

什么是inode?
理解inode,要从文件储存说起。文件储存在硬盘上,硬盘的最小存储单位叫扇区(Sector)。每个扇区储存512字节(相当于0.5KB)。操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个块(block)。这种由多个扇区组成的块是文件存取的最小单位,块的大小,最常见的是4KB,即连续八个sector组成一个block,文件数据都储存在块中,那么很明显,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创年日期、文件的大小等等。这种储存元信息的区域叫做inode,中文译名为”索引节点”。inode (index node) 表中包含文件系统的所有文件列表。
inode包含文件的信息(元数据)
Inode编号
用来识别文件类型,以及用于stat C函数的模式信息
文件权限
文件的拥有者的UID
文件所属组的GID
链接数(指向这个文件名路径名称个数)
文件的大小
文件的间戳(ctime指inode上一次变动的时间,mtime是指文件内容上一次变动的时间,atime指文件上一次打开的时间)
指向磁盘文件的数据块指针
有关文件的其它数据
注意:要想查看文件的inode信息可以使用stat命令查看
inode表结构
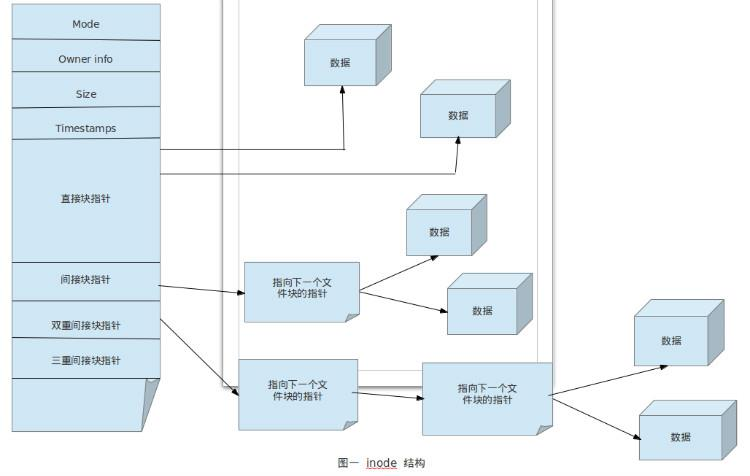
直接块指针:
前12个直接指针,直接指向存储数据的区域。如Blocks大小为4*1024KB,前12个直接指针就可以保存48KB的文件
间接块指针:
设每个指针占用4个字节,则以及指针指向的Blocks可以保存(4*1024)/4KB,可指向1024个Blocks,一级指针可存储文件数据大小为1024*(4*1024)KB=4MB
双重间接块指针:
同样Blocks大小为4*1024,则二级指针可保存Blocks指针数量为((4*1024)/4)*((4*1024)/4),则二级指针保存文件数据大小为(1024*1024)*(4*1024)=4GB
三重间接块指针:
以次类推三级指针可以储存文件数据大小为(1024*4*1024*1024)*(4*1024)=4TB
inode的大小:
每个inode都有一个编号,操作系统用inode号来识别不同文件。Unix/Linux系统不使用文件名,而使用inode号来识别文件,对于系统来说,文件名只是inode号码便于识别的别称或绰号。表面上,通过文件名打开文件;实际上,系统内部这个过程分成三步:首先,系统找到这个文件名对应的inode号;其次,通过inode号,获取inode信息;最后,根据inode信息,找到文件数据所在的block,读出数据。
注意:inode号并不是无限的,如果一个分区的节点数被使用完了,那么即使磁盘空间还有剩余也不能再存放任何数据。可以使用df -i命令查看节点使用情况
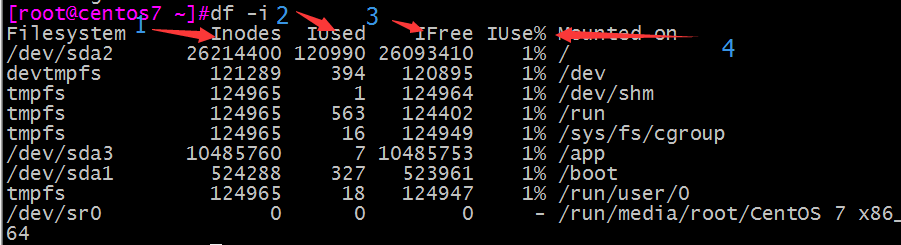
注:1节点总数、2使用过节点数、3剩余节点数、4节点使用率
目录文件:
Unix/Linux系统中,目录(directory)也是一种文件。打开目录,实际上就是打开目录文件目录文件的结果非常简单,就是一系列目录项(direct)的列表。每个目录项,由两部分组成:所包含文件的文件名,以及该文件名对应的inode号。
ls命令只列出目录文件中的所有文件名:
![]()
![]()
ls -i命令列出整个目录文件,即文件名和inode号(箭头标的即为inode号):
![]()
![]()
如果要查看文件的详细信息,就必须根据inode号,访问inode节点,读取信息。ls -i -l 目录文件 列出整个目录文件,即文件名和inode号(箭头标注的列即为inode号)

理解了上面的知识,就能理解目录的权限,文件的读权限(r)和写权限(w),都是针对目录文件本身。由于目录文件内只有文件名和inode号,所以只有读权,只能获取文件名,无法获取其他信息,因为其他信息都储存在inode节点中,而读取inode节点内的信息需要目录文件的执行权限(x)。
Linux中cp、rm、mv 、ln对inode的影响:
cp命令
- 分配一个未被使用的inode号,在inode表中添加一个新项目,(注意:如果是cp到讴歌已经存在的文件,则inode号采用被覆盖之前的目标文件的inode号,如果对运行中的apache共享模块so文件进行cp操作,就会出现Segmentation fault<段错误>)
- 在目录中新建一个目录项,并指向步骤1中的inode
- 把数据复制到block中
rm命令
- 减少链接数量,如果链接数为0,释放inode(inode号也已被重新使用);
- 如果inode被释放,则数据块放到可用空间列表中;
- 删除目录中的目录项
mv命令
1.如果mv命令的目标文件和源文件所在额文件系统相同:
- 使用新文件名建立目录项;
- 删除带有原来文件名的目录项;
注意:该操作对inode表没有影响(除时间戳),对数据的位置也没有影响,不移动任何数据。(即使是mv到一个已经存在的目标文件,新目录项指源文件inode,会先删除目标文件的目录项,所以如果对运行中的apache的共享模块so文件进行这种操作的话不会有问题,新的so文件inode号变了)
2.如果目标和源文件所在的问价系统不相同,就是cp和rm;
ln命令
符号(软)链接:
符号链接的内容是它引用文件的名称,可以是任意文件或目录,也可以链接不同问价系统的文件,甚至可以链接不存在的文件,这就产生一般称为断裂的问题,还可以不断的循环链接源文,但是其大小为指向的路径字符串的长度;不增加或减少目标文件inode 的引用计数。
使用ln -s source_file softlink_file (注意:源文件(source_file)的路径是相对路径(也可以是绝对路径,通常使用的是相对路径),一定是相对于软链接文件的路径,而非相对于当前工作目录的路径)创建符号链接,在对符号链接进行读写操作的时候,系统会自动把该操作转换为对源文件的操作,但是删除连接文件时,系统仅仅删除符号链接文件,而不是删除源文件本身。
硬链接:
不允许给目录创建硬链接,创建硬链接会正价额外的记录项以引用文(不能跨驱动或分区创建硬链接),硬链接件对应于同一文件系统上的一个物理文件,硬链接节点编号是相同的,创建硬链接链接数递增,删除文件时:rm命令递减计数的链接,文件如果存在,至少有一个链接数,当链接数为0时,该文件被删除。
使用ln existfile newfile 命令创建硬链接
硬链接于软连接的区别:
1、本质不同:硬链接是指向同一个文件,软链接指向的不是同一个文件
2、删除时:硬链接不受影响,软链接失效
3、创建链接时:创建硬链接链接数加1,创建软链接连接数不变
4、是否可以跨分区:硬链接不可以跨分区,软链接可以跨分区
5、目录是否可以创建链接:硬链接不可以对目录创建,软链接可以对目录创建
6、硬链接的inode号相同,软链接inode号不同
本文来自投稿,不代表Linux运维部落立场,如若转载,请注明出处:http://www.178linux.com/88362
