

一、Nagios简介
Nagios是一款开源的电脑系统和网络监视工具,能有效监控Windows、Linux和Unix的主机状态,交换机路由器等网络设置,打印机等。在系统或服务状态异常时发出邮件或短信报警第一时间通知网站运维人员,在状态恢复后发出正常的邮件或短信通知。
Nagios原名为NetSaint,由Ethan Galstad开发并维护至今。NAGIOS是一个缩写形式: “Nagios Ain’t Gonna Insist On Sainthood” Sainthood 翻译为圣徒,而”Agios”是”saint”的希腊表示方法。Nagios被开发在Linux下使用,但在Unix下也工作得非常好。
主要功能
- 网络服务监控(SMTP、POP3、HTTP、NNTP、ICMP、SNMP、FTP、SSH)
- 主机资源监控(CPU load、disk usage、system logs),也包括Windows主机(使用NSClient++ plugin)
- 可以指定自己编写的Plugin通过网络收集数据来监控任何情况(温度、警告……)
- 可以通过配置Nagios远程执行插件远程执行脚本
- 远程监控支持SSH或SSL加通道方式进行监控
- 简单的plugin设计允许用户很容易的开发自己需要的检查服务,支持很多开发语言(shell scripts、C++、Perl、ruby、Python、PHP、C#等)
- 包含很多图形化数据Plugins(Nagiosgraph、Nagiosgrapher、PNP4Nagios等)
- 可并行服务检查
- 能够定义网络主机的层次,允许逐级检查,就是从父主机开始向下检查
- 当服务或主机出现问题时发出通告,可通过email, pager, sms 或任意用户自定义的plugin进行通知
- 能够自定义事件处理机制重新激活出问题的服务或主机
- 自动日志循环
- 支持冗余监控
- 包括Web界面可以查看当前网络状态,通知,问题历史,日志文件等
二、Nagios工作原理
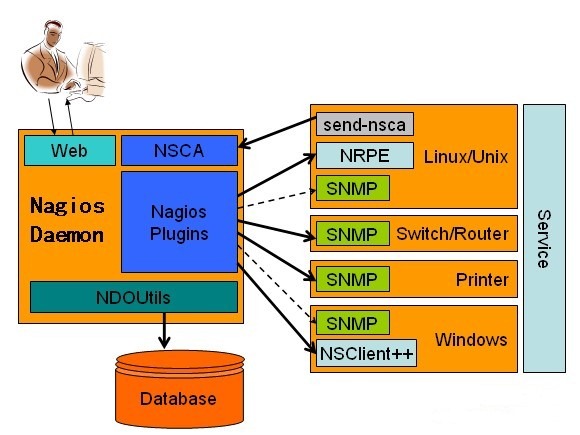
Nagios的功能是监控服务和主机,但是他自身并不包括这部分功能,所有的监控、检测功能都是通过各种插件来完成的。
启动Nagios后,它会周期性的自动调用插件去检测服务器状态,同时Nagios会维持一个队列,所有插件返回来的状态信息都进入队列,Nagios每次都从队首开始读取信息,并进行处理后,把状态结果通过web显示出来。
Nagios提供了许多插件,利用这些插件可以方便的监控很多服务状态。安装完成后,在nagios主目录下的/libexec里放有nagios自带的可以使用的所有插件,如,check_disk是检查磁盘空间的插件,check_load是检查CPU负载的,等等。每一个插件可以通过运行./check_xxx –h 来查看其使用方法和功能。
Nagios可以识别4种状态返回信息,即 0(OK)表示状态正常/绿色、1(WARNING)表示出现警告/黄色、2(CRITICAL)表示出现非常严重的错误/红色、3(UNKNOWN)表示未知错误/深黄色。Nagios根据插件返回来的值,来判断监控对象的状态,并通过web显示出来,以供管理员及时发现故障。
四种监控状态

再说报警功能,如果监控系统发现问题不能报警那就没有意义了,所以报警也是nagios很重要的功能之一。但是,同样的,Nagios 自身也没有报警部分的代码,甚至没有插件,而是交给用户或者其他相关开源项目组去完成的。
Nagios 安装,是指基本平台,也就是Nagios软件包的安装。它是监控体系的框架,也是所有监控的基础。
打开Nagios官方的文档,会发现Nagios基本上没有什么依赖包,只要求系统是Linux或者其他Nagios支持的系统。不过如果你没有安装apache(http服务),那么你就没有那么直观的界面来查看监控信息了,所以apache姑且算是一个前提条件。关于apache的安装,网上有很多,照着安装就是了。安装之后要检查一下是否可以正常工作。
知道Nagios 是如何通过插件来管理服务器对象后,现在开始研究它是如何管理远端服务器对象的。Nagios 系统提供了一个插件NRPE。Nagios 通过周期性的运行它来获得远端服务器的各种状态信息。它们之间的关系如下图所示:
Nagios 通过NRPE 来远端管理服务
1. Nagios 执行安装在它里面的check_nrpe 插件,并告诉check_nrpe 去检测哪些服务。
2. 通过SSL,check_nrpe 连接远端机子上的NRPE daemon
3. NRPE 运行本地的各种插件去检测本地的服务和状态(check_disk,..etc)
4. 最后,NRPE 把检测的结果传给主机端的check_nrpe,check_nrpe 再把结果送到Nagios状态队列中。
5. Nagios 依次读取队列中的信息,再把结果显示出来。
三、安装配置nagios
# vim /etc/nagios/conf.d/192.168.36.125.cfg
define host{ # 定义主机:192.168.36.125 use linux-server host_name 192.168.36.125 alias 36.125 address 192.168.36.125 }
define service{ # 添加 ping 监控服务 use generic-service host_name 192.168.36.125 service_description check_ping check_command check_ping!100.0,20%!200.0,50% max_check_attempts 5 normal_check_interval 1 }
define service{ # 添加 ssh 监控服务 use generic-service host_name 192.168.36.125 service_description check_ssh check_command check_ssh max_check_attempts 5 normal_check_interval 1 }
define service{ # 添加 http 监控服务 use generic-service host_name 192.168.36.125 service_description check_http check_command check_http max_check_attempts 5 normal_check_interval 1 }
# service nagios reload
[root@nagios ~]# yum install epel-release -y # 安装epel源 [root@nagios ~]# yum install nrpe -y # 安装nrpe服务软件 [root@nagios ~]# yum install nagios-plugins-all -y # 安装所有nagios插件
[root@nagios ~]# vim /etc/nagios/nrpe.cfg allowed_hosts=127.0.0.1,192.168.36.122# 添加192.168.36.122来监控 dont_blame_nrpe=1 # 修改0为1,设置可以传递参数 command[check_hda1]=/usr/lib64/nagios/plugins/check_disk -w 20% -c 10% -p /dev/sda1
[root@nagios ~]# service nrpe start
[root@vip ~]# vim /etc/nagios/objects/commands.cfg
define command{ command_name check_nrpe command_line $USER1$/check_nrpe -H $HOSTADDRESS$ -c $ARG1$ }
[root@vip ~]# vim /etc/nagios/conf.d/192.168.0.28.cfg
define service{ # 添加监控负载 use generic-service host_name 192.168.0.28 service_description check_load check_command check_nrpe!check_load max_check_attempts 5 normal_check_interval 1 } define service{ # 添加监控sda1磁盘 use generic-service host_name 192.168.0.28 service_description check_disk_hda1 check_command check_nrpe!check_hda1 max_check_attempts 5 normal_check_interval 1 }
# service nagios reload
[root@vip ~]# yum install -y pnp4nagios rrdtool
# vim /etc/nagios/nagios.cfg process_performance_data=1 host_perfdata_command=process-host-perfdata service_perfdata_command=process-service-perfdata enable_environment_macros=1
# vim /etc/nagios/objects/commands.cfg
process-host-perfdata和process-service-perfdata重新定义
define command { command_name process-service-perfdata command_line /usr/bin/perl /usr/libexec/pnp4nagios/process_perfdata.pl }
define command { command_name process-host-perfdata command_line /usr/bin/perl /usr/libexec/pnp4nagios/process_perfdata.pl -d HOSTPERFDATA }
# vim /etc/nagios/objects/templates.cfg
define host { name hosts-pnp register 0 action_url /pnp4nagios/index.php/graph?host=$HOSTNAME$&srv=_HOST_ process_perf_data 1 }
define service { name srv-pnp register 0 action_url /pnp4nagios/index.php/graph?host=$HOSTNAME$&srv=$SERVICEDESC$ process_perf_data 1 }
4.5 修改host和service的配置
# vim /etc/nagios/conf.d/192.168.36.125.cfg
所有主机使用的模板后边添加hosts-pnp:
define host{ use linux-server,hosts-
所有服务使用的模板后边添加srv-pnp:
define service{ use generic-service,srv-pnp host_name 192.168.0.48 service_description check_disk_hda1 check_command check_nrpe!check_hda1 }
原创文章,作者:nene,如若转载,请注明出处:http://www.178linux.com/90844
