

cat tac rev more less head tail
cut paste wc sort uniq diff
grep 正则表达式 egrep 扩展正则表达式
1. cat tac rev more less
(1)cat 查看
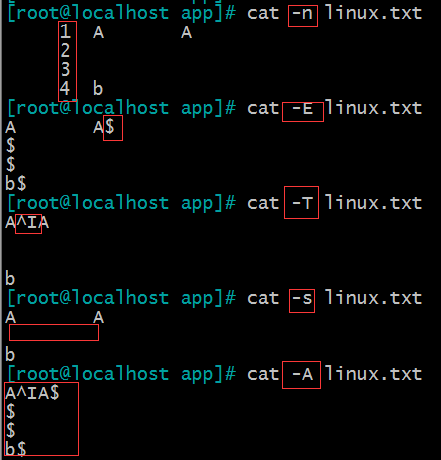
-E 显示$ 换行符
-T 显示TAB
-v 显示非打印字符
-n 显示行号
-s 将连续的重复空行变成一行
-A = -vET
(2)tac 只行颠倒,每行的内容不颠倒
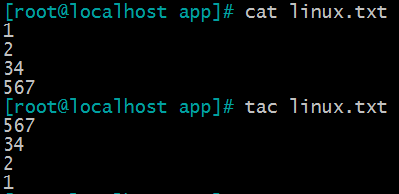
(3)rev

(4)分页查看文件内容
more: 分页查看文件,空格翻页,q退出
less :一页一页地查看文件
/ 文本 搜索文本
n 跳到下一个 N跳到上一个
less 命令是man 命令使用的分页器
2. head tail
(1)head (默认显示前10行)
-n 行号 显示前n行 或 -行号 显示前n行
-c 字节数 显示前n个字节
(2)tail (默认显示后10行)
-n 行号 显示后n行 或 -行号 显示后n行
-c 字节数 显示后n个字节
-f 动态显示
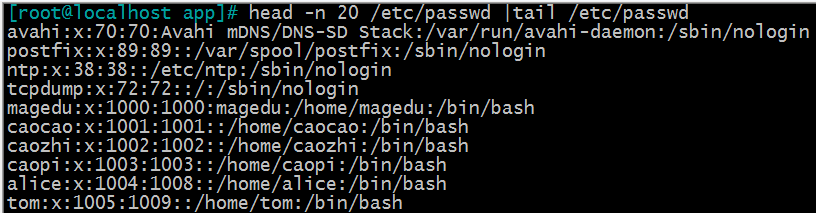
例1:显示/etc/passwd文件的第11行至第20行
head -n 20 /etc/passwd |tail
例2:利用 cat /dev/urandom 生成10位字符长度的随机密码(包含大小写字母及数字)
cat /dev/urandom | tr -d -c [:alnum:] | head -c 10 ;echo

3. cut paste wc
(1)cut 切
-d 指定分隔符
-f n[,n-r] 选取第几列
–output-delimiter 指定输出符
例1:cut -d: -f1,3 –output-delimiter=’.’ /etc/passwd

例2:显示当前主机第一个网卡的IP地址
ifconfig |head -n 2| tail -n 1| tr -s ‘ ‘ : |cut -d: -f3

例3:查出/app目录的空间使用量
df|tr -s ” ” % |head -n 4 |tail -n 1 |cut -d% -f5
df |head -n 8 |tail -n 1 |cut -c 44-46

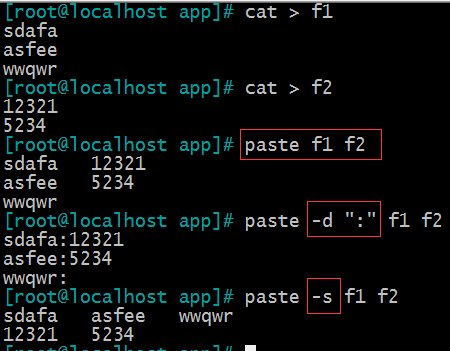
(2)paste 粘合
paste f1 f2 [f3]
paste -s f1 将文件内容变成一行显示 ,也可以用 tr ‘\n’ ‘\t’ 实现
paste -d “” f1 f2 [f3] 合并后的分隔符,默认TAB
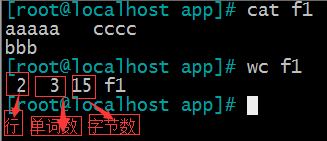
(3)wc: word count 统计
-m 字符数 一个汉字算1个字符
-c 字节 一个汉字算3个字节
-l 行数
-w 单词数
wc 行数 单词数 字节
4. sort uniq diff
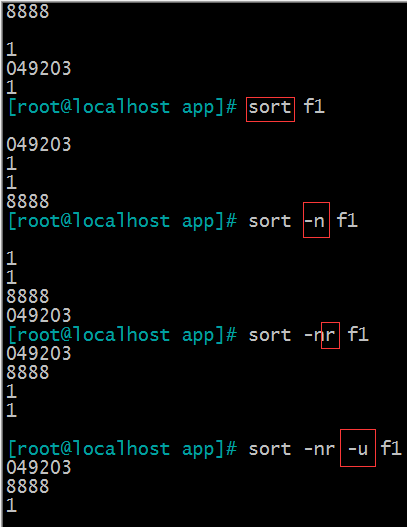
(1)sort 排序
-r 执行反方向(由上至下)整理
-n 执行按数字大小整理
-u 选项(独特,unique)删除输出中的重复行
-t c 选项使用c做为字段界定符
-k X 选项按照使用c字符分隔的X列来整理能够使用多次
-f 选项忽略(fold)字符串中的字符大小写
(2)uniq 去除连续的重复行
要想去除非连续的行,先用sort排序
-c 显示连续重复的次数
-d 仅显示重复的次数
-u 仅显示不曾重复的行

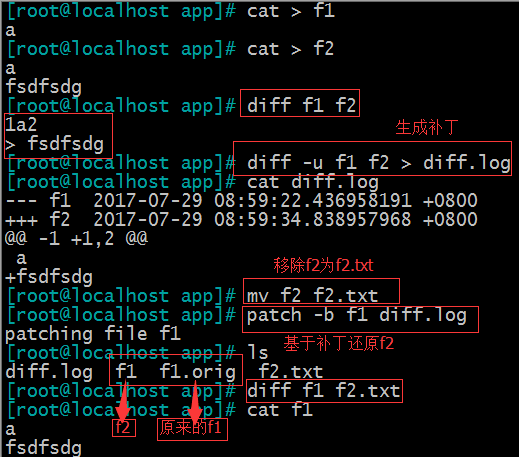
(3)diff f1 f2 仅比较区别
diff -u f1 f2 > diff.log 生成补丁
mv f2 f2.rm 相当于删除了文件。
patch -b f1 diff.log 通过补丁还原文件 ,生成的f1为原来的f2,fi.orig为原f1
mv f1 f2 还原原始的新文件名
mv f1.orig f1 还原原始的旧文件名
diff f2 f2.rm 比较还原回来的新文件与被删除的文件,发现没有区别。
6. grep
grep : 由正则表达式字符及文本字符所编写的过滤条件
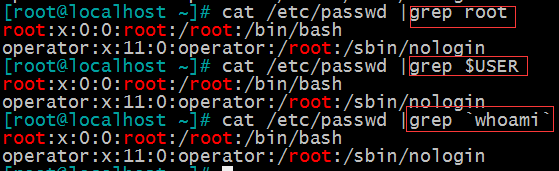
grep root /etc/passwd
grep “$USER” /etc/passwd
grep `whoami` /etc/passwd
–color=auto: 对匹配到的文本着色显示
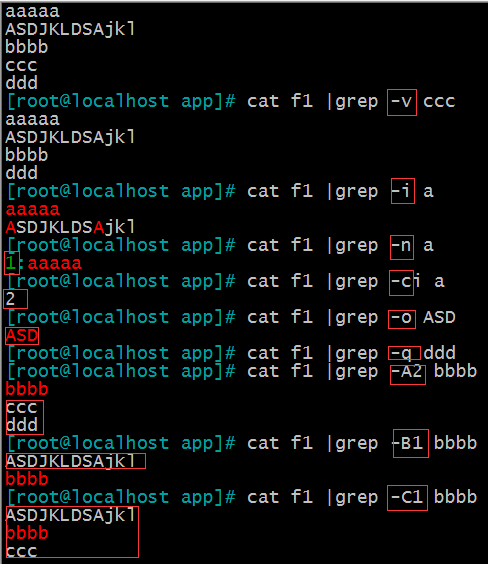
-v:显示不被pattern 匹配到的行 [^] 反向
-i: 忽略字符大小写
-n:显示匹配的行号
-c: 统计匹配的行数
-o: 仅显示匹配到的字符串
-q: 静默模式,不输出任何信息 或 &> /dev/null
-A #: after, 后#行
-B #: before, 前#行
-C # :context, 前后各#行
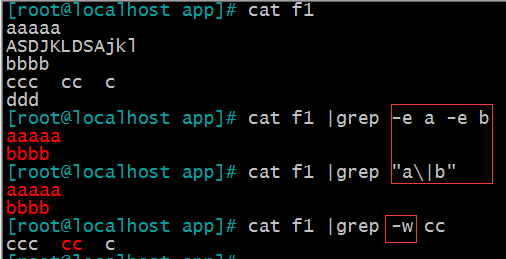
-e :实现多个选项间的逻辑or 关系 相当于“…\|…”
-w :匹配 整个单词
-E :使用ERE
-F :相当于fgrep
7. 正则表达式
(1). 匹配任意单个字符
[] 匹配指定范围内的任意单个字符
[^] 匹配指定范围外的任意单个字符
[:alnum:] 或 [0-9a-zA-Z]
[:alpha:] 或 [a-zA-Z]
[:upper:] 或 [A-Z]
[:lower:] 或 [a-z]
[:blank:] 空白字符(空格和制表符)
[:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广)
[:cntrl:] 不可打印的控制字符(退格、删除、警铃…)
[:digit:] 十进制数字 或[0-9]
[:xdigit:]十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
(2)* 匹配前面的字符任意次,包括0次
贪婪模式:尽可能长的匹配
.* 任意长度的任意字符
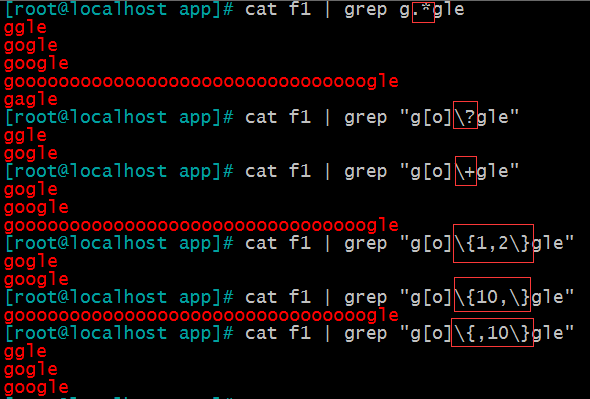
\? 匹配其前面的字符0 或1次
\+ 匹配其前面的字符至少1次
\{n\} 匹配前面的字符n次
\{m,n\} 匹配前面的字符至少m 次,至多n次
\{,n\} 匹配前面的字符至多n次
\{n,\} 匹配前面的字符至少n次
(3)位置锚定:定位出现的位置
^ 行首锚定,用于模式的最左侧
$ 行尾锚定,用于模式的最右侧
^PATTERN$ 用于模式匹配整行
^$ 空行 grep -v ^$ 或 tr -s ‘\n’
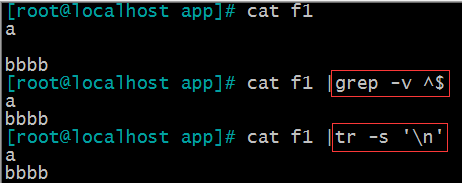
^[[:space:]]*$ 空白行
\< 或 或 \b 词首锚定,用于单词模式的左侧
\> 或 或 \b 词尾锚定;用于单词模式的右侧
\<PATTERN\>
(4)分组:\(\) 将一个或多个字符捆绑在一起,当作一个整体进行处理,如:\(root\).*
分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名方式为: \1, \2, \3, …
\1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符
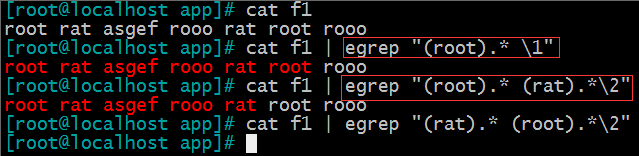
后向引用:引用前面的分组括号中的模式所匹配字符 , 而非模式本身
或者:\| 例:a\|b: a 或b C\|cat: C 或cat \(C\|c\)at:Cat 或cat
8. egroup 及 正则表达式
egrep egrep = grep -E
及 扩展的正则表达式 (除了\< , \> , \b 其他的都去掉\)
(1) 字符匹配:
. 任意单个字符
[] 指定范围的字符
[^] 不在指定范围的字符
(2) 次数匹配:
* :匹配前面字符任意次
? : 0 或1次 次
+ :1 次或多次
{m} :匹配m次 次
{m,n} :至少m ,至多n次
(3)位置锚定:
^ : 行首
$ : 行尾
\<, \b : 语首
\>, \b : 语尾
(4)分组:()
后向引用:\1, \2, …
或者:a|b: a 或b 例:C|cat: C 或cat (C|c)at:Cat 或cat
原创文章,作者:along,如若转载,请注明出处:http://www.178linux.com/83129

