文本处理工具:
more:分页查看文件
less:分页控制显示文件
head 查看文件的前几行
-n 3 显示前三行
-3 显示前三行
-c 指定显示的字节数
一个汉字占用三个字节
tail 查看显示文件的后几行
-n 3 显示后几行
-c 显示最后的指定字节数
-f 跟踪显示更新
cut [0ption] [file]
-d: 指明分隔符,默认为tab
-f:指明第几列
#:第#个字段
#,#[,#]:离散的多个字段,如1,3,6
#-#:连续的多个字段,如1-5
混合使用:1-4,7 1到4列和第7列
-c:按字符切割
–output-delimiter=STRING:指定输出分隔符
paste 合并两个文件同行号的列到一行
paste [option] [file]
-d 分隔符:指定分隔符,默认用tab

-s:所有的行合并到一行显示
paste f1 f2
paste -s f1 f2

wc 计数单词总数、行总数、字节总数和字符总数
可以对文件或STDIN 中的数据运行
wc story.txt
39 237 1901 story.txt
行数 字数 字符数
使用 -l 来只计数行数
使用 -w 来只计数单词总数
使用 -c 来只计数字节总数
使用 -m 来只计数字符总数
sort 文本排序
把整理过的文本显示在STDOUT ,不改变原始文件
sort [options] file(s)
常用选项
-r 倒序(由上至下)排列
-n 执行按数字大小排列
-f 选项忽略(fold )字符串中的字符大小写
-u (独特,unique )删除输出中的重复行
-t c: 指定c为字段分割符
-k X:指定的c字符分割的X列排序
unip行
uniq [OPTION]… [FILE]…
-c: 显示每行重复出现的次数
-d: 仅显示重复过的行
-u: 仅显示不曾重复的行
连续且完全相同方为重复
常和sort 命令一起配合使用:
sort userlist.txt | uniq -c
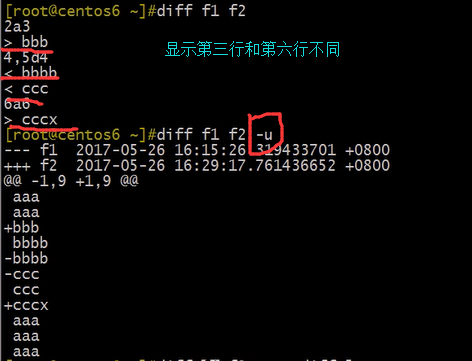
diff:比较两个文件
比较两个文件之间的区别
diff foo.conf-broken foo.conf-works
diff 命令的输出被保存在一种叫做“补丁”的文件中
使用 -u 选项来输出“统一的(unified )”diff 格式文件,最适用于补丁文件。
patch 复制在其它文件中进行的改变(要谨慎使用)
适用 -b 选项来自动备份改变了的文件
diff -u foo.conf-broken foo.conf-works > foo.patch
patch -b foo.conf-broken foo.patch

grep :文本过滤( 模式:pattern) 工具
grep, egrep, fgrep (不支持正则表达式 搜索)
sed :stream editor 文本编辑工具
awk :Linux 上的实现gawk,文本报告生成器
grep:
作用:文本搜索工具,根据用户指定的“模式”对目标文本逐行进行匹配检查;打印匹配到的行模式:由正则表达式字符及文本字符所编写的过滤条件.
选项:
–color=auto: 对匹配到的文本着色显示

-v: 显示不被pattern 匹配到的行
-i:忽略字符大小写
-n:显示匹配的行号
-c: 统计匹配的行数
-o: 仅显示匹配到的字符串
-q: 静默模式,不输出任何信息
-A #: after, 后#行
-B #: before, 前#行
-C # :context, 前后各#行

-e :实现多个选项间的逻辑or 关系
grep –e ‘cat ’ -e ‘dog’ file

-w :匹配 整个单词
-E :使用ERE
-F :相当于fgrep
正则表达式
由一类特殊字符及文本字符所编写的模式,其中有些字符(元字符)不表示字符字面意义,而表示控制或通配的功能。
元字符分类:字符匹配、匹配次数、位置锚定、分组。
基本正则表达式元字符:
匹配次数:用在要指定次数的字符后面,用于指定前面的字符要出现的次数
字符匹配:
. 匹配任意单个字符
[] 匹配指定范围内的任意单个字符
[^] 匹配指定范围外的任意单个字符
[:alnum:] 字母和 数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] 小写字母 [:upper:] 大写字母
[:blank:] 空白字符(空格和制表符)
[:space:] 水平和垂直的空白字符(比[:blank:] 包含的范围广)
[:cntrl:] 不可打印的控制字符(退格、删除、警铃…) )
[:digit:] 字 十进制数字 [:xdigit:] 十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
正则表达式匹配次数:
匹配次数:用在要指定次数的字符后面,用于指定前面的字符要出现的次数
* 匹配 前面的字符任意次,包括0次 次
贪婪模式:尽可能长的匹配
.* 任意 长度的任意字符

\? 匹配 其前面的字符0 或1次
\+ 匹配 其前面的字符至少1次

\{n\} 匹配前面的字符n次

\{m,n\} 匹配 前面的字符至少m 次,至多n次

\{,n\} 匹配前面的字符至多n次
\{n,\} 匹配前面的字符至少n次
位置锚定:定位出现的位置
^ 行首锚定,用于模式的最左侧
$ 行尾锚定,用于模式的最右侧


^PATTERN$ 用于模式匹配整行
^$ 空行
^[[:space:]]*$ 空白行

\< 或\b 词首锚定,用于单词模式的左侧
\> 或\b 词尾锚定;用于单词模式的右侧
\<PATTERN\>



分组:\(\) 将一个或多个字符捆绑在一起,当作一个整体进行处理,如:\(xy\)\+

分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名方式为: \1, \2, \3,
\1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符
示例: \(ab\+\(xy\)*\)
\1 :ab\+\(xy\)*
\2 :xy
后向引用:引用前面的分组括号中的模式所匹配字符,而非模式本身

或则:\|
示例:a\|b: a 或b C\|cat: C 或cat \(C\|c\)at:Cat 或cat
egrep及扩展的正则表达式
egrep = grep -E
egrep [OPTIONS] PATTERN [FILE…]
扩展正则表达式的元字符:
字符匹配:
. 任意单个字符
[] 指定范围的字符
[^] 不在指定范围的字符
扩展正则表达式:
次数匹配:
* :匹配前面字符任意次
?: 0 或1次
+ :1 次或多次
{m} :匹配m次
{m,n} :至少m ,至多n次
位置锚定:
^ : 行首
$ : 行尾
\<, \b : 语首
\>, \b : 语尾
分组:()
后向引用:\1, \2, …
或者:
a|b: a 或b
C|cat: C 或cat
(C|c)at:Cat 或cat
fgrep:不支持正则表达式
原创文章,作者:danran,如若转载,请注明出处:http://www.178linux.com/77290



