

数据载入
def load(path:str):
with open(path) as f:
for line in f:
tmp = extract(line)
if tmp:
yield tmp
else:
# TODO 解析失败就抛弃,或者打印日志
continue
时间窗口分析
概念
- 很多数据,例如日志,都和时间相关的,都是按照时间顺序产生的。
- 产生的数据分析的时候,要按照时间求值
- interval 表示每一次求值的时间间隔
- width 时间窗口宽度,指的一次求值的时间窗口宽度
当width > interval
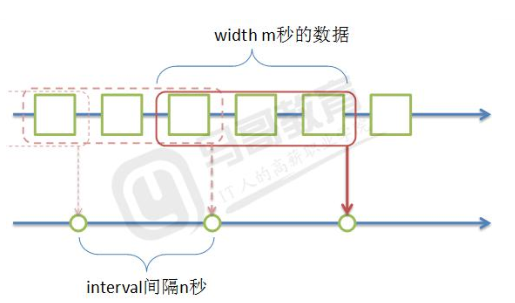
- 数据求值是会有重叠
当width = interval
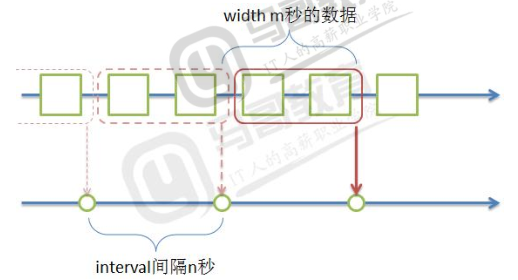
- 数据求值没有重叠
当width < interval
- 一般不采纳,因为这样会有数据流失
时序数据
- 运行环境中,日志、监控等产生的数据都是与时间相关的数据,按照时间先后产生并记录下来的数据,所以一般按照时间对数据进行分析
时序数据分析的节本程序结构
- 随机生成几个数,产生时间相关的数据,返回 时间 + 随机数
- 每次取三个值,求平均值
import random import datetime import time def f(): while True: yield {'value':random.randrange(100), 'time':datetime.datetime.now()} time.sleep(1) src = f() items = [next(src) for _ in range(3)] def handler(iterable): vals = [x['value'] for x in iterable] return sum(vals) / len(vals) print(items) print(handler(items))

窗口函数实现
import random
import datetime
import time
# 数据源函数
def f():
while True:
yield {'value':random.randrange(100), 'time':datetime.datetime.now()}
time.sleep(5)
def window(src, handler, width:int, interval:int):
"""
窗口函数
:param src: 数据源,生成器,用来拿数据
:param handler: 数据处理函数
:param width: 时间窗口宽度,秒
:param interval: 处理时间间隔,秒
"""
# 初始两个时间段
start = datetime.datetime.strptime('20170101 00:00:00', '%Y%m%d %H:%M:%S')
current = datetime.datetime.strptime('20170101 00:01:00', '%Y%m%d %H:%M:%S')
buffer = [] # 窗口中待计算的数据
delta = datetime.timedelta(seconds = width - interval)
while True:
# 从数据源获取数据
data = next(src)
# 存入临时缓冲等待计算
if data: # 筛掉不符合的数据
buffer.append(data)
current = data['time']
# 进入循环开始操作
if (current - start).total_seconds() >= interval:
ret = handler(buffer)
print('{:.2f}'.format(ret))
start = current
# 处理重叠的数据
buffer = [x for x in buffer if x['time'] > current - delta]
def handler(iterable):
vals = [x['value'] for x in iterable]
return sum(vals) / len(vals)
- 第41行current – delta是因为现在的current还没有更新,而current的时间值到当前current时间值之间的数据正好是重叠的数据
- 当width和interval给一样的时候,那么delta为0,所以不会有重复数据

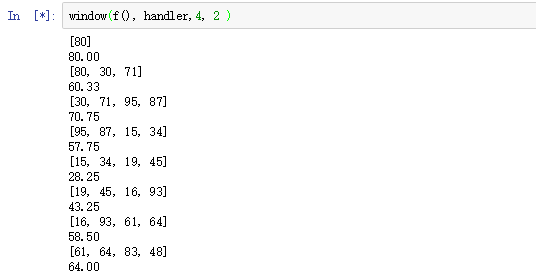
- 相当于用给定的width往后滑动,一下走这么多interval
- 比如这个,是时间宽为4往下走,两个两个的往后走,所以每次会有两个重复的数据
本文来自投稿,不代表Linux运维部落立场,如若转载,请注明出处:http://www.178linux.com/88218

