

分类
- 数值型
int、float、complex、bool - 序列对象
字符串str、列表list、tuple - 键值对
集合set、字典dict
数值型
- complex:有实数和虚数部分组成
- float:有整数和小数组成。只有双精度
类型转换
- int(X) 返回一个整数
- float(x) 返回一个浮点数
- complex(x)、complex(x,y) 返回一个复数
- bool(x) 返回布尔值
数字的处理函数
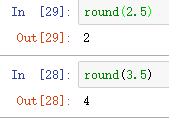
- round() 四舍六入五取偶

- floor() 地板,往下取
ceil() 天花板,往上取

- min()
max()
pow(x,y) 等于x**y
math.sqrt() - 进制函数
bin()
oct()
hex() - math.pi π
math.e 自然常数e
类型判断
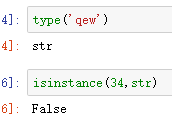
- type(obj),返回类型,而不是字符串
- isinstance(obj,class_or_tuple),返回布尔值
- 示例
列表list
- 特点
sequence
item (could be anything)
线性的数据结构
列表是可变的
使用[]表示 - 定义
list(iterable) -> new list initialized from iterable’s items
索引,也叫下标
- 正索引:从左至右,从0开始,为列表中每一个元素编号
- 负索引:从右至左,从-1开始
- 正负索引不可以超界
- 左边是头部,右边是尾部,左边是下界,右边是上界
- 列表通过索引访问
list[index],index就是索引,使用中扩号访问
列表查询
- index(value,[start,[stop]])
通过值value,从指定区间查找列表内的元素是否匹配
匹配第一个值就立即返回索引 - count(value)
返回列表中匹配value的次数 - 时间复杂度
index和count都是O(n)
随着列表数据规模越大,效率越低 - len()
获得list元素的个数
列表基本操作
- list[index] = value
- append(obj) -> None
尾部追加元素,返回None
就地修改
时间复杂度O(1)lst=[2,3] lst.append(1) - insert(index,object) ->None #很少用到
超越上界,尾部追加
超越下届,头部追加 - extend(iteratable) -?None
将可迭代对象的元素追加进来,返回None,就地修改 - + ->list
将两个列表连接起来,产生新的列表 - * ->list
重复操作,将本列表元素重复n次,返回新的列表
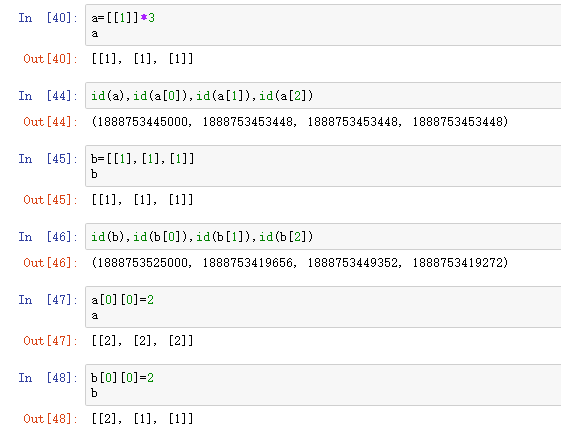
# a=[[1]]*3只是复制了引用(门牌号),当对三者中任何一个发生改变,其他两个也会相应的改变
# b=[[1],[1],[1]]里面就是不同的三个引用
- remove(value) -> None
从左至右查找第一个匹配value的值,移除该元素,返回None
就地修改 #用的比较少,一般用pop - pop(index) ->item
不指定索引index,就从列表尾部弹出一个元素 - clear() ->None
清楚列表所有元素,剩下一个空列表 - reverse() ->None
将列表元素反转 - sort(key=None,reverse=False) ->None
对列表元素进行排序,就地修改,默认升序
reverse为True,反转,降序
key为一个函数,指定key按照什么规则排序 - in
[3,4] in [1,2,[3,4]]
for x in [1,2,3,4]
列表复制
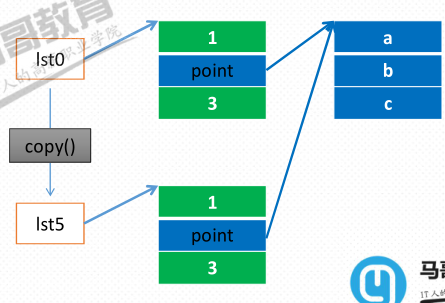
- copy() -> list
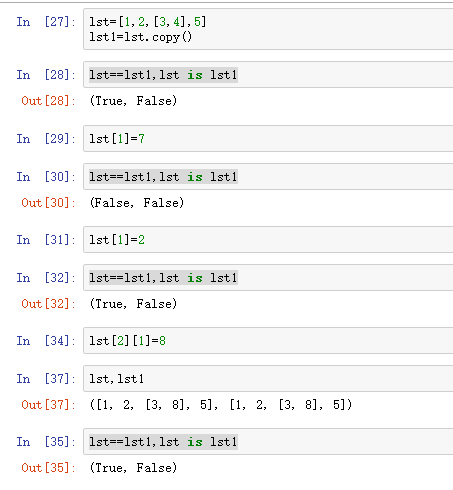
- shadow copy
浅拷贝,遇到引用类型,只是复制了一个引用而已(记下了门牌号)
- 深拷贝
import copy lst=[1,2,[3,4],5] lst1=copy.deepcopy(lst) lst[2][1]=20 lst==lst1,lst is lst1
随机数
- random模块
- randint(a,b) 返回[a,b]之间的整数
- choice(seq) 从非空序列的元素中随机挑选一个元素,比如random.choice(range(10))
- randrange 从集合中获取一个号随机数
random.randrange)(1,7,2) - random.shuffle(list) ->None
就地打乱列表元素
注意
- 列表list用for循环进行遍历的时候,会出错,不建议这样使用
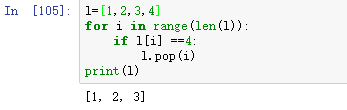
- 例1

- 例2 ,利用index来遍历删除
这样虽然删除了,但是列表l变成l=[1,2,3,4,5],就报错了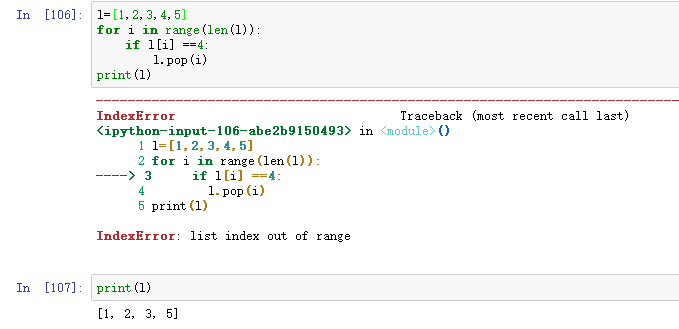
range的开始范围是0-4,中间遍历的时候删除了一个元素4,这个时候列表就变成了l=[1,2,3,5],这时候就会报错了,提示超界,原因就是遍历的时候删除了元素
- 例1
tuple 元组
- 特点
一个有序的元素组成的集合
使用()表示
不可变对象- 元组是只读的,增、改、删都没有
- 定义
tuple(iterable) -> tuple initialized from iterable’s itemst=tuple() t=(1,2,3,4) t=(1,) #一个元素定义必须有逗号
索引
- 知识点同list
- 元组通过索引访问
tuple[index],index就是索引,使用中扩号访问t[-1]=4
查询
- 查询同list
- 主要记住 len(tuple)
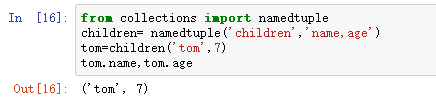
命名元组namedtuple
- namedtuole(typename,field_names,verbose=False,rename=False)
- 命名元组,返回一个元组的子类,并定义了字段
- field_names可以是空格或逗号分割的字段的字符串,可以是字段的列表
冒泡法
- 交换排序
- 第一轮比较,需要比较n-1次,第二轮是n-2次,以此类推,最后只剩下两个数比较
- 最差的排序情况是,初始顺序与目标顺序完全相反,遍历次数就是n-1,……,1的和n(n-1)/2
- 例如[4,3,2,1]要求升序排序[1,2,3,4]
- 最好的排序情况是,初始顺序与目标顺序相同,遍历n-1次
- 时间复杂度O(n²)
- 简单冒泡法实现
numlist = [[1,9,8,5,6,7,4,3,2],[1,2,3,4,5,6,7,8,9]] nums = numlist[1] print(nums) length = len(nums) count_swap = 0 count = 0 for i in range(length): for j in range(length-i-1): count += 1 if nums[j] > nums[j+1]: tmp = nums[j] nums[j] = nums[j+1] nums[j+1] = tmp count_swap += 1 print(nums,count_swap,count) # count_swap是为了查看交换的次数 # count是为了查看进行了多少次比较(包括没有交换的比较)
- 优化版(错误示范)
numlist = [[1,9,8,5,6,7,4,3,2],[1,2,3,4,5,6,7,8,9],[1,2,3,4,5,6,7,9,8]] nums = numlist[1] print(nums) length = len(nums) count_swap = 0 count = 0 flag=False for i in range(length): for j in range(length-i-1): count += 1 if nums[j] > nums[j+1]: tmp = nums[j] nums[j] = nums[j+1] nums[j+1] = tmp flag = True count_swap += 1 if not flag: break print(nums,count_swap,count)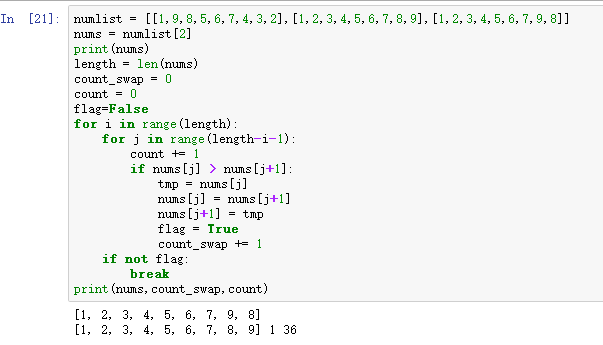
# flag=Flash放错位置了,放在最上面不起作用,只有放在for i循环下面才起作用。 # 如果for j的第一次循环没有比较的话(也就是123456789这样的排序),那么这次循环后就会结束,其他的情况都是在第一次循环会进行比较交换,也就是执行了if语句,那么flag就变成了True,这样在后面的循环中,哪次循环没有比较才会break。 # 这样大大提高了效率
- 优化(正确) *****记住
numlist = [[1,9,8,5,6,7,4,3,2],[1,2,3,4,5,6,7,8,9],[1,2,3,4,5,6,7,9,8]] nums = numlist[1] print(nums) length = len(nums) count_swap = 0 count = 0 for i in range(length): flag = False for j in range(length-i-1): count += 1 if nums[j] > nums[j+1]: tmp = nums[j] nums[j] = nums[j+1] nums[j+1] = tmp flag = True count_swap += 1 if not flag: break print(nums,count_swap,count)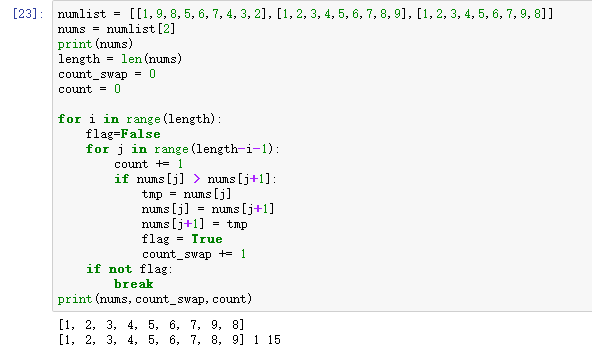
本文来自投稿,不代表Linux运维部落立场,如若转载,请注明出处:http://www.178linux.com/87559
