

初学Linux之文本处理工具和正则表达
之前我们已经了解了 Linux 系统中的用户、组和文件管理权限,对文件的设置权限,就是为了安全的存储数据、访问数据的。但是数据本身并不是按照我们预想的那样,有规律的存储好,之后让我们方便的访问,得到的数据在存储前,很多都是杂乱无章的,尤其是文本数据,这就要求我们对数据进行分析、处理、规范后进行保存,方便后续的访问和读取。下面我们就要了解文件处理相关的工具,以及正则表达在文本处理中的使用。
一、各种文本工具来查看、分析、统计文本
在前面我们已经学习了 cat 命令,这是个同时具备“标准输入”和“标准输出”命令,具体的功能是读取文本文件的内容,再输出到屏幕显示。它本身的功能是简单的,但是加上选项功能,再通过管道传递,重定向到文件,它就可以成为一个文本处理的工具。


cat命令的 -n 、-b 以及 -s 选项都是很好的功能,方便我们处理一些简单的文本,比如我们需要为文本内容的每行添加行号,同时去掉文本中多余的空格行,就可以使用右边的命令:cat -ns file.txt >newfile.txt 。
有意思的是,Linux中有一个“tac” 命令,名称和文本输出和 cat 刚好都是颠倒的,比如一个文件有两行内容,cat 读取输出是第一行 12 ,第二行 34 。用 tac 输出则是第一行 43,第二行21 。而另外一个倒叙输出的命令是 “rev ” 它的功能是处于 cat 和 tac 的中间,是将文本的每一行倒叙输出的,但是行序还是原来的。那么,rev 读取上面文件的输出就是:第一行 21 ,第二行 43 。 注:cat 、tac、rev 都是具备标准输入和标准输出的。
接着是 more 和 less 命令,也是读取文件到标准输出的,这个命令是将行数比较多的文件内容,分页显示,显示后,都是使用空格键(space)翻页,不同的是 less 命令支持往回翻页,同时具备匹配搜索功能,这两点 more 命令是不支持的。索引是在less 页面,点击 【?】【/】这个键操作的,【?】是在这个键的上面,是从页面向上进行检索,而【/】则是相反,按键 n 是按照检索的顺序进行搜索,shift+n 是逆序进行搜索。
head 和 tail 是获取文件头部行和尾部行的命令,默认是取 10 行,用户可以自己定义需要取出的行数,具体的用法都已经在上面的图片中详细说明了。
cut :将文件中有规律标记符号分割,具备相同书写格式的行,通过标记符号剪切出指定字段内容的工具。
paste:合并两个文件相同行的命令,它的 -s 选项比较特殊,是将单个文本的多行合并到一行输出,多个文本按照顺序成为输出的不同行。


wc :统计文本的计数行总数、单词总数、字节总数和字符总数,在屏幕输出以上数据的文本统计工具。
sort :主要功能是排序,排序的过程中可以按照字母(首字母),也可以按照数字(整个指定的列),排序过程中可以去除重复项。



uniq :这个命令最主要的功能是将前后相同的重复行。-c 是比较常用的选项,可以将重复的次数显示,这样变相的统计了出现的次数。当然前提是前后相接的行,sort 可以做到这一点,所以在Linux中,sort 和 uniq 这两个命令是常常一起合用的。
diff :找不同的命令,可以对比两个文本内容之间的差别的命令。使用 -u 选项来输出“统一的(unified)”diff格式文 件,最适用于补丁文件 。
patch :复制其他文件中的改变,将不同的地方同步到指定文件的命令。
 以上列出的命令都是功能不是很复杂的文本处理工具,但是基于标准输出和管道的功能,我们可以将这些命令的功能由简单到复杂,逐渐拼凑出功能复杂的命令选项。
以上列出的命令都是功能不是很复杂的文本处理工具,但是基于标准输出和管道的功能,我们可以将这些命令的功能由简单到复杂,逐渐拼凑出功能复杂的命令选项。
比如:查询并发连接的远程IP最多的前三个IP,就可以使用下面的命令进行处理。
cut -d” ” -f 1 /var/log/httpd/access_log | sort |uniq -c|sort -nr |head -3
二、grep
前面我们已经学习了简单的文本处理工具,接下来我们需要了解功能较强的文本处理工具,比较普遍启用的是 grep系列(grep、egrep、fgrep)、sed 、awk ,这三个经常被称为Linux系统文本处理三剑客,我们先学习 grep 。
 grep 由很多的选项功能,这些都是非常有用的,这也从侧面说明了它功能的丰富,支持的是基本正则表达(BRE),并不支持ERE,和简单工具组合命令处理文本相比,grep的优势在于灵活。一般的思维状态下,我们需要搜索具有某内容的行,就会搜索明确的字符串,但是在正常使用中,为了更加灵活的查找更大范围,我们往往是使用模糊查询的,若是使用模糊查询,通配符是一种方法,还有一种就是接下来学习的正则表达式,有了它,我们的文本处理三剑客才变得灵活。
grep 由很多的选项功能,这些都是非常有用的,这也从侧面说明了它功能的丰富,支持的是基本正则表达(BRE),并不支持ERE,和简单工具组合命令处理文本相比,grep的优势在于灵活。一般的思维状态下,我们需要搜索具有某内容的行,就会搜索明确的字符串,但是在正常使用中,为了更加灵活的查找更大范围,我们往往是使用模糊查询的,若是使用模糊查询,通配符是一种方法,还有一种就是接下来学习的正则表达式,有了它,我们的文本处理三剑客才变得灵活。
三、正则表达式和扩展正则表达式
我们在之前的介绍中,有一个 less 命令也是支持搜索匹配的,less 命令也是支持正则表达的。正则表达(RE:Regular expressions):由一类特殊字符及文本字符所编写的模式,其中有 些字符(元字符)不表示字符字面意义,而表示控制或通配的功能。 正则表达在很多的程序和系统都会使用到,是一个普遍的功能。基本正则表达(BRE)和扩展正则表达(ERE)是正则表达的两个分类。具体的介绍,我们也可以查询 man 帮助文档(man 7 regex),里面有详细的介绍。
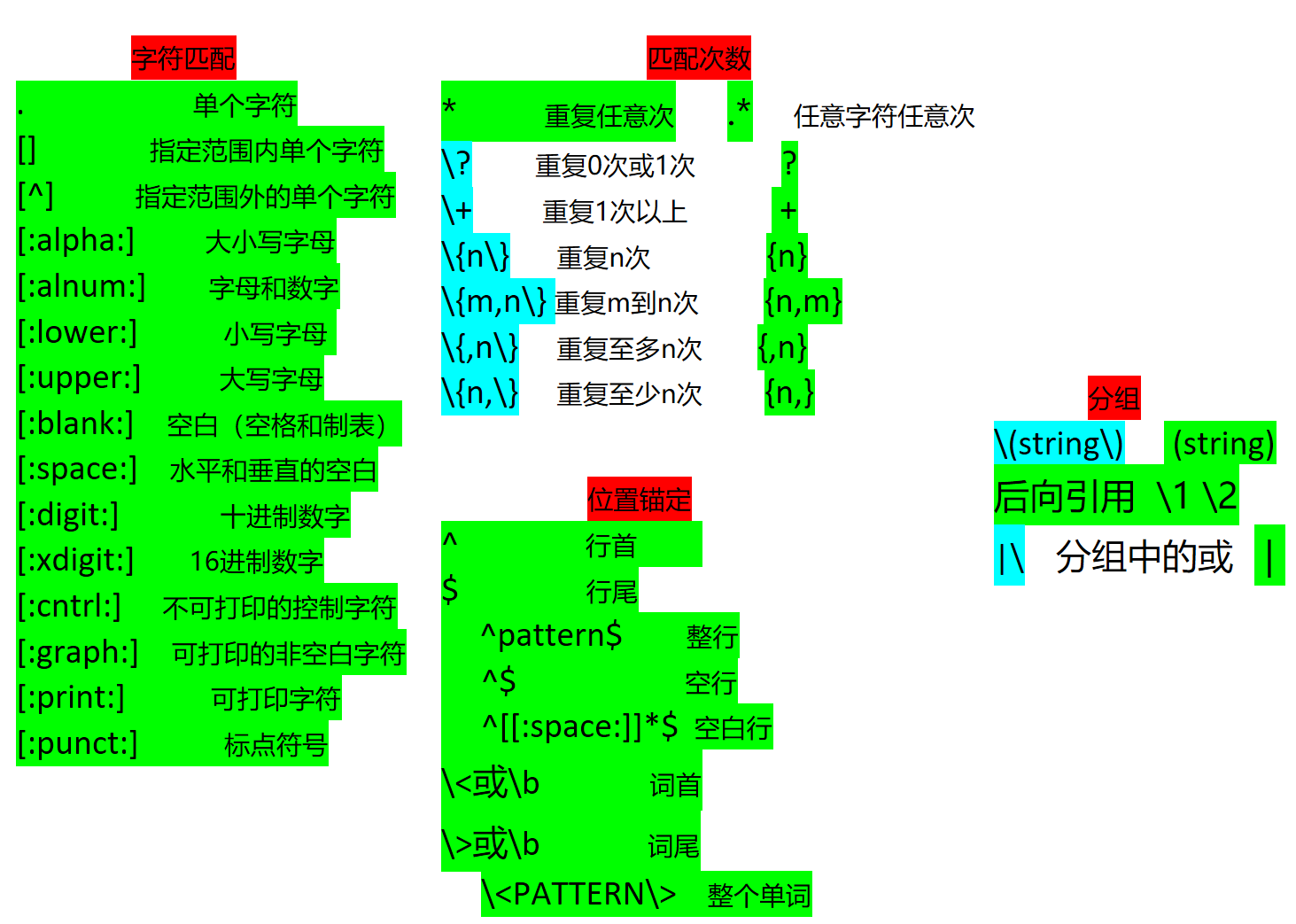
上面图片中,绿色背景显示的是基本正则表达和扩展正则表达同时支持的符号表达,蓝色的是基本正则表达式中的符号表示,扩展正则表达是不包括的。
需要注意的是符号“ * ” 和 “ . * ” 的使用,它们在使用时是尽可能的进行匹配,是一种贪婪模式。比如文件 f1 有且仅有一行,由11个1连串组成的字符串。一般的理解下,当我们用户 “ 1* ” 符号匹配,那么就是 对1任意重复次数进行匹配,1任意重复的情况就是 “ ” 、“ 1 ” 、“ 11 ”、 “ 111 ”……. 这样的情况,我们可以用 grep 工具表示为 :grep -o -e ‘1’ -e ’11’ -e ‘111’ …… f1 各个匹配项是或者的关系,也就是 1* (1重复任意次),那么正常输出的结果就是不同个数的1 各占一行。但是系统不是这样的,计算机不会去对一个未知次数的选项进行匹配,它在匹配过程中不是生成随机个重复1 进行匹配,它按照最大可能匹配的,如果是11个1,那么 1*就是匹配的11个,只会输出一行。
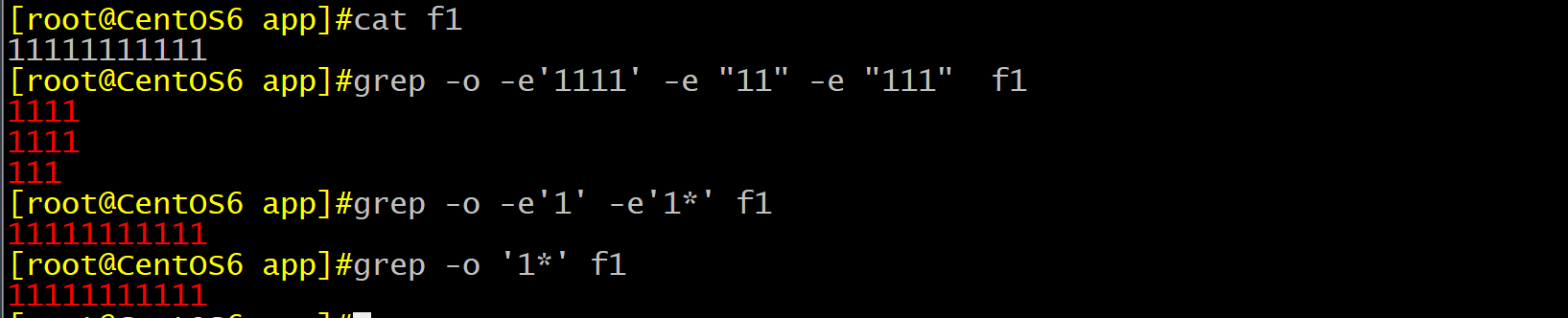
!注意:当由两个相同的贪婪选项同时进行匹配的情况下,后面的贪婪是收到一定的限制的。
四、egrep
egrep 支持的是扩展正则表达(ERE),不支持基本正则表达(BRE),它和 grep -E 是相同的,相当于是一种缩写形式。
本文来自投稿,不代表Linux运维部落立场,如若转载,请注明出处:http://www.178linux.com/89742
