

一:前言
Keepalived使用的vrrp协议方式,虚拟路由冗余协议 (Virtual Router Redundancy Protocol,简称VRRP);Keepalived的目的是模拟路由器的高可用,一般Keepalived是实现前端高可用,常用的前端高可用的组合有,就是我们常见的LVS+Keepalived、Nginx+Keepalived、HAproxy+Keepalived。总结一下,Keepalived中实现轻量级的高可用,一般用于前端高可用,且不需要共享存储,一般常用于两个节点的高可用。
提到高可用我们再来把Heartbeat、Corosync、Keepalived这三个集群组件互相比较一下.

二:keepalived
Keepalived 是一个基于VRRP协议来实现的LVS服务高可用方案,可以利用其来避免单点故障。一个LVS服务会有2台服务器运行Keepalived,一台为主服务器(MASTER),一台为备份服务器(BACKUP),但是对外表现为一个虚拟IP,主服务器会发送特定的消息给备份服务器,当备份服务器收不到这个消息的时候,即主服务器宕机的时候, 备份服务器就会接管虚拟IP,继续提供服务,从而保证了高可用性。
在路由器上配上静态路由就会产生单点故障,那该怎么办呢?VRRP就应用而生了,VRRP通过一竞选(election)协议来动态的将路由任务交给LAN中虚拟路由器中的某台VRRP路由器.
VRRP工作原理, 在一个VRRP虚拟路由器中,有多台物理的VRRP路由器,但是这多台的物理的机器并不能同时工作,而是由一台称为MASTER的负责路由工作,其它的都是BACKUP,MASTER并非一成不变,VRRP让每个VRRP路由器参与竞选,最终获胜的就是MASTER。MASTER拥有一些特权,比如,拥有虚拟路由器的IP地址,我们的主机就是用这个IP地址作为静态路由的。拥有特权的MASTER要负责转发发送给网关地址的包和响应ARP请求。
VRRP通过竞选协议来实现虚拟路由器的功能,所有的协议报文都是通过IP多播(multicast)包(多播地址224.0.0.18)形式发送的。虚拟路由器由VRID(范围0-255)和一组IP地址组成,对外表现为一个周知的MAC地址。所以,在一个虚拟路由 器中,不管谁是MASTER,对外都是相同的MAC和IP(称之为VIP)。客户端主机并不需要因为MASTER的改变而修改自己的路由配置,对客户端来说,这种主从的切换是透明的。
在一个虚拟路由器中,只有作为MASTER的VRRP路由器会一直发送VRRP通告信息(VRRPAdvertisement message),BACKUP不会抢占MASTER,除非它的优先级(priority)更高。当MASTER不可用时(BACKUP收不到通告信息), 多台BACKUP中优先级最高的这台会被抢占为MASTER。这种抢占是非常快速的(<1s),以保证服务的连续性。由于安全性考虑,VRRP包使用了加密协议进行加密
三:为什么要用keepalived+lvs
lvs是一个在四层上实现后端realserver的负载均衡的集群,lvs遗留下两个问题,一个是lvs的单点故障;第二个是lvs不能检测后端realserver的健康状态检查。
解决lvs的单点故障就用到了高可用集群:
①、可以是heartbeat+ldirectord这种重量级的;
②、可以是keepalived+lvs这种轻量级的解决方案。
解决lvs不能检测后端realserver的健康状态也后很多种方法:
①、可以在lvs上写脚本ping后端realserver的ip地址,ping几次发现ip地址ping不通则在ipvs规则里面删除,当后端服务器可以ping了,则把后端realserver添加到ipvs规则里面。
②、可以在lvs上写脚本请求后端realserver的测试几次网页文件,查看状态码是否为200,不是则在ipvs规则里面清楚,当测试网页返回的状态吗是200之后,则把后端realserver添加到ipvs规则里面
③、以上两种方法都是依赖于脚本,keepalived的出现解决了不依赖于脚本,也可以对后端realserver的健康状态检查,keepalived的配置文件里面可以自行生成ipvs的规则,并且自行检测后端realserver的状态,当后端realserver不能提供服务了,keepalived会自行将其在ipvs规则里面删除,当后端realserver可以提供服务了,又自行的在ipvs规则里面添加。
三:配置keepalived实现HTTP高可用
1) 环境准备
CentOS 6.5 X86_64
ipvsadm.x86_64 0:1.25-10.el6
keepalived.x86_64 0:1.2.7-3.el6
httpd-2.2.15-29.el6.centos.x86_64
2)试验拓扑图

试验拓扑图中VIP为172.16.16.7.节点node1为172.16.16.1,节点node2为172.16.16.5
3)配置master
4)将配置文件同步到slave
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
scp /etc/keepalived/keepalived.conf root@172.16.16.5:/etc/keepalived/
修改配置文件
global_defs
{
notification_email
{
stu16@llh.com #接收邮件地址
}
notification_email_from kanotify@magedu.com #发送邮件地址
smtp_connect_timeout 3
smtp_server 127.0.0.1
router_id LVS_DEVEL
}
vrrp_script chk_mantaince_down { #定义检测机制
script “[[ -f /etc/keepalived/down ]] && exit 1 || exit 0”
interval 1 #每个多长时间检测一次
weight -2 #当在/etc/keepalived/下创建一个down文件时执行下面的命令权重减2.
fall 3 #从正常到失败检测几次完成
raise 3 #从失败到正常需要检测几次
}
vrrp_instance VI_1 {
interface eth1
state BACKUP # BACKUP for slave routers #此处修改为BACKUP
priority 100 # 100 for BACKUP #此处修改为100
virtual_router_id 16 #主机routeID,
garp_master_delay 1
authentication {
auth_type PASS
auth_pass password #输入验证密码
}
track_interface {
eth0 #配置IP地址所在的网卡
}
virtual_ipaddress {
172.16.16.7/16 dev eth0 label eth0:0 #配置的IP地址
}
track_script { #调用检测机制
chk_mantaince_down
}
notify_master “/etc/rc.d/init.d/httpd start” # 当成为master时就启动http服务
notify_backup “/etc/rc.d/init.d/httpd stop” # 当成为backup时就关闭http服务
notify_fault “/etc/rc.d/init.d/httpd stop”
}
|
5)启动keepalive
|
1
2
3
4
|
[root@node1 ~]# service keepalived start
正在启动 keepalived: [确定]
[root@node2 ~]# service keepalived start
正在启动 keepalived: [确定]
|
四:keepalive+lvs 实现LVS双主高可用
1)试验拓扑图

2)配置RIP1服务
|
1
2
3
4
5
6
7
8
9
10
|
因为RIP服务器配置的有VIP地址所以外面有请求VIP时他也会进行相应,而我们这里是为了实现DR转发,不能让他进行响应,我们需要对RIP的端口信息进行隐藏。
echo 1 > /proc/sys/net/ipv4/conf/eth0/arp_ignore #忽略其他端口发来的请求信息
echo 2 > /proc/sys/net/ipv4/conf/eth0/arp_announce #不广播自己的端口信息
echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore
echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce
ifconfig eth0 192.168.16.2/24 up
ifconfig lo:0 172.16.16.7 netmask 255.255.255.255 broadcast 172.16.16.7
route add -host 172.16.16.7 dev lo:0 响应的信息通过lo:0端口 ,为了使响应的IP地址为VI
ifconfig lo:1 172.16.16.8 netmask 255.255.255.255 broadcast 172.16.16.8
route add -host 172.16.16.8 dev lo:1
|
3)配置RIP2服务
|
1
2
3
4
5
6
7
8
9
|
echo 1 > /proc/sys/net/ipv4/conf/eth0/arp_ignore #忽略其他端口发来的请求信息
echo 2 > /proc/sys/net/ipv4/conf/eth0/arp_announce #不广播自己的端口信息
echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore
echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce
ifconfig eth0 192.168.16.3/24 up
ifconfig lo:0 172.16.16.7 netmask 255.255.255.255 broadcast 172.16.16.7
route add -host 172.16.16.7 dev lo:0 响应的信息通过lo:0端口 ,为了使响应的IP地址为VI
ifconfig lo:1 172.16.16.8 netmask 255.255.255.255 broadcast 172.16.16.8
route add -host 172.16.16.8 dev lo:1
|
4)配置master
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
|
global_defs
{
notification_email
{
linuxedu@foxmail.commageedu@126.com
}
notification_email_from kanotify@magedu.com
smtp_connect_timeout 3smtp_server 127.0.0.1
router_id LVS_DEVEL
}
vrrp_script chk_schedown
{
script “[[ -f /etc/keepalived/down ]] && exit 1 || exit 0”
#创建down文件权重减2
interval 2
weight -2
}
vrrp_instance VI_1
{
interface eth0
state MASTER #此节点为主节点
priority 101
virtual_router_id 51
garp_master_delay 1
authentication
{
auth_type PASS
auth_pass password
}
track_interface
{
eth0
}
virtual_ipaddress
{
172.16.16.7/16 dev eth0 label eth0:0 #配置对外的VIP地址 }
track_script
{
chk_schedown
}
}
vrrp_instance VI_2
{
interface eth0
state BACKUP #此节点为被节点
priority 100
virtual_router_id 50
garp_master_delay 1
authentication {
auth_type PASS
auth_pass 12345678
}
track_interface {
eth0
}
virtual_ipaddress {
172.16.16.8/16 dev eth0 label eth0:1 #配置对外的VIP地址
}
track_script {
chk_schedown
}
}
virtual_server 172.16.16.7 80 #配置一个VIP 工作在TCP的80端口上
{
delay_loop 6 #lb_algo rr #负载均衡的调度算法
lb_kind DR #工作在DR模型上
persistence_timeout 50 #是否启用IPVS持久连接
protocol TCP #采用的是TCP协议
# sorry_server 192.168.16.2 1358 #所有服务挂了 ,出现的提示页面.要在这台服务器上开启http服务
real_server 192.168.16.2 80 #后面RIP地址
{
weight 1 #权重
HTTP_GET
{
url
{
path /
status_code 200 #取得主页面的状态,状态码为200就意味着请求成功;也可写入md5码,但要制定静态码
}
connect_timeout 3 #每次测试3秒
nb_get_retry 3 #测试次数
delay_before_retry 3 #测试失败在测试3次
}
}
real_server 192.168.16.3 80
{
weight 1
HTTP_GET
{
url
{
path /
status_code 200
}
connect_timeout 3nb_get_retry 3delay_before_retry 3
}
}
}
virtual_server 172.16.16.8 80 #配置一个VIP 工作在TCP的80端口上
{
delay_loop 6 #
lb_algo rr #负载均衡的调度算法
lb_kind DR #工作在DR模型上
#persistence_timeout 50 #是否启用IPVS持久连接,这项要注销.连接50S才会切换
protocol TCP #采用的是TCP协议
# sorry_server 192.168.16.2 1358 #所有服务挂了 ,出现的提示页面.要在这台服务器上开启http服务
real_server 192.168.16.2 80 #后面RIP地址
{
weight 1 #权重
HTTP_GET
{
url
{
path /
status_code 200 #取得主页面的状态,状态码为200就意味着请求成功;也可写入md5码,但要制定静态码
}
connect_timeout 3 #每次测试3秒
nb_get_retry 3 #测试次数
delay_before_retry 3 #测试失败在测试3次
}
}
real_server 192.168.16.3 80
{
weight 1
HTTP_GET
{
url
{
path /
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
|
5)配置backup
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
|
global_defs
{
notification_email
{
linuxedu@foxmail.commageedu@126.com
}
notification_email_from kanotify@magedu.com
smtp_connect_timeout 3smtp_server 127.0.0.1
router_id LVS_DEVEL
}
vrrp_script chk_schedown
{
script “[[ -f /etc/keepalived/down ]] && exit 1 || exit 0”
#创建down文件权重减2
interval 2
weight -2
}
vrrp_instance VI_1
{
interface eth0
state BACKUP #此节点为被节点
priority 100
virtual_router_id 51
garp_master_delay 1
authentication
{
auth_type PASS
auth_pass password
}
track_interface
{
eth0
}
virtual_ipaddress
{
172.16.16.7/16 dev eth0 label eth0:0 #配置对外的VIP地址 }
track_script
{
chk_schedown
}
}
vrrp_instance VI_2
{
interface eth0
state MASTER #此节点为主节点
priority 101
virtual_router_id 50
garp_master_delay 1
authentication {
auth_type PASS
auth_pass 12345678
}
track_interface {
eth0
}
virtual_ipaddress {
172.16.16.8/16 dev eth0 label eth0:1 #配置对外的VIP地址
}
track_script {
chk_schedown
}
}
virtual_server 172.16.16.7 80 #配置一个VIP 工作在TCP的80端口上
{
delay_loop 6 #lb_algo rr #负载均衡的调度算法
lb_kind DR #工作在DR模型上
persistence_timeout 50 #是否启用IPVS持久连接
protocol TCP #采用的是TCP协议
# sorry_server 192.168.16.2 1358 #所有服务挂了 ,出现的提示页面.要在这台服务器上开启http服务
real_server 192.168.16.2 80 #后面RIP地址
{
weight 1 #权重
HTTP_GET
{
url
{
path /
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
real_server 192.168.16.3 80
{
weight 1
HTTP_GET
{
url
{
path /
status_code 200
}
connect_timeout 3nb_get_retry 3delay_before_retry 3
}
}
}
virtual_server 172.16.16.8 80 #配置一个VIP 工作在TCP的80端口上
{
delay_loop 6
lb_algo rr
lb_kind DR
#persistence_timeout 50
protocol TCP
# sorry_server 192.168.16.2 1358
real_server 192.168.16.2 80 #后面RIP地址
{
weight 1 #权重
HTTP_GET
{
url
{
path /
status_code 200
}
connect_timeout 3 #每次测试3秒
nb_get_retry 3 #测试次数
delay_before_retry 3 #测试失败在测试3次
}
}
real_server 192.168.16.3 80
{
weight 1
HTTP_GET
{
url
{
path /
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
|
5)启动keepalive
五:keepalive+nginx 实现nginx的高可用
keepalive+nginx介绍
keepalive通过VRRP协议可以让两个或多个路由器实现接口地址漂移,达到多个设备对外地址一致性,进入让用户无法感知设备出现故障带来的无法访问服务的情况。
keepalive最初设计为lvs所设计,keepalive内置就可以配置lvs的所有功能,自动判断lvs出现故障的情况下,地址漂移到备用lvs上,自动判断后端服务器集群出现故障,从lvs列表中移除该服务器集群。
|
keepalive+lvs |
检测lvs故障 |
处理方式 |
|
lvs1出现故障 |
每隔1秒发送通告报文 |
VIP漂移至lvs2 |
|
后端服务器集群故障 |
自定义检测后端服务器提供的服务 |
从ipvsadm列表中移除集群中的服务器节点 |
然而在nginx上,我们需要keepalive提供的功能为,当nginx前端调度器出现故障,可以把VIP地址漂移到另一台备用的nginx上。或到nginx服务处于关闭状态,可自动降低优先级,把VIP地址漂移到备用nginx上。
|
keepalive+nginx |
检测方式 |
处理方式 |
|
nginx服务器故障 |
每隔1秒发送通告报文 |
VIP漂移至备用nginx |
|
nginx服务故障 |
自定义脚本检测nginx服务是否运行 |
降低主节点优先级达到VIP漂移至nginx |
|
后端服务器集群故障 |
keepalive无法判断 |
需要nginx提供的策略去判断 |
总结:keepalive+nginx
keepalive+nginxs实现的只能是使用VIP地址在nginx上漂移,别无其他作用,需要检测后端群集是否正常需要nginx提供的策略去判断,所以以下案例只能测试在nginx出现故障,或nginx进程停止运行后,能不能实现VIP漂移,需要测试集群出现故障,需要nginx的策略配置,在此案例中不详细介绍,参考nginx代理群集案例。
实验拓扑图:
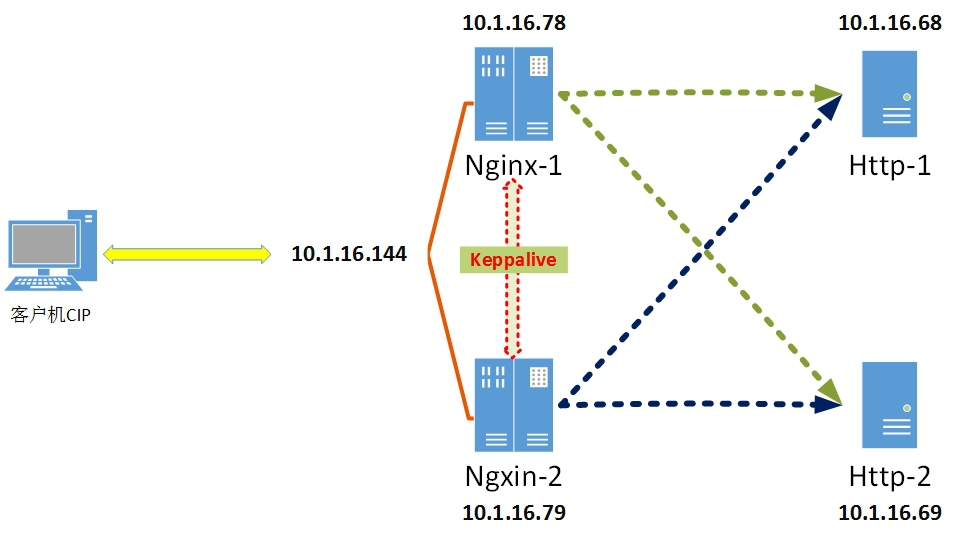
实验环境介绍
|
服务器集群 |
集群节点 |
角色 |
IP配置 |
|
nginx高可用集群 |
nginx-1 |
主节点 |
10.1.16.78 |
|
nginx-1 |
备用节点 |
10.1.16.79 |
|
|
web负载均衡集群 |
http-1 |
提供web页面1 |
10.1.16.68 |
|
http-2 |
提供web页面2 |
10.1.16.69 |
|
|
web服务VIP 10.1.16.144 |
|||
※·http-1配置
(配置一个简单的web站点,并启动服务) yum -y install httpd echo “This is my master web site : http://10.1.16.68” > /var/www/html/index.html service httpd start 测试web1页面是否正常: [root@http_1 ~]#curl 10.1.16.68 This is my master web site : http://10.1.16.68
※·http-2配置
(配置一个简单的web站点,并启动服务)
yum -y install httpd echo “This is my master web site : http://10.1.16.68” > /var/www/html/index.html service httpd start 测试web2页面是否正常 [root@http_1 ~]#curl 10.1.16.69 This is my master web site : http://10.1.16.69※·nginx-1代理配置yum -y install nginx-1.10.0-1.el7.ngx.x86_64.rpm
vim /etc/nginx/nginx.conf
http {
...................... upstream webserver { server 10.1.16.68:80; server 10.1.16.69:80; } ................................ include /etc/nginx/conf.d/*.conf; } vim /etc/nginx/conf.d/default.conf server { listen 80; server_name localhost; ............................. location / { index index.html index.htm; proxy_pass http://webserver; } ............................※·nginx-2代理配置yum -y install nginx-1.10.0-1.el7.ngx.x86_64.rpmvim /etc/nginx/nginx.conf
http {
...................... upstream webserver { server 10.1.16.68:80; server 10.1.16.69:80; } ................................ include /etc/nginx/conf.d/*.conf; } vim /etc/nginx/conf.d/default.conf server { listen 80; server_name localhost; ............................. location / { index index.html index.htm; proxy_pass http://webserver; } ............................※·nginx-1的keepalive配置(主节点)! Configuration File for keepalivedglobal_defs { notification_email { root@localhost } notification_email_from keepnainx@localhost smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id nginx_1 vrrp_mcast_group4 224.0.100.16 } vrrp_script chk_nginx_down { script "killall -0 nginx && exit 0 || exit 1" interval 1 weight -5 } vrrp_instance nginx_ha { state MASTER interface eno16777736 virtual_router_id 44 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 123456 } virtual_ipaddress { 10.1.16.144 dev eno16777736 label eno16777736:0 } track_script { chk_nginx_down}※·小结keepalive和lvs结合非常的好用,可以检查后端集群的web健康状态,动态的在ipvs中删除或添加集群中的服务器,keekalive和lvs结合非常紧密,可以通过自身管理lvs的调度规则。keeplive和nginx的配置,可以实现nginx的高可用,实现的方式为VIP地址的动态转移,但是无法判断后端的群集中服务器的健康状态,需要nginx自身的规则去管理。通过keeplive的脚本监控功能,可以管理本机上相关的nginx进程是否正常运行。 通过keepalive与nginx的实验,keepalive实现其他服务的高可用也是没有问题的,通过相关的脚本可以监控服务的健康状态。原创文章,作者:liudehua666,如若转载,请注明出处:http://www.178linux.com/75724
