

一、MHA简介
二、试验环境及要求
三、部署MHA
四、测试MHA集群功能
一、MHA简介
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案。在MySQL故障切换过程中,MHA能做到在0~30秒之内手动或自动(结合脚本)完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用性。
该软件由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。

二、试验环境及要求
1、linux系统版本:cento7.2
[root@jev71 ~]#cat /etc/centos-release CentOS Linux release 7.2.1511 (Core)
2、mysql版本:5.5
[root@jev71 ~]#mysql Welcome to the MariaDB monitor. Commands end with ; or g. Your MariaDB connection id is 12 Server version: 5.5.44-MariaDB-log MariaDB Server Copyright (c) 2000, 2015, Oracle, MariaDB Corporation Ab and others.
3、keeplived版本:1.2
[root@jev71 ~]#keepalived -v Keepalived v1.2.13 (11/20,2015)
4、mha4myqsl版本:0.56
[root@jev74 ~]#ll -rw-r--r--. 1 root root 87119 Nov 9 2015 mha4mysql-manager-0.56-0.el6.noarch.rpm -rw-r--r--. 1 root root 36326 Nov 9 2015 mha4mysql-node-0.56-0.el6.noarch.rpm
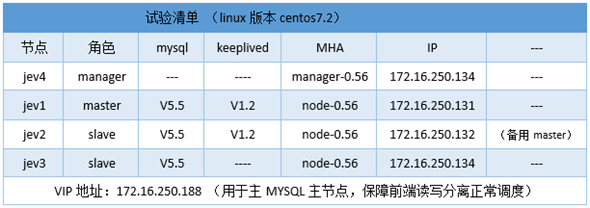
5、试验清单:
三、部署MHA
1、确保各节点之间时间同步
[root@jev6 ~]#ansible jev7[1-4].com -m shell -a "date"
2、各个节点之间需通过主机名可互相通信
这里以编辑manager节点为例
[root@jev74 ~]#cat /etc/hosts 127.0.0.1 jev74.com jev74 172.16.250.131 jev71.com jev71 # master 172.16.250.132 jev72.com jev72 # slave 172.16.250.133 jev73.com jev73 # slave 172.16.250.134 jev74.com jev74 # manager
3、各个节点之间需通过主机名可直接SSH登录
[root@jev74 ~]#ssh-keygen -t rsa -P ''
[root@jev74 ~]#cat .ssh/id_rsa.pub >>.ssh/authorized_keys
[root@jev74 ~]#chmod go= .ssh/authorized_keys
[root@jev74 ~]#for i in {1..3} ;do scp -p .ssh/id_rsa .ssh/authorized_keys root@jev7$i:/root/.ssh/;done
The authenticity of host 'jev71 (172.16.250.131)' can't be established.
ECDSA key fingerprint is e3:11:54:04:58:2d:37:2a:86:50:0b:cf:c3:e9:30:e6.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'jev71,172.16.250.131' (ECDSA) to the list of known hosts.
root@jev71's password:
。 。 。
4、配置mysql集群,确保主从复制正常
#mastet节点配置: [root@jev71 ~]#vim /etc/my.cnf.d/repl.cnf [mysqld] server-id=1 log-bin=master-log relay-log=relay-log #slave节点配置: [root@jev72 ~]#vim /etc/my.cnf.d/repl.cnf [mysqld] server-id=2 log-bin=master-log relay-log=relay-log relay_log_purge=0 read_only=1 skip_name_resolve=1 innodb_file_per_table=1 [root@jev73 ~]#vim /etc/my.cnf.d/repl.cnf [mysqld] server-id=3 log-bin=master-log relay-log=relay-log relay_log_purge=0 read_only=1 skip_name_resolve=1 innodb_file_per_table=1 #启动mysql: [root@jev71 ~]# systemctl start mariadb && systemctl status mariadb [root@jev72 ~]# systemctl start mariadb && systemctl status mariadb [root@jev73 ~]# systemctl start mariadb && systemctl status mariadb #主节点授权repluser及mhaadmin用户: [root@jev71 ~]#mysql #记住maser日志状态 MariaDB [(none)]> show master status ; +-------------------+----------+--------------+------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | +-------------------+----------+--------------+------------------+ | master-log.000002 | 245 | | | +-------------------+----------+--------------+------------------+ #授权主从复制用户-repluser MariaDB [(none)]> grant replication slave,replication client on *.* to 'repluser'@'172.16.250.%' identified by 'replpass' ; #授权MHA管理用户-mhaadmin MariaDB [(none)]> grant all on *.* to 'mhaadmin'@'172.16.250.%' identified by 'mhapass' ; 从节点启动复制:master_log_file,master_log_pos 为刚刚在master查看的maser日志状态; [root@jev72 ~]#mysql #配置主从复制起点 MariaDB [(none)]> change master to master_host='172.16.250.131',master_user='repluser',master_password='replpass',master_log_file='master-log.000002',master_log_pos=245; #查看主从复制情况 MariaDB [(none)]> show grants for 'repluser'@'172.16.250.%'; +----------------------------------------------------------------------------------------------------------------------------------------------------+ | Grants for repluser@172.16.250.% | +----------------------------------------------------------------------------------------------------------------------------------------------------+ | GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'repluser'@'172.16.250.%' IDENTIFIED BY PASSWORD '*D98280F03D0F78162EBDBB9C883FC01395DEA2BF' | +----------------------------------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec) [root@jev73 ~]#mysql MariaDB [(none)]> change master to master_host='172.16.250.131',master_user='repluser',master_password='replpass',master_log_file='master-log.000002',master_log_pos=245; MariaDB [(none)]> show grants for 'repluser'@'172.16.250.%'; +----------------------------------------------------------------------------------------------------------------------------------------------------+ | Grants for repluser@172.16.250.% | +----------------------------------------------------------------------------------------------------------------------------------------------------+ | GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'repluser'@'172.16.250.%' IDENTIFIED BY PASSWORD '*D98280F03D0F78162EBDBB9C883FC01395DEA2BF' | +----------------------------------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec)
5、配置keepalived高可用VIP
在master及备用master节点安装keepalived
[root@jev6 ~]#ansible jev7[1:2].com -m yum -a "name=keepalived state=latest"
keepliaved配置文件,下面为keepalived主节点配置,从节点参考备注信息,配置时注意去掉#后面的注释
[root@jev71 ~]#cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
acassen@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id mysql
vrrp_mcast_group4 224.0.88.88 #组播地址
}
vrrp_script chk_mysqld {
script "killall -0 mysqld && exit 0 || exit 1"
interval 1
weight -5
fall 2
}
vrrp_instance VI_1 {
state BACKUP
interface eno16777736
virtual_router_id 8
priority 100 #权重,jev72上的值要略低于100,但要高于100-weight,本例应为96-99
advert_int 1
nopreempt #不抢占模式,从节点上不必配置此项
authentication {
auth_type PASS
auth_pass mysqlvipass
}
track_script {
chk_mysqld
}
virtual_ipaddress {
172.16.250.188/16 dev eno16777736 #高可用的VIP地址
}
}
启动keepalived集群,注意启动顺序,先启动主节点,在启动从节点
[root@jev71 ~]#systemctl restart keepalived && systemctl status keepalived [root@jev72 ~]#systemctl restart keepalived && systemctl status keepalived
VIP默认绑定在主节点上(jev1),VIP漂移是否正常,可以通过tcpdump抓包跟ip命令查看(具体验证方式比较简单,这里就不多说)
[root@jev74 ~]#tcpdump -i eno16777736 -nn host 224.0.88.88 21:31:11.536386 IP 172.16.250.131 > 224.0.88.88: VRRPv2, Advertisement, vrid 8, prio 100, authtype simple, intvl 1s, length 20 [root@jev71 ~]#ip a 1 eno16777736: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:0c:29:a1:c8:d1 brd ff:ff:ff:ff:ff:ff inet 172.16.250.131/16 brd 172.16.255.255 scope global eno16777736 valid_lft forever preferred_lft forever inet 172.16.250.188/16 scope global secondary eno16777736 valid_lft forever preferred_lft forever
6、安装配置MHA
MHA项目地址:https://github.com/yoshinorim/mha4mysql-manager
在主节点上mha4mysql-manager及其mha4mysql-node两管理软件
[root@jev74 ~]#yum install mha4mysql-manager-0.56-0.el6.noarch.rpm mha4mysql-node-0.56-0.el6.noarch.rpm -y
在从节点上mha4mysql-node软件
[root@jev74 ~]#for i in {1..3} ;do scp -p mha4mysql-node-0.56-0.el6.noarch.rpm root@jev7$i:/root/;done
[root@jev71 ~]#yum install mha4mysql-node-0.56-0.el6.noarch.rpm -y
[root@jev72 ~]#yum install mha4mysql-node-0.56-0.el6.noarch.rpm -y
[root@jev73 ~]#yum install mha4mysql-node-0.56-0.el6.noarch.rpm -y
创建配置文件
[root@jev74 ~]#mkdir /etc/masterha/ [root@jev74 ~]#vim !$app1.cnf vim /etc/masterha/app1.cnf [server default] user=mhaadmin password=mhapass manager_workdir=/data/masterha/app1 manager_log=/data/masterha/app1/manager.log remote_workdir=/data/masterha/app1 ssh_user=root repl_user=repluser repl_password=replpass ping_interval=1 [server1] hostname=172.16.250.131 candidate_master=1 [server2] hostname=172.16.250.132 candidate_master=1 [server3] hostname=172.16.250.133 [root@jev74 ~]#mkdir -pv /data/masterha/app1
四、测试MHA集群功能
1、检查主机间SSH通讯及健康状态
检查主机之间ssh通讯状态,状态必须为All SSH connection tests passed successfully.才能进行后面操作;
[root@jev74 ~]#masterha_check_ssh --conf=/etc/masterha/app1.cnf 。 。 。 Tue Feb 21 20:05:29 2017 - [info] All SSH connection tests passed successfully.
检查集群就看状态,状态必须为MySQL Replication Health is OK.才能进行后面操作;
[root@jev74 ~]#masterha_check_repl --conf=/etc/masterha/app1.cnf 172.16.250.131(172.16.250.131:3306) (current master) +--172.16.250.132(172.16.250.132:3306) +--172.16.250.133(172.16.250.133:3306) 。 。 。 MySQL Replication Health is OK.
2、启动MHA及验证master是否能正常切换
启动masterha_manager
#以进程方式运行masterha_manager
[root@jev74 ~]#nohup masterha_manager --conf=/etc/masterha/app1.cnf >/data/masterha/app1/manager.log 2>&1 & #查看masterha_manager进程是否在后台正常运行 [root@jev74 ~]#ps aux |grep masterha_manager root 12264 0.1 2.1 298672 21512 pts/2 S 21:13 0:00 perl /usr/bin/masterha_manager -conf=/etc/mas terha/app1.cnfroot 12532 0.0 0.0 112644 956 pts/2 S+ 21:17 0:00 grep --color=auto masterha_manager #查看masterha_manager运行状态(app1集群) [root@jev74 ~]#masterha_check_status --conf=/etc/masterha/app1.cnf app1 (pid:12264) is running(0:PING_OK), master:172.16.250.131
制造故障,关闭master(jev1)的mysql进程
[root@jev71 ~]#systemctl stop mariadb && systemctl status mariadb
查看masterha_manager的日志信息,可以发现jev2成为新的master节点
[root@jev74 ~]#tail -15 /data/masterha/app1/manager.log app1: MySQL Master failover 172.16.250.131(172.16.250.131:3306) to 172.16.250.132(172.16.250.132:3306) succeeded Master 172.16.250.131(172.16.250.131:3306) is down! Check MHA Manager logs at jev74.com:/data/masterha/app1/manager.log for details. Started automated(non-interactive) failover. The latest slave 172.16.250.132(172.16.250.132:3306) has all relay logs for recovery. Selected 172.16.250.132(172.16.250.132:3306) as a new master. 172.16.250.132(172.16.250.132:3306): OK: Applying all logs succeeded. 172.16.250.133(172.16.250.133:3306): This host has the latest relay log events. Generating relay diff files from the latest slave succeeded. 172.16.250.133(172.16.250.133:3306): OK: Applying all logs succeeded. Slave started, replicating from 172.16.250.132(172.16.250.132:3306)172.16.250.132(172.16.250.132:3306): Resetting slave info succeeded. Master failover to 172.16.250.132(172.16.250.132:3306) completed successfully.
查看VIP是否转移到了jev2(新master)上面
[root@jev72 ~]#ip a 1 eno16777736: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:0c:29:a1:c8:d2 brd ff:ff:ff:ff:ff:ff inet 172.16.250.132/16 brd 172.16.255.255 scope global eno16777736 valid_lft forever preferred_lft forever inet 172.16.250.188/16 scope global secondary eno16777736 valid_lft forever preferred_lft forever
故障转移后masterha会自动关闭,有利于在生产环境排除问题后再手动启动;
[root@jev74 ~]#masterha_check_status --conf=/etc/masterha/app1.cnf app1 is stopped(2:NOT_RUNNING).
3、注意事项
本实验将VIP设定为非抢占模式,就是防止在故障master修复期间,故障master节点将新master的VIP抢夺回去,导致整个集群无法正常工作;
masterha默认不允许短时间内频繁切换master节点,故切换之后需要删除手工删除/data/masterha/app1/app1.failover.complete,才能进行第二次测试
故障master修复后(或启动新节点),需要基于新的master节点的备份恢复数据,将该节点配置为slave即可,需将IP配置为之前故障master的ip或在app1.cnf中定义;再次启动manager进程集群健康状态即可;
如需将修复的节点,重新启动为master节点,需手动切换master同时将,将目前已有vip节点的keepalived进程杀死,让VIP漂移回去。(也可以通过修改定义master_ip_failover脚本实现VIP漂移)
[root@jev74 ~]# masterha_master_switch --master_state=dead --conf=/etc/masterha/app1.cnf --dead_master_host=172.16.250.132 --new_master_host =172.16.250.132
基于MHA的mysql高可用集群搭建介绍到此;关于master修复详细见【MHA–master在线修复】;
原创文章,作者:Jev Tse,如若转载,请注明出处:http://www.178linux.com/70072

