

MHA
一:简述MHA
1.1关于MHA
MHA(Master HA)是一款开源的MySQL的高可用程序,它为MySQL主从复制架构提供了automating master failover 功能。MHA在监控到master节点故障时,会提升其中拥有最新数据的slave节点成为新的master节点,在此期间,MHA会通过与其它从节点获取额外信息来避免一致性方面的问题。MHA还提供了master节点的在线切换功能,即按需切换master/slave节点。
相较于其它HA软件,MHA的目的在于维持MySQL Replication中Master库的高可用性,其最大特点是可以修复多个Slave之间的差异日志,最终使所有Slave保持数据一致,然后从中选择一个充当新的Master,并将其它Slave指向它。
————————————————————————————-
1.2 MHA角色部署
MHA 服务有两种角色,MHA Manager(管理节点)和MHA Node(数据节点):
MHA Manager:通常单独部署在一台独立的机器上或者直接部署在其中一台slave上(不建议后者),管理多个master/slave集群,每个master/slave集群称作一个application;其作用有二:
(1)master自动切换及故障转移命令运行
(2)其他的帮助脚本运行:手动切换master;master/slave状态检测
MHA node:运行在每台MySQL服务器上(master/slave/manager),它通过监控具备解析和清理logs功能的脚本来加快故障转移。其作用有:
(1)复制主节点的binlog数据
(2)对比从节点的中继日志文件
(3)无需停止从节点的SQL线程,定时删除中继日志


————————————————————————————-
1.3 MySQL复制集群中的master故障时,MHA按如下步骤进行故障转移:
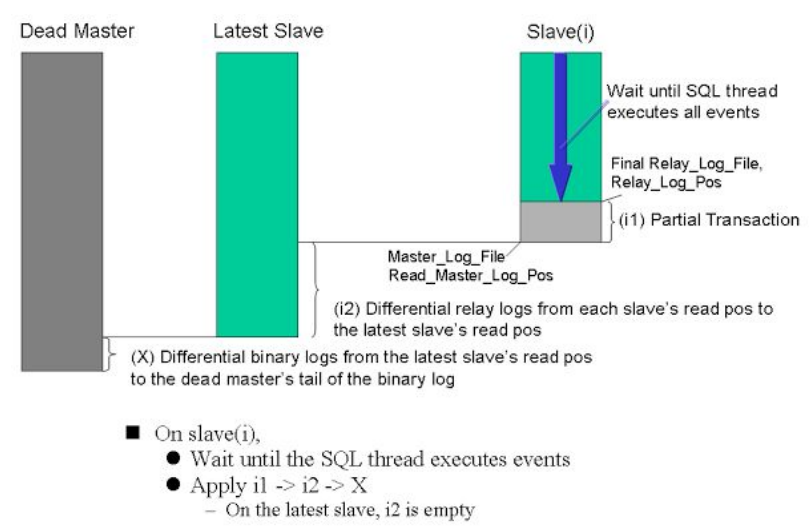
从上图可总结MHA工作步骤为:
-从宕机崩溃的master保存二进制日志事件(binlogevents)。
-识别含有最新更新的slave。
-应用差异的中继日志(relay log)到其它slave。
-应用从master保存的二进制日志事件(binlogevents)。
-提升一个slave为新master。
-使其它的slave连接新的master进行复制。
————————————————————————————-
1.4 MHA组件:
(1)、 Manager工具:
– masterha_check_ssh : 检查MHA的SSH配置。
– masterha_check_repl : 检查MySQL复制。
– masterha_manager : 启动MHA。
– masterha_check_status : 检测当前MHA运行状态。
– masterha_master_monitor : 监测master是否宕机。
– masterha_master_switch : 控制故障转移(自动或手动)。
– masterha_conf_host : 添加或删除配置的server信息。
(2)、 Node工具(这些工具通常由MHAManager的脚本触发,无需人手操作)。
– save_binary_logs : 保存和复制master的二进制日志。
– apply_diff_relay_logs : 识别差异的中继日志事件并应用于其它slave。
– filter_mysqlbinlog : 去除不必要的ROLLBACK事件(MHA已不再使用这个工具)。
– purge_relay_logs : 清除中继日志(不会阻塞SQL线程)。
(3)、自定义扩展:
-secondary_check_script:通过多条网络路由检测master的可用性;
-master_ip_failover_script:更新application使用的masterip;
-shutdown_script:强制关闭master节点;
-report_script:发送报告;
-init_conf_load_script:加载初始配置参数;
-master_ip_online_change-script:更新master节点ip地址;
=================================================
二:准备 MySQL Replication 环境
由于主节点有可能会被切换成从节点,而每一个从节点也有可能会被切换成主节点,所以MHA对Mysql复制环境有特殊要求,例如:
(1)各节点都要开启 二进制日志及中继日志;
(2)各从节点必须显示注明其为 read_only;
(3)关闭各从节点的 relay_log_purge 中继日志自动清理功能
本实验环境共有四个节点,其角色配置如下:
node1:MariaDB master
node2:MariaDB slave
node3:MariaDB slave
node25:MHA Manager
各节点的/etc/hosts 文件配置内容如下:

初始主节点 master 配置 :
server-id = 1
relay-log = relay-log
log-bin = bin-log
innodb-file-per-table = ON
skip-name-resolve = ON
所有slave节点配置:
server-id = 2 #复制集群中的各节点server_ip必须唯一
relay-log = relay-log
log-bin = bin-log
innodb-file-per-table = ON
skip-name-resolve = ON
relay-log-purge = 0
read-only = 1
按上述要求分别配置好主从节点之后,按MySQL复制配置架构的配置方式将其配置完成,并启动master节点和个slave节点,以及为各slave节点启动其IO和SQL线程,确保主从复制无误。
而后,在所有Mysql节点授权拥有管理权限的用户可在本地网络中有其他节点上远程访问。当然,此时仅需要且只能在master节点上运行类似如下SQL语句即可:
GRANT REPLICATION SLAVE,REPLICATION CLIENT ON *.* TO ‘mhauser’@’HOST’ IDENTIFIED BY ‘mhapasswd’

其他节点也可以手动输入上边的SQL语句,也可以在从服务器指定主服务器的时候,指定的bin-log文件的位置时,包含次语句:
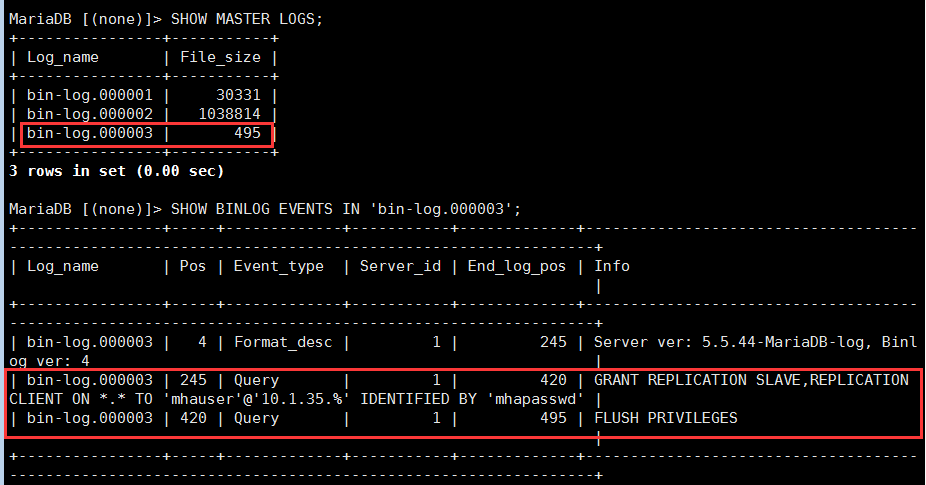
而从节点相对应的运行SQL语句为:
CHANGE MASTER TO MASTER_HOST=’10.1.35.1′,MASTER_USER=’mhauser’,MASTER_PASSWORD=’mhapasswd’,MASTER_LOG_FILE=’master-log-000003′,MASTER_LOG_POS=420;

=================================================
三、安装配置 MHA
3.1 准备基于ssh互信通信环境
MHA 与 ansible 类似 ,集群中的各节点彼此之间均需要基于ssh互信通信,以实现远程控制及数据管理功能。
简单起见,可在Manager节点生成密钥对,并设置其可远程连接本地主机后,将私钥文件及authorized_keys 文件复制给余下的所有节点即可。
下面的操作可在manager节点操作:
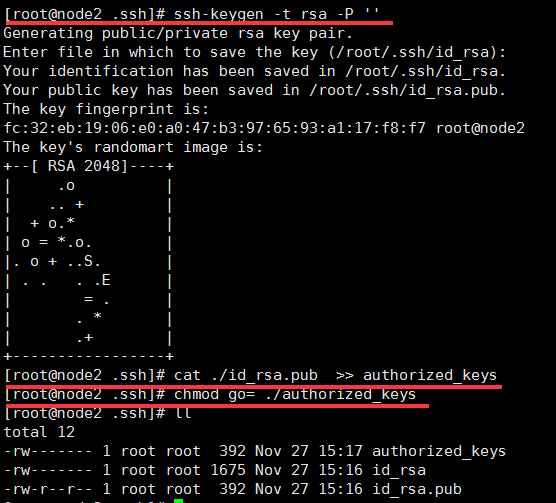
[root@node25 .ssh]# ssh-keygen -t rsa -P ”
[root@node25 .ssh]# cat ./id_rsa.pub >> authorized_keys
[root@node25 .ssh]# chmod go= ./authorized_keys
然后再使用scp命令将id_rsa 和 authorized_keys 文件分发至各节点
—————————————————————————
3.2 安装MHA
除了源码包,MHA官方也提供了rpm格式的程序包。centos7 系统可以直接使用使用与e16的程序包。另外,MHA Manager 和 MHA Node 程序包的版本并不强制要求一致。
Manager节点(需要将Manager包和Node包一起安装):
~]# yum install -y mha4mysql-manager-0.56-0.el6.noarch.rpm mha4mysql-node-0.56-0.el6.noarch.rpm
Node节点:
~]# yum install -y ./mha4mysql-node-0.56-0.el6.noarch.rpm
—————————————————————————
3.3 初始化 MHA
Manager 节点需要为每个监控 master/slave 集群提供一个专用的配置文件,而所有的master/slave 集群也可以共享全局。全局配置文件默认为 /etc/masterha_default.cnf ,其为可选配置。如果仅监控一组master/slave集群,也可以通过application的配置来提供各服务器的默认配置信息。而每个application的配置文件路径为自定义。
例如,本示例中将使用 /etc/masterhs/app1.cnf,内容如下:
[server default]
user=mhaadmin #mha用于管理数据库的账号,尽量不要使用root账号,权限过大,root可以用root授权其他用户
password=mhapasswd
manager_workdir=/data/masterha/app1
manager_log=/data/masterha/app1/manager.log
remote_workdir=/data/masterha/app1
ssh_user=root
repl_user=mhauser #mysql主从复制的账号
repl_password=mhapasswd
ping_interval=1 #检测主服务器健康状态的时间间隔,单位为秒
[server1]
hostname=10.1.35.1
#ssh_port=22022
candidate_master=1 #1表示主服务宕机的时候,该节点可以提升为主节点;如果不提升为主节点,则为no_master=1
[server2]
hostname=10.1.35.2
#ssh_port=22022
candidate_master=1
[server3]
hostname=10.1.35.3
#ssh_port=22022
candidate_master=1
———————————————————
由于还需要一个mysql账号,用于给予mha管理mysql,所以,可以直接在主服务器上创建账号,并授予其权限,由于已建立了主从复制关系,所以,无需在其它从节点上重复创建账号:

———————————————————
检测各节点间ssh互信通信配置时候OK:
~]# masterha_check_ssh–conf=/etc/master/app1.cnf

检测成功,最后会提示 All SSH connection tests passed successfully.
———————————————————
检查管理Mysql复制集群的连接配置参数是否OK(即repl_user与repl_assword是否正确)
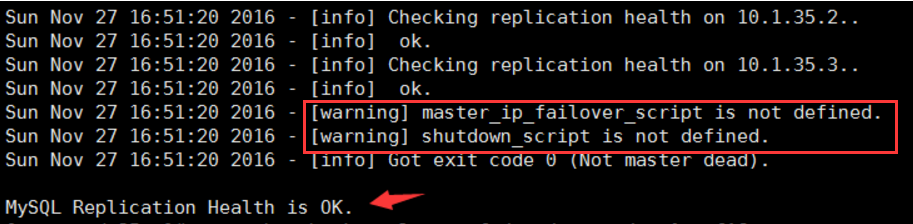
检测成功,最后会提示 Health is OK
但是会提示:
(1)没有定义主服务器宕机的时候,VIP地址转移的脚本,用于转移master前先配置VIP,需要自行编写,以可以结合keepalive来进行转移;此时先使用真正的IP进行测试线
(2)没有定义关闭主服务的脚本,但是rpm包自带有一个/usr/bin/masterha_stop;
———————————————————
启动MHA:
~]# masterha_manager –conf=/etc/master/app1.cnf > /data/masterha/app1/manager.log &>1 &
将MHA 输出的日志信息重定向至指定的日志文件中
———————————————————
启动成功后,可通过如下命令查看master节点的状态:
~]# masterha_check_status –conf=/etc/master/app1.cnf

———————————————————
停止MHA ,运行命令:
~]# masterha_stop –conf=/etc/master/app1.cnf
———————————————————
3.4 测试故障转移:
(1)在master节点关闭mariadb服务
killall -9 mysql mysqld_safe
(2)查看日志/data/masterha/app1/manager.log
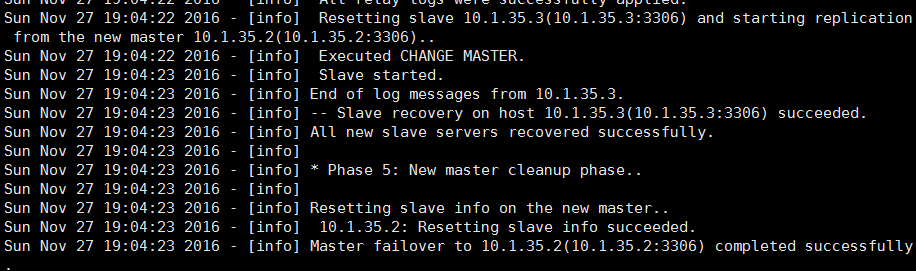
由日志文件可看出,node2已经成为新的master,而node3复制的指向也改为node2了
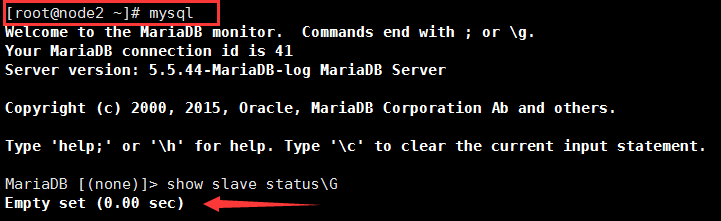
在节点2上查看slave状态,已经表明slave停止了,显然成为了master
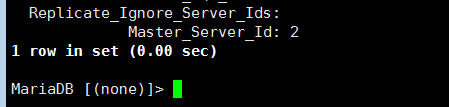
在节点3上查看slave状态,master_server_id已经改为2了
注意:当故障转移后,manager将会自动停止,此时使用masterha_check_status命令将会遇到错误提示,如下:

———————————————————
(3)提供新的从节点以及修复复制集群
原有的master节点故障后,需要重新准备一个新的MySQL节点。基于来自于master节点的备份数据恢复后,将其配置为新的master的从节点即可。
注意,新加入的节点如果为新增节点,气IP地址要配置为原来master节点的IP,否则,还需要修改app1.cnf中相应的IP地址。随后再次启动manager,并再次检测其状态。
在修复由于宕机而下来的服务器时,尽量不要使用脚本进行修复,检查好数据的完整性后再上线。
=====================================================
四、进一步工作
前边三个步骤已经配置了一个基本的MHA环境。不过,为了更多实际应用的要求,还需要进一步完成如下操作。
(1)提供额外的检测机制,以免master的监控做出误判
(2)可借助keepalive等高可用服务,在master节点上提供VIP地址对外提供服务,以免master节点转换时,客户端的请求无法送达;
(3)进行故障转移时对原master节点执行stonith操作,以避免脑裂;可通过指定的shutdown_script实现;
(4)必要时,进行在线master节点转换;
、
原创文章,作者:hunter,如若转载,请注明出处:http://www.178linux.com/61111
