

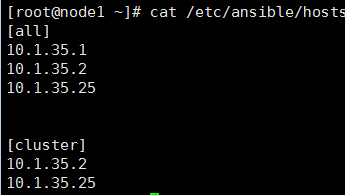
HA cluster应用——CoroSync v2 (quorum system)+Pacemaker (standalone daemon)+ crmsh/pcsh
corosync简述:Corosync是OpenAIS发展到Wilson版本后衍生出来的开放性集群引擎工程。可以说Corosync是OpenAIS工程的一部分。OpenAIS从openais0.90开始独立成两部分,一个是Corosync;另一个是AIS标准接口Wilson。Corosync包含OpenAIS的核心框架用来对Wilson的标准接口的使用、管理。它为商用的或开源性的集群提供集群执行框架。Corosync执行高可用应用程序的通信组系统,它有以下特征:(1)一个封闭的程序组(A closed process group communication model)通信模式,这个模式提供一种虚拟的同步方式来保证能够复制服务器的状态。(2)一个简单可用性管理组件(A simple availability manager),这个管理组件可以重新启动应用程序的进程当它失败后。(3)一个配置和内存数据的统计(A configuration and statistics in-memory database),内存数据能够被设置,回复,接受通知的更改信息。(4)一个定额的系统(A quorum system),定额完成或者丢失时通知应用程序。总结:Corosync是整合底层节点服务器,提供API个pacemaker的一个中间层
pacemaker简述:
pacemaker,是一个群集资源管理器。它实现最大可用性群集服务(亦称资源管理)的节点和资源级故障检测和恢复使用您的首选集群基础设施(OpenAIS的或Heaerbeat)提供的消息和成员能力。
它可以做乎任何规模的集群,并配备了一个强大的依赖模型,使管理员能够准确地表达群集资源之间的关系(包括顺序和位置)。几乎任何可以编写脚本,可以管理作为心脏起搏器集群的一部分。pacemaker支持超过16个节点的控制
(1)时间同步;建议自建一个时间同步服务器,如果使用外网的时间同步服务器,会增加网络报文,或多或少有误差(2)集群内所用主机都是基于主机名进行通信,建议使用hosts文件进行主机名解析
用DNS作为主机名解析,DNS服务器有可能会宕机,有可能会延迟,但是高可用集群就是为了出现故障的时候快速进行相应;有一些高可用集群会有严格要求,解析过来的主机名与对方使用真正使用的主机名必须保持一致,而DNS解析只需要名字与IP保持一致就行了,要求较低。
(3)使用独立的多播地址,避免与其他集群使用相同的多播地址
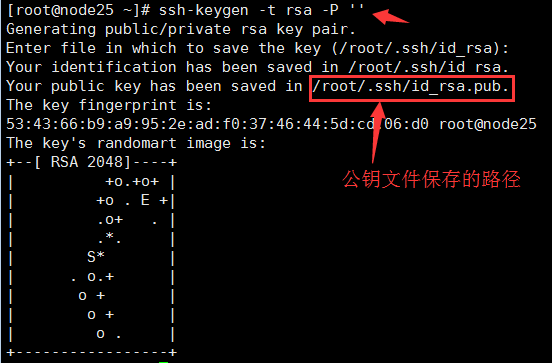
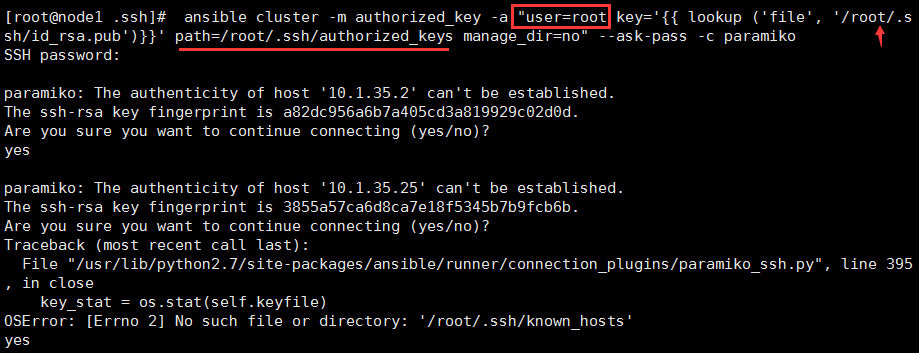
由于集群服务的机器较多,建议配置ansible,所用ansible批量安装和配置corosync与pacemaker:安装并修改ansible中的host文件,将添加集群的主机IP:使用ssh-keygen生成私钥以及公钥:使用ansible模块将公钥批量分发到个节点机(客户端):
ansible all -m authorized_key -a “user=root key='{{ lookup(‘file’, ‘/root/.ssh/id_rsa.pub’) }}’ path=/root/.ssh/authorized_keys manage_dir=no” –ask-pass -c paramiko
将hosts文件发送至个节点,以及使用ntpdate命令,进行各节点的时间同步:
~]# ansible cluster -m copy -a “src=/etc/hosts dest=/etc/hosts”~]# ansible all -m shell -a “ntpdate“

安装corosync,pacemaker由于两个包都在base仓库,所以直接使用yum安装~]# yum install -y corosync pacemaker
——————————————————————————————–
corosync的程序环境配置文件
文本格式的配置文件,建议使用:/etc/corosync/corosync.conf.example使用UDP协议的精简版corosync,建议不使用:/etc/corosync/corosync.conf.example.udpuxml格式的配置文件,建议不使用:/etc/corosync/corosync.xml.example密钥文件,默认安装是不会生成的,需要手动生成,而且该文件是一个二进制文件,目的是为了区分同一网络内的节点有配有相同配置的服务器:/etc/corosync/authkey集群信息库,每节点都会自动的同步,除了authkey文件:/var/lib/corosync
totem { } 节点间的通信协议,主要定义通信方式、通信协议版本、加密算法等 ;interface{}:定义集群心跳信息传递的接口,可以有多组;在Interface内,有四个必选参数,一个可选参数;多个网卡参与集群事务信息传递,则需要定义多个Interface,只是ringnumber,多播地址,网络地址不能一样
ringnumber #用来标记当前Interface在当前totem上的环状号码,以避免出现环状信息进入死循环,必须从0开始标记bindnetaddr #绑定的网络地址或者主机IP地址,用于集群事务信息通信的网络地址mcastaddr #多播地址,要避免使用224开头的地址mcastport #多播地址,在实现多播发送信息时,所用的端口ttl #一个报文能被中继发送多少次,一般设置为1,不允许中继broadcast #广播地址,可选,如果使用的多播地址进行集群有关的信息传递,则无需使用广播的方式了
version #指明配置文件的版本,目前取值仅有2一项可用;crypto_hash #通讯加密hash算法的类型默认是sha1,支持md5, sha1, sha256, sha384 和sha512crypto_cipher #对称加密算法类型,默认是aes256,支持aes256, aes192, aes128 and 3des,但是依赖于crypto_hash;但是越复杂的算法,越是消耗时钟周期secauth #各节点彼此通信时是否需要验证彼此身份,支持HMAC/SHA1两种方法,默认是ON,但是crypto_hash和crypto_cipher设置好了,该项也无需显式指明。—————————————–logging { } 定义日志信息to_stderr #记录到系统日志中to_logfile #记录到指定的日志文件中to_syslog #记录到syslog系统中 这三种方法只需要使用一种就行了,无需重复记录—————————————–quorum { } 定义投票系统provider #指明使用哪种算法进行投票系统,目前只支持corosync_votequorum—————————————–nodelist { } 节点列表,会自动生成,无需手动配置nodeid #指明节点id—————————————–qb { }与libqb配置有关的配置项,一般无需配置
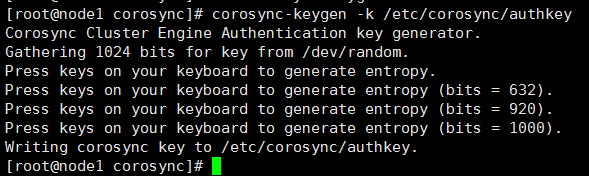
生成authkey:corosync-keygen [-k <filename>] [-l]-k 指明生成的密钥文件存放的位置-l 指明随机数生成器,默认使用熵池,熵池用紧,会使用伪随机数生成器;使用伪随机数生成器会阻塞,解决方法,下载文件,会有大量IO,也会填充到熵池中
配置示例:totem {version: 2crypto_cipher: aes256crypto_hash: sha1interface {ringnumber: 0bindnetaddr: 10.1.35.1mcastaddr: 239.255.35.1mcastport: 5405ttl: 1}}logging {fileline: offto_stderr: noto_logfile: yeslogfile: /var/log/cluster/corosync.logto_syslog: nodebug: offtimestamp: on #时间戳标签,如果记录到系统日志,则无需开启logger_subsys { #是否记录子系统日志subsys: QUORUM #记录选举系统日志debug: off #关闭调试模式}}quorum {provider: corosync_votequorum#two_node: 1 #如果是两节点集群,显式定义}nodelist {node {ring0_addr: node1.hunter.comnodeid: 1}node {ring0_addr: node1.hunter.comnodeid: 2}node {ring0_addr: node1.hunter.comnodeid: 3}}
~ ]# scp authkey corosync.conf 10.1.35.2:/etc/corosync/~ ]# scp authkey corosync.conf 10.1.35.25:/etc/corosync/

验正服务启动:
(1) 查看日志;
(2) corosync-cmapctl | grep memberscorosync-cmapctl 查看对象数据信息(CID)(3) corosync-cfgtool:管理工具;
-s:显示当前节点各ring相关的信息;-R:控制所有节点重载配置;
pacemaker:
程序环境:
配置文件:/etc/sysconfig/pacemaker主程序:/usr/sbin/pacemakerdUnit File:pacemaker.service
启动服务:systemctl start pacemaker.service
监控服务启动是否正常:# crm_monpacemaker提供的工具
 由于pacemaker提供的的工具都是一些底层工具,用起来过于麻烦,建议使用crmsh,只需要一个控制节点安装即可 (也可以在多个节点上安装进行控制)
由于pacemaker提供的的工具都是一些底层工具,用起来过于麻烦,建议使用crmsh,只需要一个控制节点安装即可 (也可以在多个节点上安装进行控制)

===================================================================
crmsh安装
crmsh-2.1.4-1.1.x86_64.rpmpssh-2.3.1-4.2.x86_64.rpmpython-pssh-2.3.1-4.2.x86_64.rpm
—————————————–
配置接口(crmsh/pcs)
crmsh:
运行方式:
交互式方式:
crm(live)#
命令方式:crm COMMAND获取帮助:ls, help
help [KEYWORD]
COMMAND:#凡是带有/的都表示有子命令cd Navigate the level structurehelp Show help (help topics for list of topics)ls List levels and commandsquit Exit the interactive shellreport Create cluster status reportstatus Cluster statusup Go back to previous levelcib/ CIB shadow managementcibstatus/ CIB status management and editingcluster/ Cluster setup and managementconfigure/ CIB configuration 主配置工具assist/ Configuration assistant 配置辅助工具,一般比较少用history/ Cluster history,显示历史状态信息ra/ Resource Agents (RA) lists and documentation,显示RA信息template/ Edit and import a configuration from a template,定制模板corosync/ Corosync management,corosync 管理器node/ Nodes management 节点状态控制options/ User preferences,用户配置resource/ Resource management(ra资源管理器)script/ Cluster script management 脚本管理site/ Site support,报告站点相关信息
configure命令:
Finally, there are the cluster properties, resource meta attributes defaults, and operations defaults. All are just a set of attributes. These attributes are managed by the following commands:
– property– rsc_defaults– op_defaults
Commands for resources are:
– primitive– monitor– group– clone– ms/master (master-slave)
There are three types of constraints:
– location– colocation– order
设置集群的全局属性:property
stonith-enabled=true|false
定义一个primitive资源的方法:
primitive <rsc> {[<class>:[<provider>:]]<type>} [params attr_list] [op op_type [<attribute>=<value>…] …]
op_type :: start | stop | monitor
定义一个组资源的方法:
group <name> <rsc> [<rsc>…]
<rsc>:资源的ID,字符串;
[<class>:[<provider>:]]<type>
定义资源监控:
(1) monitor <rsc>[:<role>] <interval>[:<timeout>]使用monitor命令,指定要监控的资源<rsc>,指定监控的时间间隔<interval>,该资源的超时时间<timeout>(2) primitive <rsc> {[<class>:[<provider>:]]<type>} [params attr_list] [op monitor interval=# timeout=#]如果在使用primitive创建资源的时候,则无需指明监控的资源<rsc>
ra:
Commands:cd Navigate the level structureclasses List classes and providershelp Show help (help topics for list of topics)info Show meta data for a RAlist List RA for a class (and provider)ls List levels and commandsproviders Show providers for a RA and a classquit Exit the interactive shellup Go back to previous level
—————————————–
常用命令:
classes:类别列表
list CLASSES [PROVIDER]:列出指定类型(及提供者)之下的所有可用RA;info [<class>:[<provider>]:]]<type>:显示指定的RA的详细文档;
—————————————–
资源约束关系的定义:
位置约束:
location <id> rsc <score>: <node><score>:#, -#inf, -inf
property default-resource-stickiness
排列约束:
colocation <id> <score>: <rsc> <with-rsc>
顺序约束:
order <id> [{kind|<score>}:] first then [symmetrical=<bool>]kind :: Mandatory(强制) | Optional(可选) | Serialize(序列化,按顺序停止启动)symmetrical(默认是对称的,先启动的最后停止)
resource:资源管理命令
migrate 迁移资源start 启动资源stop 停止资源status 资源状态查看cleanup 清理资源中间状态(中间状态可以有助于对故障的判断,但是有时候需要清理完之后才能重启资源)
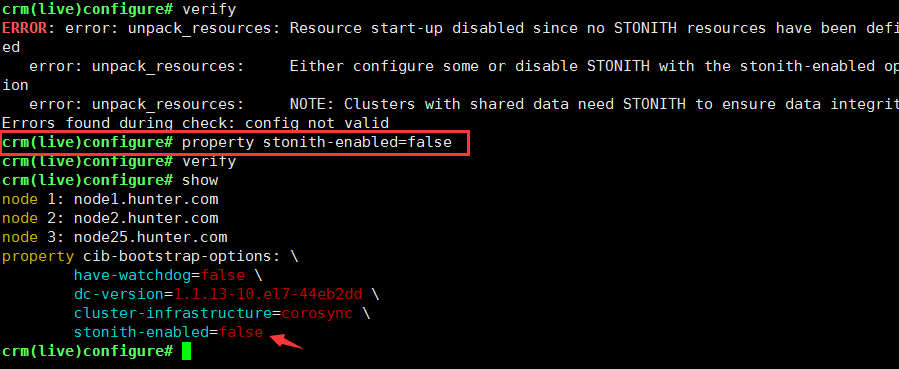
首先,由于没有stonith设备(软硬件设备均没有),所有使用verify查看配置文件是否正确时,会报错,所以,先将stonith关闭
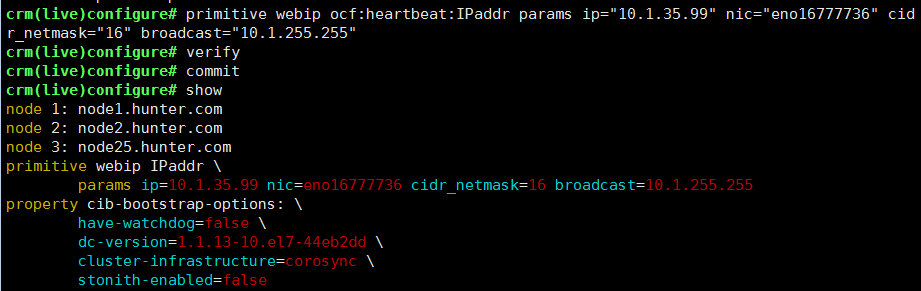
配置虚拟地址-VIP
crm(live)configure# primitive webip ocf:heartbeat:IPaddr params ip=”10.1.35.99″ nic=”eno16777736″ cidr_netmask=”16″ broadcast=”10.1.255.255″在命令行模式,使用命令ip a l 可以查看,此时VIP以复制地址的形式配置在指定的网卡上了

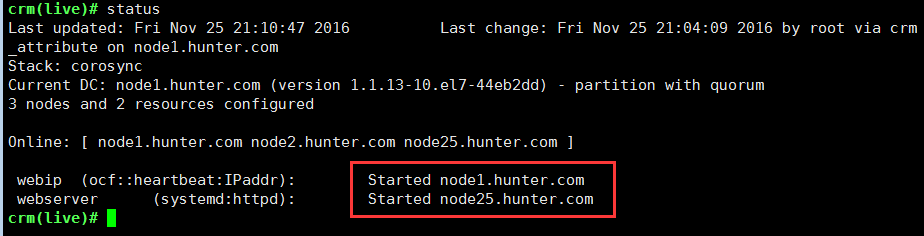
添加httpd服务:crm(live)configure# primitive webserver systemd:httpdcrm(live)configure#commit默认情况下,集群运行资源是以尽量平均分配资源到各节点为目的的,但是高可用服务需要这两个资源要在一起才有意义,可以使用排列约束或者位置约束
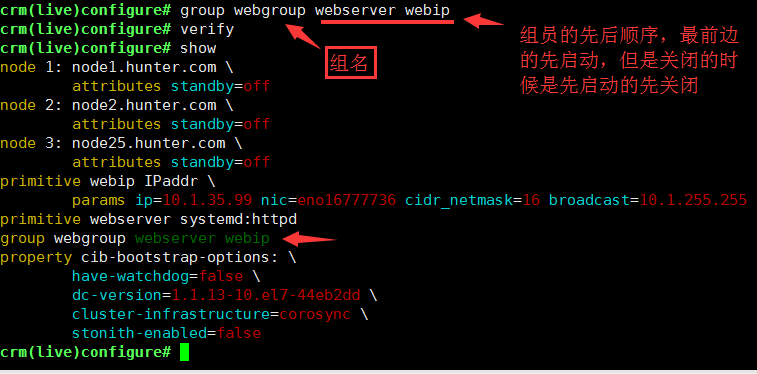
定义组,使用排列约束:
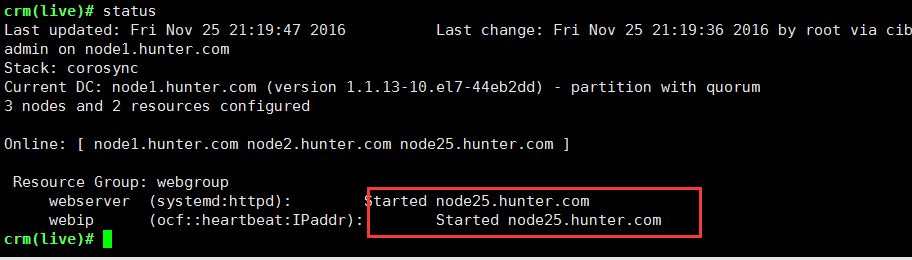
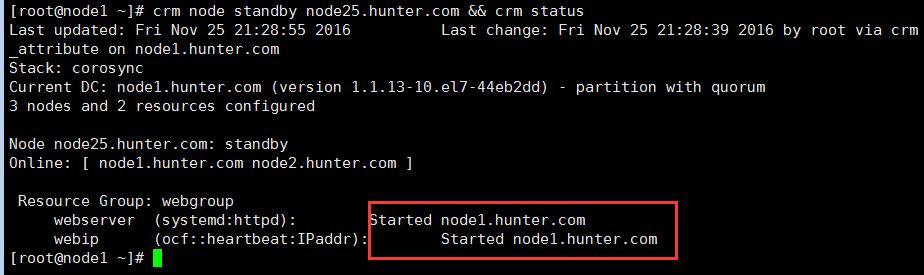
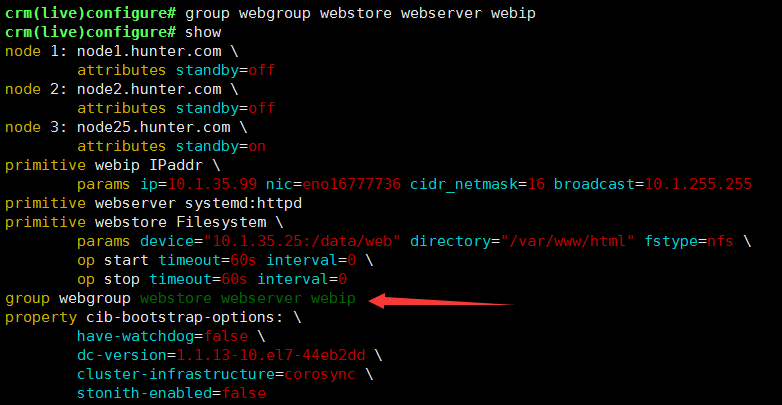
crm(live)configure# group webgroup webserver webipcrm(live)# status使用命令status,此时webip与webserver已经运行在同一个ra上了此时使用命令请求页面,是在node25上然后standby node25.hunter.com后再次请求页面:资源已经迁移到node1上;


—————————————–
删除资源:
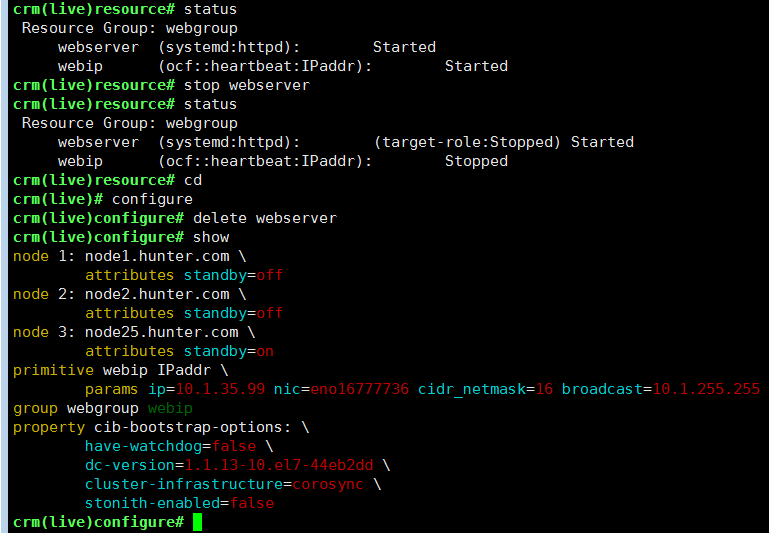
删除资源需要先停止资源;可以进入resoource;resource –> stop webserver –> cd –> configure –> delete webserver –> show检查是否已经成功删除
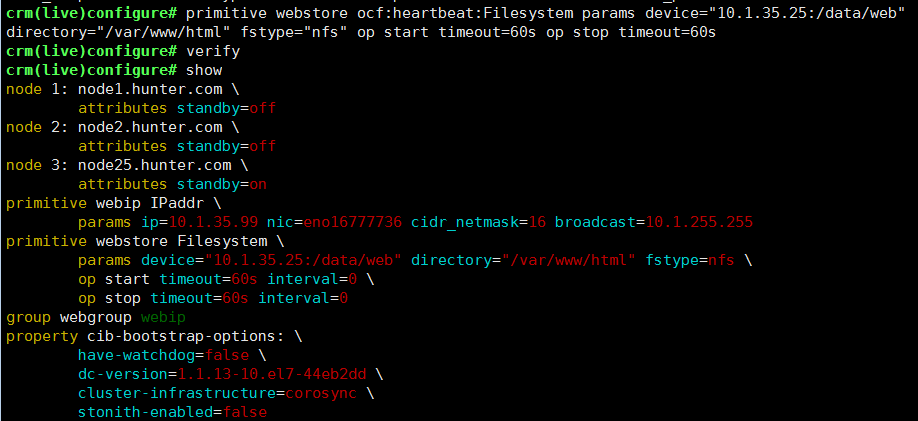
定义共享文件系统:primitive webstore ocf:heartbeat:Filesystem params device=”10.1.35.25:/data/web” directory=”/var/www/html” fstype=”nfs” op start timeout=60s op stop timeout=60s由于默认的超时时间是20秒,所以还需要op超时,重新指点超时时间

按正常顺序进行排列(先挂载文件系统,然后启动httpd服务,最后设定VIP)
添加资源监控:
由于此时已经创建了资源,则直接使用monitor添加监控规则:定义完之后需要verify检查是否符合标准,如果不符合,此时可以直接使用edit直接修改,没有问题则可以提交
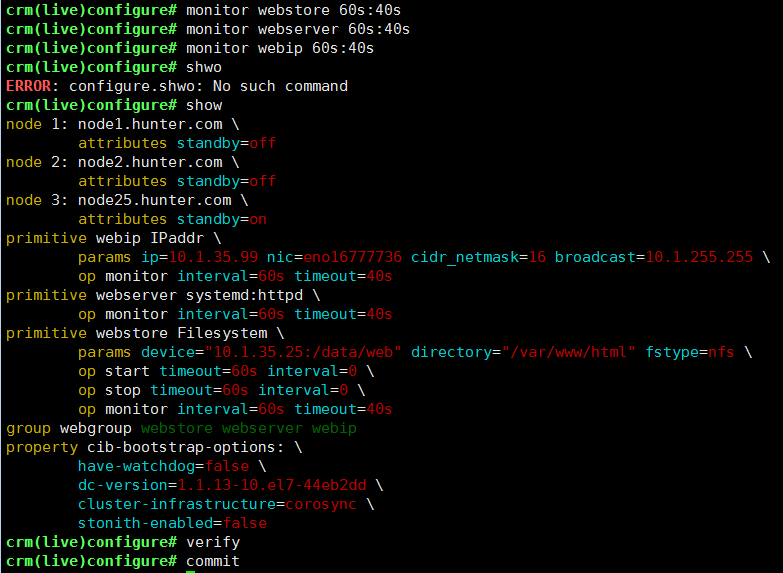
当使用命令killall httpd,监控程序会在指定的时间(60秒检查一个,超时时间为30秒)监测,如果资源不在线,默认会重启服务,如果重启不成功,则会将资源迁移到其他节点上
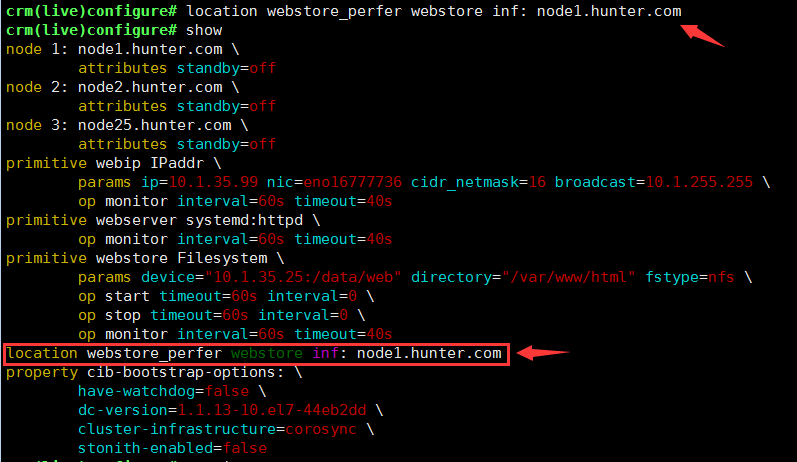
位置约束:(资源与节点的关系)
location <id> rsc <score>: <node>使用location定义一个<id>,指明资源 rsc 对节点<node>的<score>依赖程度<score>:#, -#inf, -inf
property default-resource-stickiness=<score> #资源默认对当前的黏性程度为score即:如果资源的倾向性无法大于资源对节点的黏性的话,资源还是会停留在当前节点之上例子:
使用location定义webstore对节点1的倾向性为正无穷:crm(live)configure# location webstore_perfer webstore inf: node1.hunter.com如果再定义webserver对node1的倾向性对node1服务的倾向性为负无穷,且将这两个服务定义在一个组,会有什么现象?将webstore定义在node1节点为负无穷,webserver定义在node1节点为正无穷,且将两个资源定义在同一个组内将出节点1之外的全部节点都standby,那么,该组的资源是不会启动的,及将一个正无穷资源与一个负无穷资源放一起是没有办法启动的
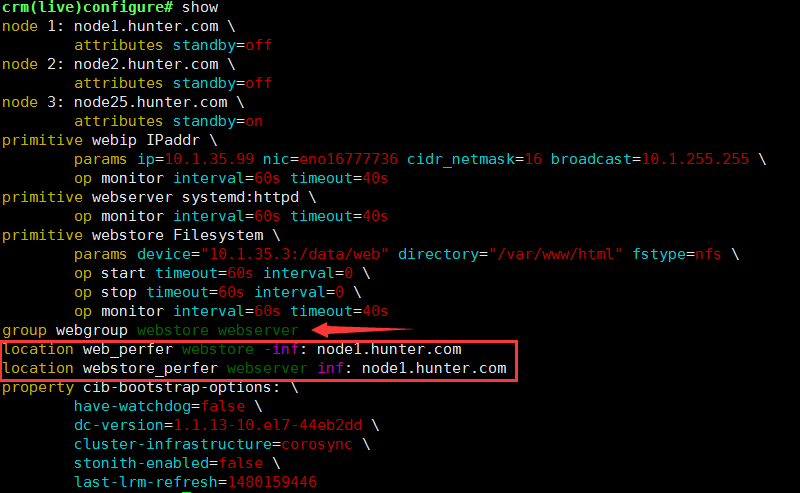
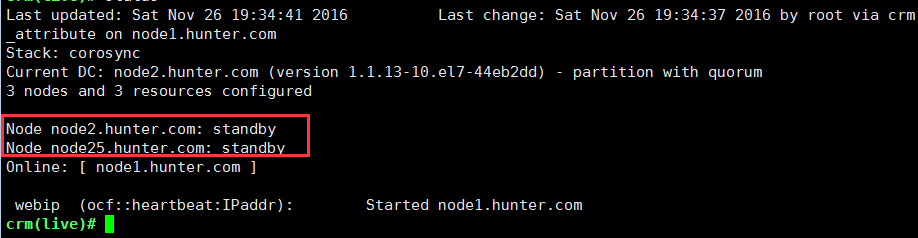
排列约束(资源与资源的倾向性的关系):colocation <id> <score>: <rsc> <with-rsc>….. #使用命令colocation,定义一个约束名称<id>,指明资源1<rsc>与资源2<with-rsc>….在一起的倾向性<score>;注意<with-rsc>可以有多个
顺序约束(资源启动的先后顺序):
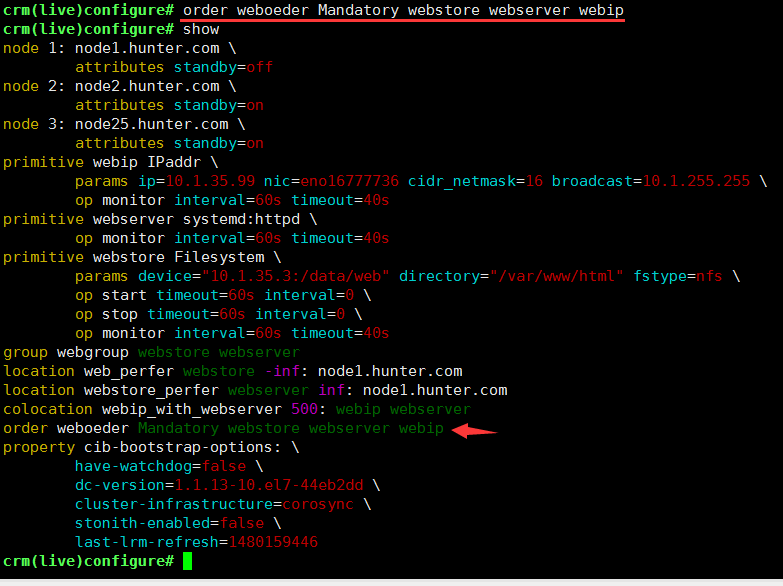
order <id> [{kind|<score>}:] first then [symmetrical=<bool>]kind :: Mandatory(强制) | Optional(可选) | Serialize(序列化,按顺序停止启动)symmetrical(默认是对称的,先启动的最后停止)使用命令order,定义一个顺序约束的名字<id>,指明kind的类型(是强制的,还是可选的,还是序列化),最后列出资源的启动顺序crm(live)configure# order weboeder Mandatory webstore webserver webip
原创文章,作者:hunter,如若转载,请注明出处:http://www.178linux.com/60992
