

正则表达式及文本处理
通俗点说,正则表达式就是处理字符串的方法,更加快速简洁的代表各个要求参数,一般用于描述字符排列和匹配模式的一种语法规则,通过正则表达式一些特殊符号的辅助,让用户轻易的查找、删除、替换一些字符串的处理程序。( ps:正则表达式和通配符不一样,通配符代表的是bash接口的一个功能,但正则表达式是一种字符串处理的表达方式,两者一定要分清楚。)
正则表示支持很多命令,例如:grep,sed.awk,vim,less,nginx,varnish等等命令,它分为两类:
-
一种是基本正则表达式(BRE)
-
一种是扩展正则表达式(ERE)
下面介绍下基本正则表达式的元字符,分字符又分四类:
-
字符匹配
-
匹配次数
-
位置锚定
-
分组
字符匹配
- . 表示任意单个字符


- [ ] 表示匹配范围内的任意单个字符([abc]r 相当于r一个个匹配里面的,如ar,br,cr)
例如:

- [^ ] 表示匹配范围外的任意单个字符
- [:alpha:] 任意一个字母(相当于a-zA-Z)
- [:upper:] 任意一个大写字母(相当于A-Z)
- [:lower:] 任意一个小写字母(相当于a-z)
- [:digit:] 任意一个数字(相当于0-9)
- [:space:] 水平和垂直的空白字符(比blank包含的更多)
- [:blank:] 空白字符(空格和制表符)
- [:punct:] 标点符号
- [:alnum:] 任意字母和数字(相当于0-9a-zA-Z)
- [:print:] 可打印字符
例如:字符的使用

(ps:用的时候记得加[],例如:[[:alnum:]]或者[0-9a-zA-Z]这样用,当然最好还是用[[:alnum:]]这种命令,它会比[a-z0-9A-Z]更为确定一些,在这里汉字也为字母)
匹配次数
- * 表示*号前面的一个字符的0-N次(它有一个贪婪模式,会尽量匹配最长)
例如:

- .* 表示任意多个长度的字符
- \? 表示\?符号前的字符0-1次
例如:

- \+ 匹配\+前的字符至少1次
例如:
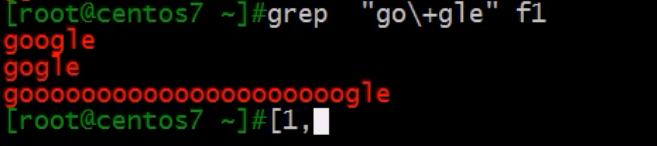
- \{m,n} 表示\{m,n\}符号前的字符的m-n次
- \{m\} 表示{m\}符号前的字符m次
- \{n,\} 表示匹配前面字符至少n次
- \{,n} 表示匹配前面字符最多n次
例如:

(ps: \的意义是转义字符,意思就是将一些有特殊符号的意义去除)
位置锚定
- ^ 之后接字符 表示^ 之后的字符出现在行首
例如:

- $ 之前接字符 表示$之前的字符出现在行尾
例如:

-
\> 表示\> 符号之后的字符出现在单词的尾部
-
\< 表示\< 之前的字符出现在单词的首部
-
\<字符 \> 表示只有小于号和大于号之间的字符
例如:

(ps:\b 同样可以用于匹配单词位置,只不过有时候怕不好区别,最好还是用大于小于,这样也方便看清)。
分组
- 分组简单来说就是\(\)用一个命令将一个或者多个字符捆绑在一起,当成一个整体进行处理,如:\(abc)+
例如:

-
分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名方式为: \1,\2,\3, …,\1表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符
\示例:grep \(r..t\).*\(a..b\) \1 \2
\1 :r..t
\2 :a..b
例如:第一个括号为\(r..t\) 那么\1也是r..t

- 或者:\|
示例:a\|b: a或b
C\|cat: C或cat
\(C\|c\)at:Cat或cat
例如:

{ps:有时候命令需要整体括起来,加双引号“”}
扩展正则表达式
扩展正则表达式和基本正常表达式的功能是类似的,包括基本正则表达式的字符匹配都是相同的,扩展正则表达式照样可以使用,不过扩展正则表达式和基本正则表达式还是有所不同,可以说在某些时候更加简单。
刚刚我们用的匹配次数、位置锚定、分组的命令有非常多的\,如果使用多了也会看得眼花缭乱,自己有时候也会输入错误或者忘记、漏掉\。
这里我只列出和基本正则有区别的命令:
字符匹配
(和基本正则一模一样)
匹配次数
-
? 表示?符号前的字符0-1次(在基本正则里? 表示?符号前的字符0-1次)
- * 表示+前面的字符至少1次 (在基本正则里\+ 匹配\+前的字符至少1次)
例如:

-
{m,n} 表示{m,n}符号前的字符的m-n次
-
{m} 表示{m}符号前的字符m次
-
{n,} 表示匹配前面字符至少n次
-
{,n} 表示匹配前面字符最多n次
位置锚定
(和基本正则一模一样)
分组
(和匹配次数一样,把\全部去掉就行了)
grep (r..t).*(a..b) 1 2
\1 :r..t
\2 :a..b
(ps:\1还是要加\号的)
练习
在ifconfig 中找出其ip地址的命令。
ifconfig|grep -E “(<([1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])>.){3}<([1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5]>)”
例如:

grep 的常用选项
命令说明:按行处理,输出文件中包含搜索字符串的所有行。(按关键字搜索)
格式:grep [-acinv] ‘搜索字符串’ filename
-
grep 选取命令,查找
-
grep -i 忽略字符的大小写
-
grep –colour 高亮显示搜索结果
-
grep -o z 表示只显示匹配中的字符
-
grep -v 表示显示匹配外的字符行
-
grep -E 表示扩展正则表达式
-
grep -A 数字 表示匹配的字符所对应的行数的后几行将要被显示出来
-
grep -B 数字 表示匹配的字符所对应的行数的钱几行将要被显示出来
-
grep -C 数字 表示匹配的字符所对应的前后几行将要被显示出来
-
grep -E =egrep (变量)
例子
- 在文件a.txt中搜索包含字符串good或glad的行:
grep -E 'g(oo|la)d' a.txt
- 找到以字母a结尾的单词:
grep -E 'a[[:blank]]' a.txtgrep -E 'a\\b' a.txt
文件查看命令:
cat的常用选项
命令说明:按行处理,将一行消息的某段切出来。(查看文本文件)
格式:cut -d ‘分割字符’ -f fields
-
cut 查看文本文件
-
cut -A 显示所有
-
cut -E 显示每行的结束符
-
cut -n 加行号
-
cut -b 减去空白行(有字符的不减去,如空格,tab键)
-
cut -s 压缩相邻的空行
分页查看
-
more 分页显示(b向回翻页)
-
more -d 显示翻页及退出提示
-
less 分页显示(一页页查看文件或者输出,可以回翻,可以搜索)
(ps:man使用的就是less分页命令)
head的常用选项
-
head 查看命令(不加参数默认查看前10行)
-
head -n 3 查看命令前3行(不加n直接加数字也可以)
-
head -c 3 查看命令前3个字节(回车算一个字节,汉字3个字节)
tail的常用选项
-
tail 查看命令(不加参数默认查看后10行)
-
taul -c 3 查看命令从后开始3个字节
-
tail -f 追踪查看文件最新追加的内容是否有变化(一般用于日志监控)
-
tail -n 3 查看命令从后开始3行
(ps:& 可放置后台执行)
wc 的常用选项
命令说明:一般用于文本数据统计
格式:1. 行 2. 单词 3. 字节 4. 文件名
-
wc -l 统计行数
-
wc -w 统计单词
-
wc -c 统计字节
-
wc -m 统计字符
sort 的常用选项
-
sort -t: 指定:为分隔符(一般配合k使用,:可以更换各种分隔符, . / : % $ # 等)
-
sort -k: 指定:为分隔符的第几列排序
-
sort -n 数字排序
-
sort -r 倒序
-
sort -f 忽略大小写
-
sort -u 删除重复行
uniq 的常用选项
-
uniq 合并相邻的重复行
-
uniq -c 显示重复的次数
-
uniq -d 只显示重复过的行
-
uniq -u 只显示不重复的行
(ps: 连续并且完全相同才为重复)
原创文章,作者:Az2h1丶,如若转载,请注明出处:http://www.178linux.com/77908
