL_CACHE:缓存;默认不缓存;
字段可以使用别名 :
col1 AS alias1, col2 AS alias2, …
五种常用的聚合方法:
avg(), max(), min(), sum(), count()
WHERE子句:指明过滤条件以实现“选择”功能;
过滤条件:布尔型表达式;
[WHERE where_condition]
算术操作符:+, -, *, /, %
比较操作符:=, <>, !=, <=>, >, >=, <, <=
IS NULL, IS NOT NULL
区间:BETWEEN min AND max
IN:列表;
LIKE:模糊比较,%和_;
RLIKE或REGEXP
逻辑操作符:
AND, OR, NOT, XOR
GROUP BY:根据指定的字段把查询的结果进行“分组”以用于“聚合”运算;
avg(), max(), min(), sum(), count()
HAVING:对分组聚合后的结果进行条件过滤;
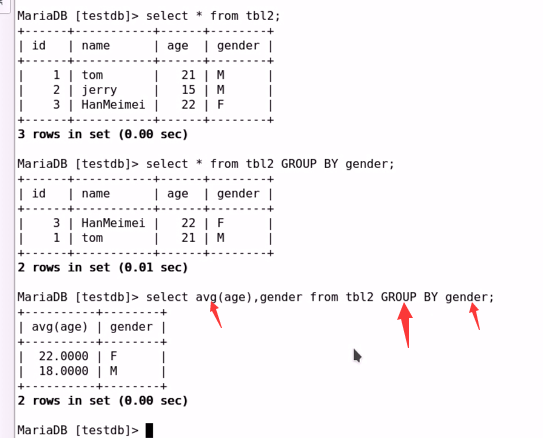
#基于gender对表进行分组,然后显示age的平均值,和gender 两个字段;
ORDER BY:根据指定的字段把查询的结果进行排序;
升序:ASC
降序:DESC
LIMIT:对输出结果进行数量限制
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
eg:
以年龄排序后,显示年龄最大的前10位同学的信息;
SELECT name,age FROM students ORDER BY age DESC LIMIT 10;
===================================================
(4.) 多表查询:
连接操作:
(a) 交叉连接:笛卡尔乘积;
(b) 内连接:略
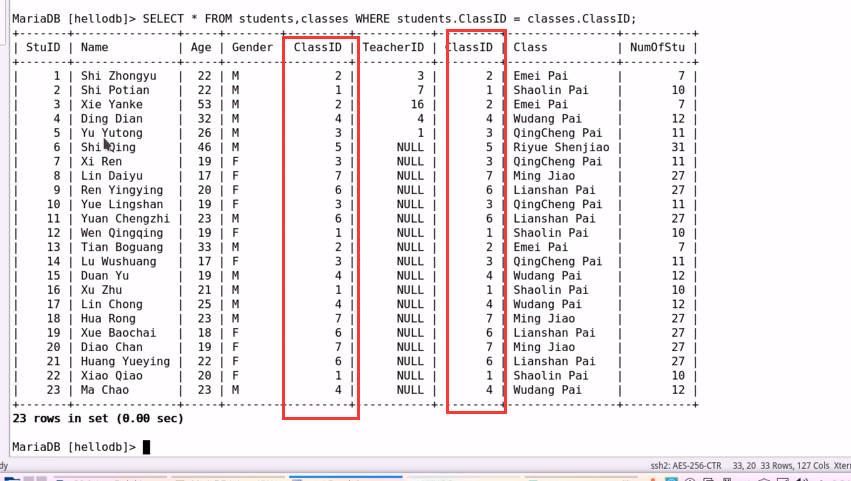
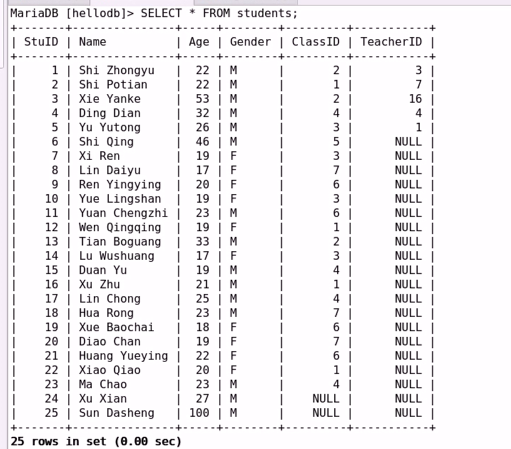
(c) 等值连接:让表之间的字段以等值的方式建立连接;
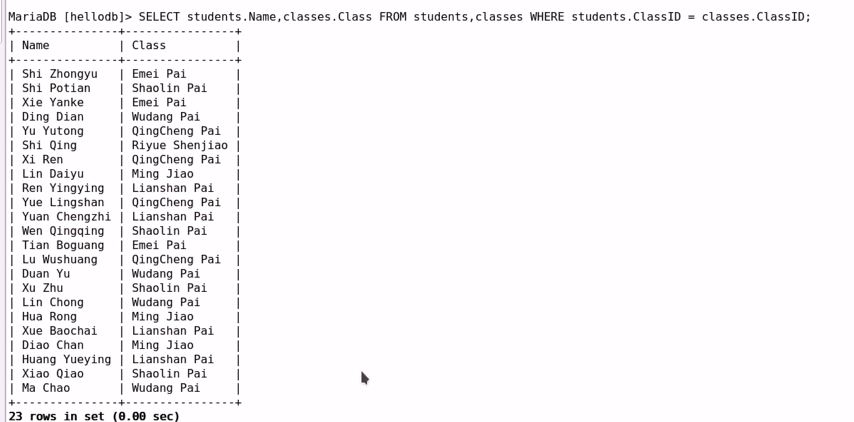
——————————————————————————–
(d) 不等值连接:略
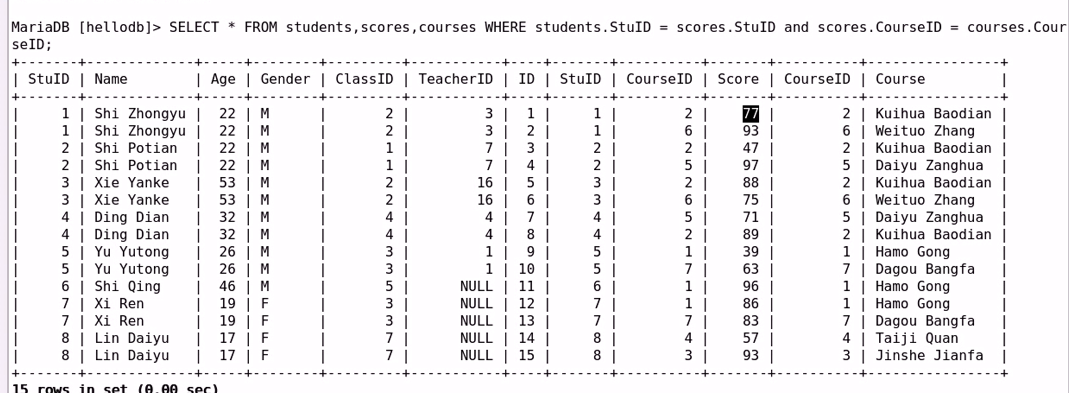
自然连接:
(e) 自连接:
#即引用自己表内的内容来创建一张新的表
示例:

#对基表中,teacherID 与基表中的 stuID 建立连接关系, teacherID的值作为键,值即为
#StuID对应的值
#例如: teacherID = 3 , 后面先连接stuID为3 的同学信息
————————————————————————————-
(f) 外连接:(即外键功能,仅innodb引擎支持)
左外连接:
FROM tb1 LEFT JOIN tb2 ON tb1.col = tb2.col
(以左表为准,左表有的信息,全部保留)
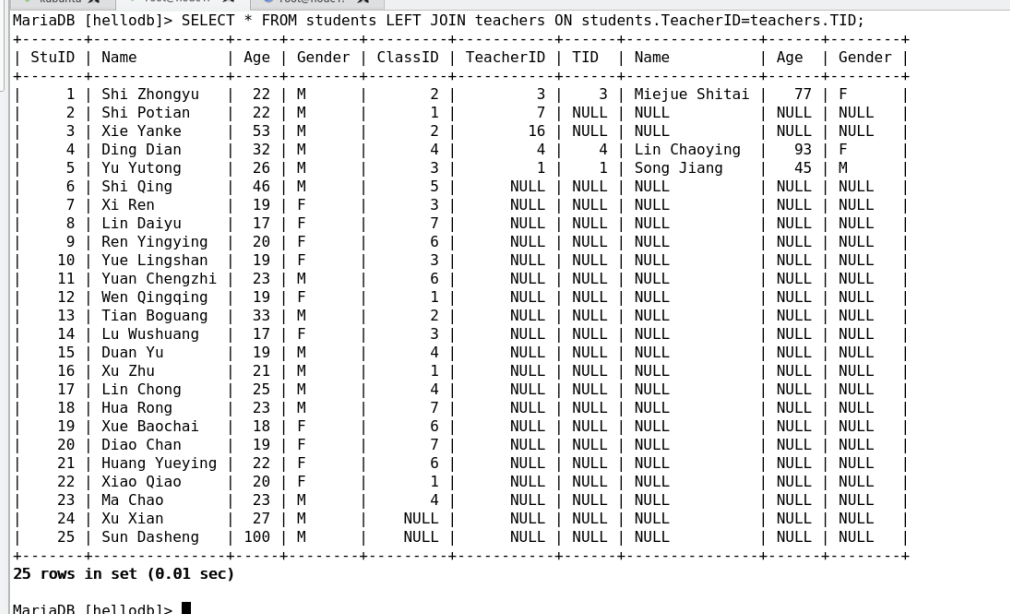
右外连接:
FROM tb1 RIGHT JOIN tb2 ON tb1.col = tb2.col
(以右表为准,右表有的信息,全部保留)

(6 ) 子查询:在查询中嵌套查询;
用于WHERE子句中的子查询;
(1) 用于比较表达式中的子查询:子查询仅能返回单个值;
(2) 用于IN中的子查询:子查询可以返回一个列表值;
(3) 用于EXISTS中的子查询:
示例:


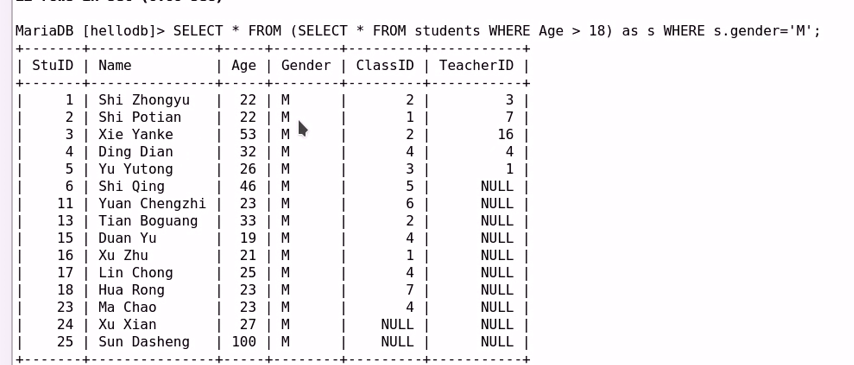
—————————————————-
用于FROM子句中的子查询;
SELECT tb_alias.col1, … FROM (SELECT clause) AS tb_alias WHERE
clause;
示例:
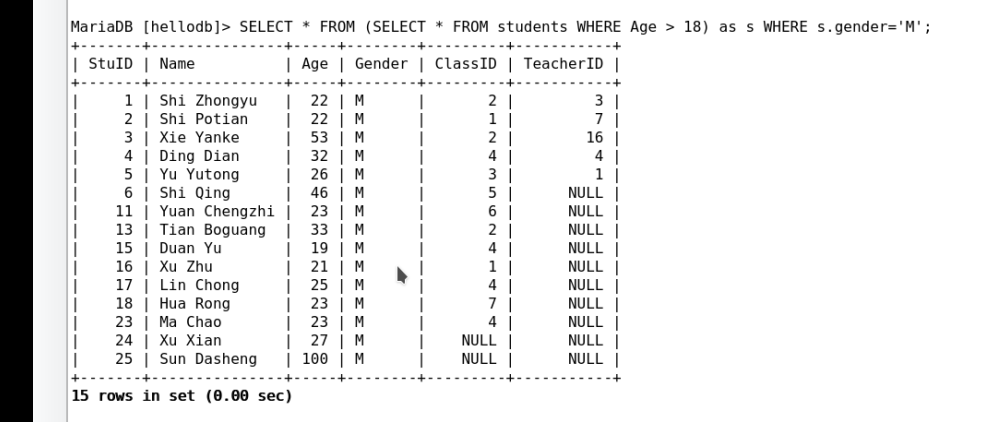
注意:此类型查询,性能不高,mysql中对此类子查询未充分优化过;
能用连接查询,尽可能勿用子查询
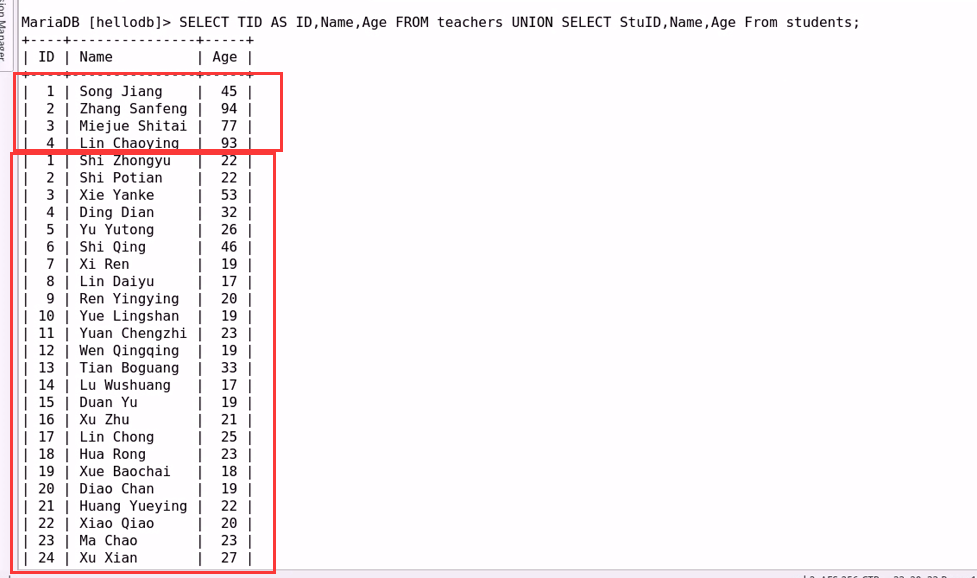
联合查询:将多个查询语句的执行结果相合并;
#多个表中,查询执行后,执行的结果非常相似,便可将多个查询的表,合成一个临时的新表
UNION
SELECT clause UNION SELECT cluase;
============================================================
七. 存储引擎
1. 表类型:表级别概念,不建议在同一个库中的表上使用不同的ENGINE;
创建表时,可以指明使用指定的存储引擎:
CREATE TABLE … ENGINE[=]STORAGE_ENGINE_NAME …
( 若不指明使用什么存储引擎,则使用默认引擎,)
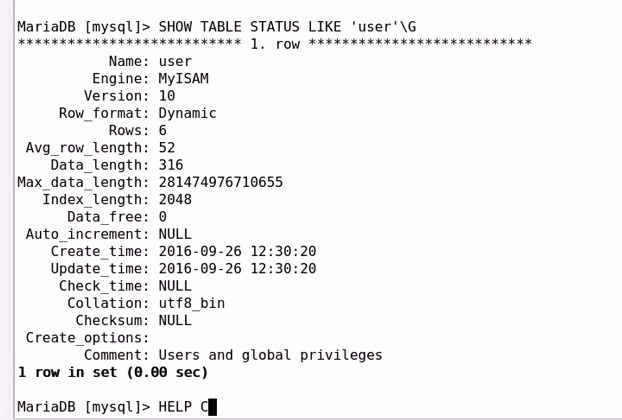
查看默认引擎:

查看表使用的引擎:
SHOW TABLE STATUS
查看指定搜索引擎的状态信息:
show engine innodb status;
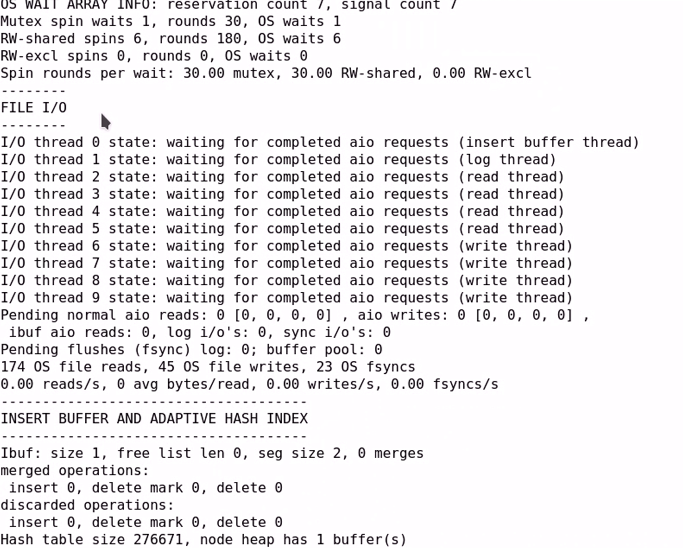
2. 常见的存储引擎:
MyISAM, Aria, InnoDB, MRG_MYISAM, CSV, BLACKHOLE, MEMORY,
PERFORMANCE_SCHEMA, ARCHIVE, FEDERATED
查看数据库支持的引擎:
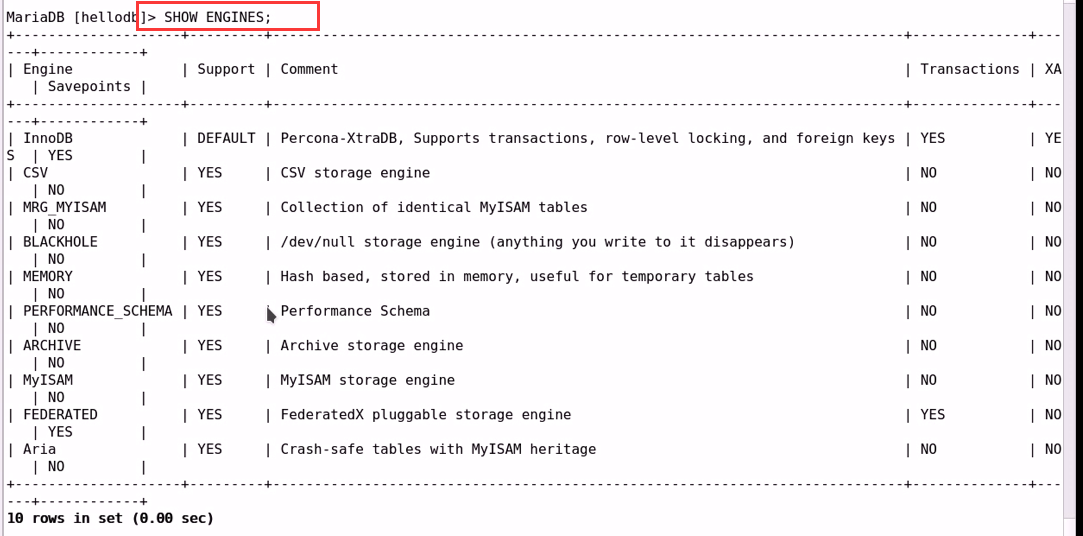
3 . InnoDB:InnoBase
Percona-XtraDB, Supports transactions, row-level locking, and foreign keys
三大特性: 行级锁
事务
外键
特性概述:
事务型存储引擎,适合对事务要求较高的场景中;但较适用于处理大量短期事务;
基于MVCC(Mutli Version Concurrency Control)支持高并发;
#基于快照功能实现,每个连接所操作的数据都是在修改前的一个瞬时快照,
然后在此基础上处理数据;
支持四个隔离级别,默认级别为REPEATABLE-READ;间隙锁以防止幻读;
使用聚集索引(数据与索引存放在一起,找到数据即可找到索引)(主键索引)
#即在btree索引中,在每个叶子节点处,聚集索引存放的是数据,
# 而非聚集索引在叶子节点上存放的是数据的存放地址;
支持”自适应Hash索引“(当使用等值搜索时,性能极好)
锁粒度:行级锁;间隙锁;
相关变量查看: show variables like '%innodb%'
数据存储:
#数据存储于“表空间(table space)"中:
#存储路径一般是mysql的工作目录,如/var/lib/mysql/
(1) 所有InnoDB表的数据和索引存储于同一个表空间中;
表空间文件:datadir定义的目录中
文件:ibdata1, ibdata2, …
(2) innodb_file_per_table=ON,意味着每表使用单独的表空间文件;
数据文件(数据和索引,存储于数据库目录): tbl_name.ibd
表结构的定义:在数据库目录,tbl_name.frm
示例:
创建表tbl3, 会产生表结构定义未见tbl3.frm 以及 表数据存放文件tbl3.ibd

buffer_pool 缓冲池: (此类为必调项目)
#可以用于缓冲表数据,元数据,以及索引数据
总结:
数据存储:表空间;
并发:MVCC,间隙锁,行级锁;
索引:聚集索引、辅助索引(索引中的值可以重复);
性能:预读操作、内存数据缓冲、内存索引缓存、自适应Hash索引、插入操作缓
存区;
备份:支持热备;
4. MyISAM:
部分特点::
支持全文索引(FULLTEXT index)、压缩、空间函数(GIS,空间索引);
不支持事务
锁粒度:表级锁
崩溃无法保证表安全恢复
适用场景:只读或读多写少的场景、较小的表(以保证崩溃后恢复的时间较短);
文件:每个表有三个文件,存储于数据库目录中
tbl_name.frm:表格式定义;
tbl_name.MYD:数据文件;
tbl_name.MYI:索引文件;
特性:
加锁和并发:表级锁;
修复:手动或自动修复、但可能会丢失数据;
索引:非聚集索引;
延迟索引更新;
表压缩;
行格式:
{DEFAULT|DYNAMIC|FIXED|COMPRESSED|REDUNDANT|COMPACT}
5. 其它的存储引擎:
CSV:将CSV文件(以逗号分隔字段的文本文件)作为MySQL表文件;
MRG_MYISAM:将多个MyISAM表合并成的虚拟表;
BLACKHOLE:类似于/dev/null,不真正存储数据;
MEMORY:内存存储引擎,支持hash索引,表级锁,常用于临时表;
FEDERATED: 用于访问其它远程MySQL服务器上表的存储引擎接口;
MariaDB额外支持很多种存储引擎:
OQGraph、SphinxSE、TokuDB、Cassandra、CONNECT、SQUENCE、…
可以使用show engine ; 查看支持的其他引擎:

6. 搜索引擎:
lucene, sphinx
lucene:Solr, Elasticsearch
=========================================================
八. 并发控制:
锁:Lock
锁类型 :
读锁:共享锁,可被多个读操作共享;
写锁:排它锁,独占锁;
锁粒度:
表锁:在表级别施加锁,并发性较低;
行锁:在行级另施加锁,并发性较高;
锁策略:在锁粒度及数据安全性之间寻求一种平衡机制;
存储引擎:级别以及何时施加或释放锁由存储引擎自行决定;
MySQL Server:表级别,可自行决定,也允许显式请求;
锁类别:
显式锁:用户手动请求的锁;
隐式锁:存储引擎自行根据需要施加的锁;
显式锁的使用:
(1) LOCK TABLES
LOCK TABLES tbl_name read|write, tbl_name read|write, …
#读锁中, 多个并发可以同时施加读锁,
#但是若有其他连接施加读锁,其他连接则无法再同时施加写锁
UNLOCK TABLES
#解除对应表的全部锁
(2) FLUSH TABLES
FLUSH TABLES tbl_name,… [WITH READ LOCK];
#将内存的指定表强行同步到磁盘,并关闭表
WITH READ LOCK: 将内存的指定表强行同步到磁盘,并关闭表
后再次以指定的锁打开
UNLOCK TABLES;
(3) SELECT cluase
[FOR UPDATE | LOCK IN SHARE MODE]
#锁定指定表中指定行的锁定操作
读写锁示例:
1. 对表施加读锁,并尝试写入操作:

在另一个连接中同时施加读锁(成功), 再尝试施加写锁(失败);
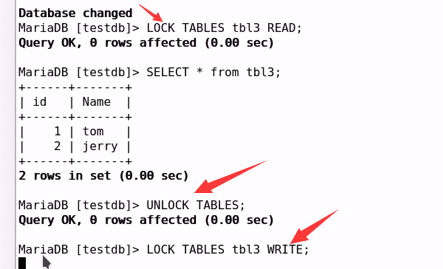
#被堵塞
堵塞时间:

============================================================
练习
导入hellodb.sql生成数据库
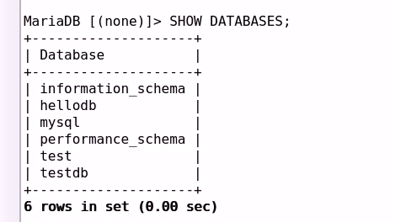
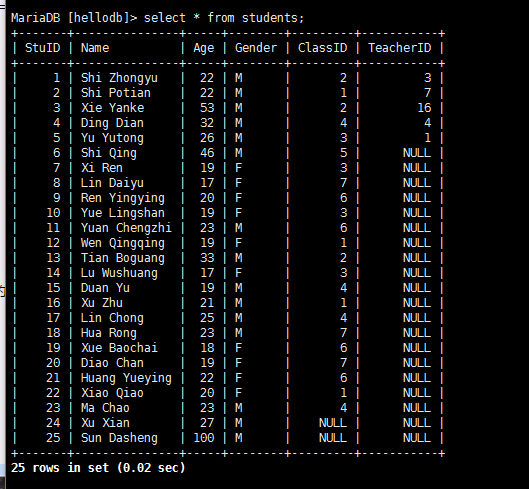
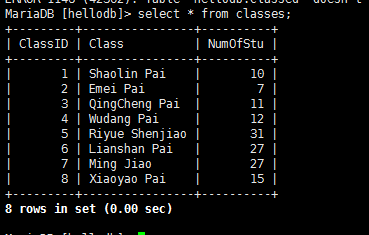
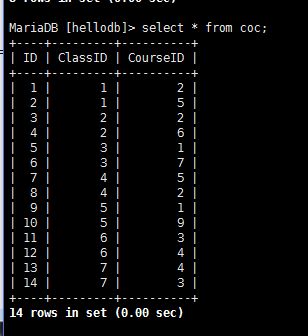
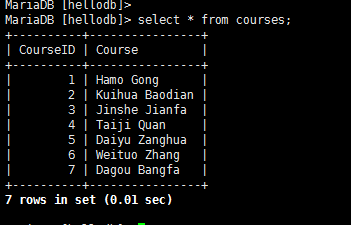
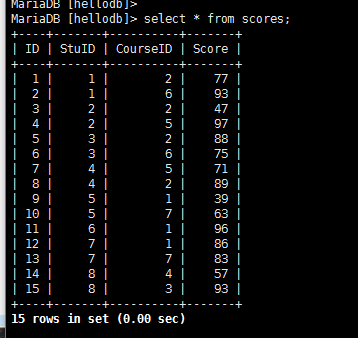
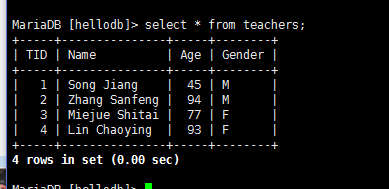
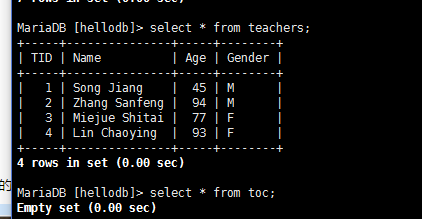
——————————————————————————–
单表查询:
(1) 在students表中,查询年龄大于25岁,且为男性的同学的名字和年龄;
SELECT name,age FROM students WHERE age>25 and gender="M";
(2) 以ClassID为分组依据,显示每组的平均年龄;
SELECT ClassID,avg(age) FORM students GROUP BY classID;
(3) 显示第2题中平均年龄大于30的分组及平均年龄;
SELECT ClassID,avg(age) FORM students GROUP BY classID Having
avg(age) > 30;
(4) 显示以L开头的名字的同学的信息;
SELECT * FROM students WHERE name RLIKE "^L .*$";
(5) 显示TeacherID非空的同学的相关信息;
SELETT name FROM students WHERE TeacherID IS NOT NULL;
(6) 以年龄排序后,显示年龄最大的前10位同学的信息;
SELECT name,age FROM students ORDER BY age DESC LIMIT 10;
(7) 查询年龄大于等于20岁,小于等于25岁的同学的信息;用三种方法;
SELECT name,age FROM students WHERE age in (20..25);
SELECT name,age FROM students WHERE age>=20 and age<=25;
==========================================================
练习:导入hellodb.sql,以下操作在students表上执行
1、以ClassID分组,显示每班的同学的人数;
SELECT ClassID,count(StuID) FROM students GROUP BY ClassID;
2、以Gender分组,显示其年龄之和;
SELECT Gender,sum(age) FROM students GROUP BY Gender;
3、以ClassID分组,显示其平均年龄大于25的班级;
SELECT ClassID,avg(age) FROM students GROUP BY ClassID Having
avg(age) > 25;
4、以Gender分组,显示各组中年龄大于25的学员的年龄之和;
SELECT Gender,sum(age) FROM students WHERE age > 25 GROUP
BY Gender;
———————————————————————————
多表查询:
练习:导入hellodb.sql,完成以下题目:
1、显示前5位同学的姓名、课程及成绩;
SELECT name,Course,scores FROM student,courses,scores WHERE
student.StuID = scores.StuID and scores.CourseID = courses.CourseID
2、显示其成绩高于80的同学的名称及课程;
SELECT name,course,score FROM student,course,scores WHERE student.StuID = scores.StuID and courses.CourseID = scores.CourseID and Score > 80;
3、求前8位同学每位同学自己两门课的平均成绩,并按降序排列;
SELECT name,avg(Score) (SELECT name,course,score FROM student,course,scores WHERE student.StuID = scores.StuID and courses.CourseID = scores.CourseID) GROUP BY NAME ORDER BY avg(Score) DESC LIMIT 8;
4、显示每门课程课程名称及学习了这门课的同学的个数;
SELECT course,count(StuID) FROM (SELECT course,count(StuID) FROM scores GROUP BY CourseID) as a,courses WHERE m.courseID = courses.CourseID;
思考:
1、如何显示其年龄大于平均年龄的同学的名字?
SELECT name,age FROM students WHERE age > (SELECT avg(age) FROM student);
2、如何显示其学习的课程为第1、2,4或第7门课的同学的名字?
SELECT name FROM students as a,course as b WHERE a.CourseID in (1,2,4,7) and b.CourseID = a.CourseID;
3、如何显示其成员数最少为3个的班级的同学中年龄大于同班同学平均年龄的同学?
SELECT name,age FROM (SELECT class,classID FROM students as s,classes as c WHERE s.ClassID GROUP BY CALSS having count(stuid) >= 3) as d,students as e,WHRER d.ClassID = e.ClassID and age > (SELECT avg(age) FROM students )
4、统计各班级中年龄大于全校同学平均年龄的同学。
SELECT name,age FROM students as a,classes as b WHERE a.classID = b.ClassID and age > (SELECT avg(age) FROM students);
============================================================
原创文章,作者:ldt195175108,如若转载,请注明出处:http://www.178linux.com/59974
