

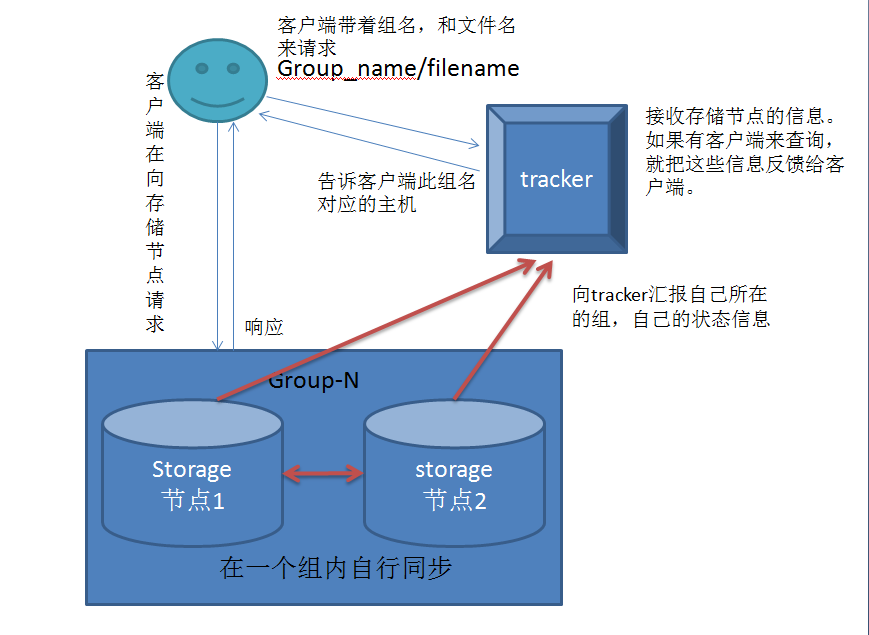
什么是分布式系统?
简单来说,多台主机提供同一个服务,例如负载均衡集群,就是一个分布式系统。
什么是分布式存储?
看看某宝,上面多少图片,如果使用传统的单机存储,需要准备多大的磁盘空间?读写性能如何提升?

上图就是一个分布式存储的结构,此处存储节点不在是磁盘,而是多个主机组成,多个主机内部通信实现数据副本,客户端发来的请求发往前端,前端分发至后端,有点像负载均衡集群中的调度器(此处描述不精确,但便于理解)
分布式存储给我们带来了复杂性。并且还有一个问题
在理论计算机科学中,CAP定理(CAP theorem),又被称作布鲁尔定理(Brewer’s theorem),它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性(Consistence) (等同于所有节点访问同一份最新的数据副本)
- 可用性(Availability)(每次请求都能获取到非错的响应——但是不保证获取的数据为最新数据)
- 分区容错性(Network partitioning)(以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。)
根据定理,分布式系统只能满足三项中的两项而不可能满足全部三项。理解CAP理论的最简单方式是想象两个节点分处分区两侧。允许至少一个节点更新状态会导致数据不一致,即丧失了C性质。如果为了保证数据一致性,将分区一侧的节点设置为不可用,那么又丧失了A性质。除非两个节点可以互相通信,才能既保证C又保证A,这又会导致丧失P性质。
以上摘自维基百科,指出如果要保证数据一致性就会丢失可用性或者分区容错性,但我们在生产环境中可用性是最最最应该保证的,那么就会丢失分区容错性,但分区容错性又是分布式的基础,(我们在集群环境里了解到,在集群环境里如果网络发生了分区,我们应该理解通过投票机制,选举出票数大于半数的主机以保证可用性)相比较此两者,一致性的要求就稍次一些,我们保证他最终一致即可,所以一般架构中我们会选择满足可用性和分区容错性,尽量提高一致性。
ps:说了一大堆,单独理解还好,揉在一起也不是那么容易想明白 ,慢慢来吧。
,慢慢来吧。
分布式的分类
提供存储,并且提供文件系统接口,可以挂载使用的,我们称之为分布式文件系统。
提供存储,但不提供文件系统接口,使用特有的API进行访问,我们称之为分布式存储。
分布式存储的分为两类
数据节点中,元数据集中存储管理,数据节点只存储数据,被称为专用的元数据节点
数据节点中,所有节点均完整存储元数据数据,只存储部分数据,被称为无专用的元数据节点
FastDFS
C语言开发,各节点通过tcp/ip自有协议通信,没有数据库节点,元数据都存储于storage节点,storage节点自行向tracker报告,国人研发。
三个组件
tracker:跟踪服务器,主要负责调度,在内存中记录所有存储组,和存储服务器的状态信息,这里相对mogilefs有个存储组的概念,简单的说就是提供storge的两个或多个节点组成一个组,所以内存占用并不大
storage server: 存储服务器,存储文件和文件属性
client: 客户端,通过专用接口协议与tracker以及storage server进行交互,向tracker提供group_name并发送请求,如果上传,则会接受到storage,响应的group_name 。
fid格式:
group_name/M##/&&/&&/file_name
group_name:存储组的组名;上传完成后,需要客户端自行保存
M##:服务器配置的虚拟路径,与磁盘选项store_path#对应
两级以两位16进制数字命名的目录
文件名,与原文件名并不相同,由storage server 根据特定信息生成,文件名包含,源服务器的IP地址,文件创建时间戳、文件大小、随机数和文件扩展名等
fid是什么? 简单的说 文件有文件名,但是在我们分布式环境中会有很多文件存在,为了提高搜索的效率,把文件名做了hash计算,把计算出来的值前面2位相同的放一个目录,后面2位在此相同的又放一个目录,这样当请求一个文件时,直接对请求的文件名做hash计算,得出前面四位去快速定位位置。
提供两台centos7 一台安装tracker和storage节点 一台只提供storage
安装:
git clone https://github.com/happyfish100/fastdfs.git
作者交由github托管,克隆此节点
git clone https://github.com/happyfish100/libfastcommon.git
依赖此库
接着先安装libfastcommon
./make.sh
./make.sh install
fastdfs目录执行相同操作
完成后

可以看到关于fdfs的一大堆命令。
接着我们进入配置文件目录,复制一份配置文件,并修改配置文件。
[root@localhost fastdfs]# cd /etc/fdfs/
[root@localhost fdfs]# cp tracker.conf.sample tracker.conf
配置文件按需修改这里实验用只修改了日志的目录
fdfs_trackerd /etc/fdfs/tracker.conf start #指明配置文件,启动。
检查端口是否启用,然后就按上面的步骤继续修改storage节点的配置文件
fdfs_storaged /etc/fdfs/storage.conf start #指明配置文件,启动
tracker_server=192.168.20.103:22122 #这里一定记得修改tracker服务器的路径。
检查端口都是否正常启动
第二个节点接着上面的操作重复进行~
fdfs_monitor STORAGE.CONF #指明storage节点的配置文件,可以看到当前节点状况了~
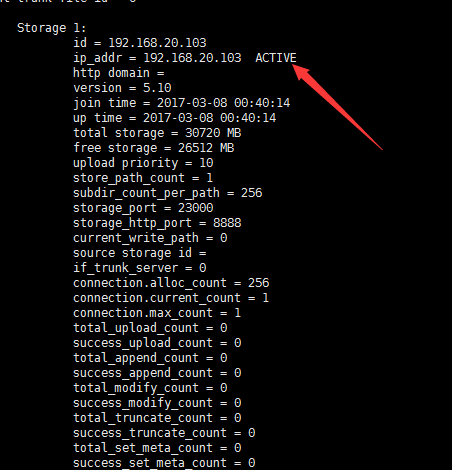
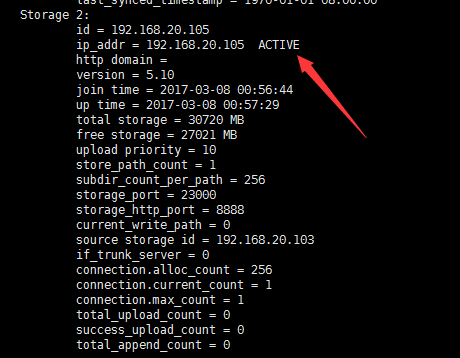
会显示出来一大堆的信息,其他的我们先不管,只管看两个箭头所指,写了active 说明两个节点都准备就绪啦。
group_name=group1 #两个storage节点需配置同一个组
接着我们继续修改客户端的配置文件
tracker_server=192.168.20.103:22122 #同样,记得修改此行指向tracker服务器的地址
接着就可以上传一个文件试试了
[root@localhost fdfs]# fdfs_upload_file client.conf /etc/fstab #指明配置文件,指明上传的文件
group1/M00/00/00/wKgUZ1i-6f-AJiocAAABvCXI6iY2960552 #同时我们可以看到storage节点已经向我们返回了此文件的fid
我们再次去查看监控
[root@localhost fdfs]# fdfs_monitor storage.conf
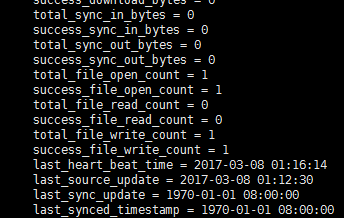
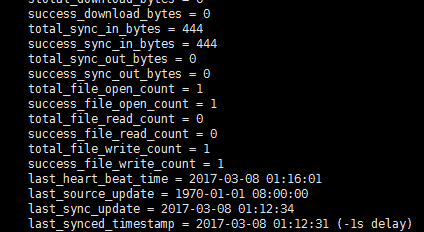
接着可以看到两个存储节点的状态,从返回数据可以看到,我们执行的时候应该是写入到左边一个服务器上了,右边服务器同步了左边的服务器
接着我们来测试一下他的心跳检测状态
[root@localhost fdfs]# vi storage.conf #编辑此配置文件看清楚啊,是storage的配置节点,我们开篇就说了,是storage节点像tracker报告自己的信息.
storage.conf:heart_beat_interval=1 #此行改为1,单位为秒
先看下下载
[root@localhost fdfs]# fdfs_download_file client.conf group1/M00/00/00/wKgUZ1i-6f-AJiocAAABvCXI6iY2960552 /tmp/fstab
[root@localhost fdfs]# cat /tmp/fstab
#
# /etc/fstab
# Created by anaconda on Tue Jan 24 06:51:26 2017
#
# Accessible filesystems, by reference, are maintained under ‘/dev/disk’
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
UUID=6a58d807-3b42-49da-aa3c-f7e0fe97d643 / btrfs subvol=root 0 0
UUID=45df57d0-4193-4c30-bf3f-3601e4b7cac8 /boot xfs defaults 0 0
/dev/sr0 /media iso9660 defaults 0 0
可以看到能正常下载,接着我去关掉那台节点主机~
关掉过后仍能下载,并且马上执行fdfs_monitor 已经显示另一个节点已经offline了~ 就不截图了~自行尝试下吧。
FastDFS和MogileFS适用于相同场景,一般是在有大量>4KB、<512MB图片和文件环境被用来当做解决方案。
原创文章,作者:N24_Ghost,如若转载,请注明出处:http://www.178linux.com/70765


评论列表(1条)
赞~~从原理到架构,再到实战部分~比较详细~加油!