

- 正则表达式:REGular EXPression
字符匹配:
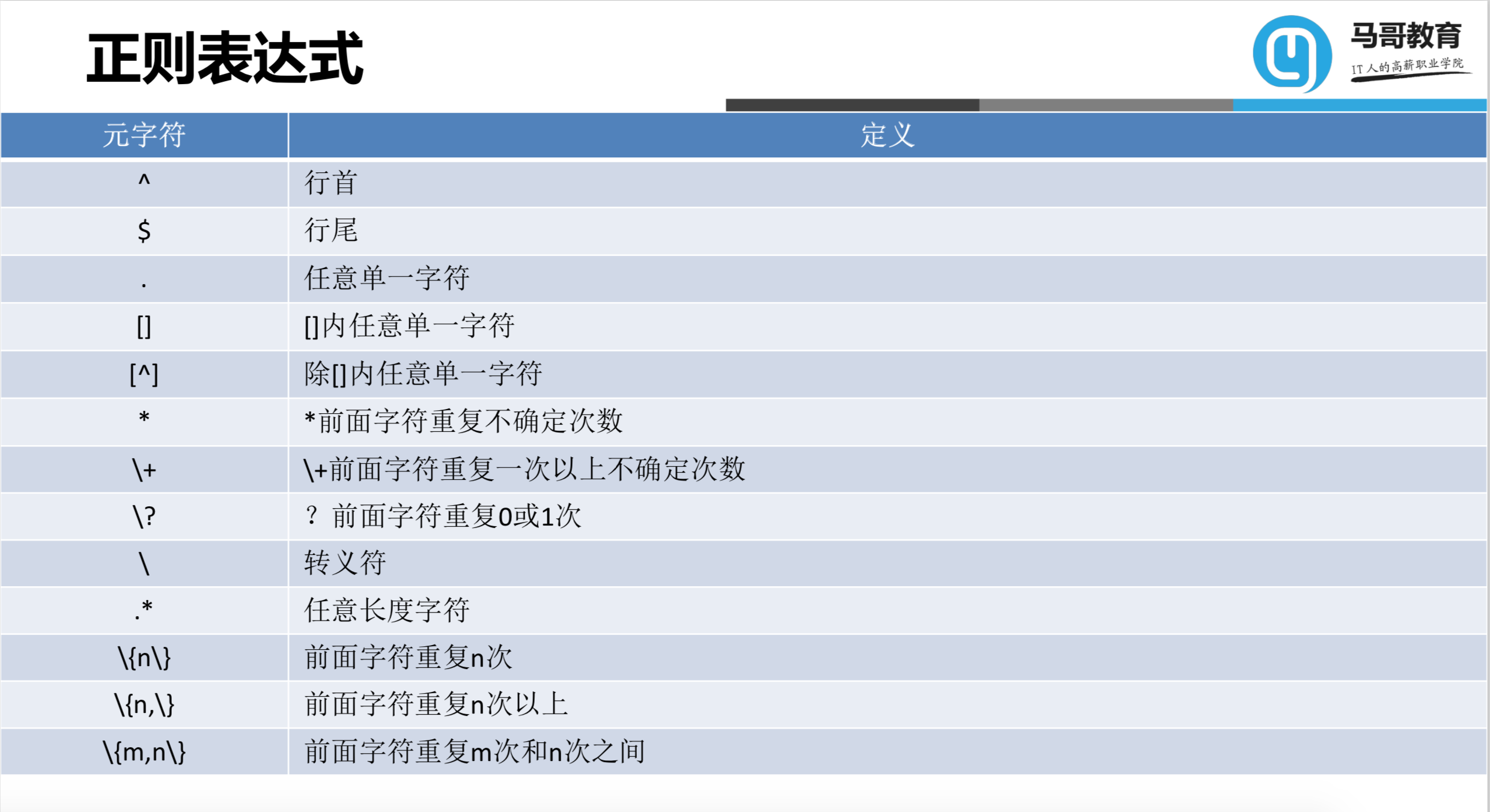
. 匹配一个随机字符
\[^.]:匹配除了点以外任意的字符
[] 匹配指定范围内的任意单个字符
[^] 匹配指定范围外的任意单个字符
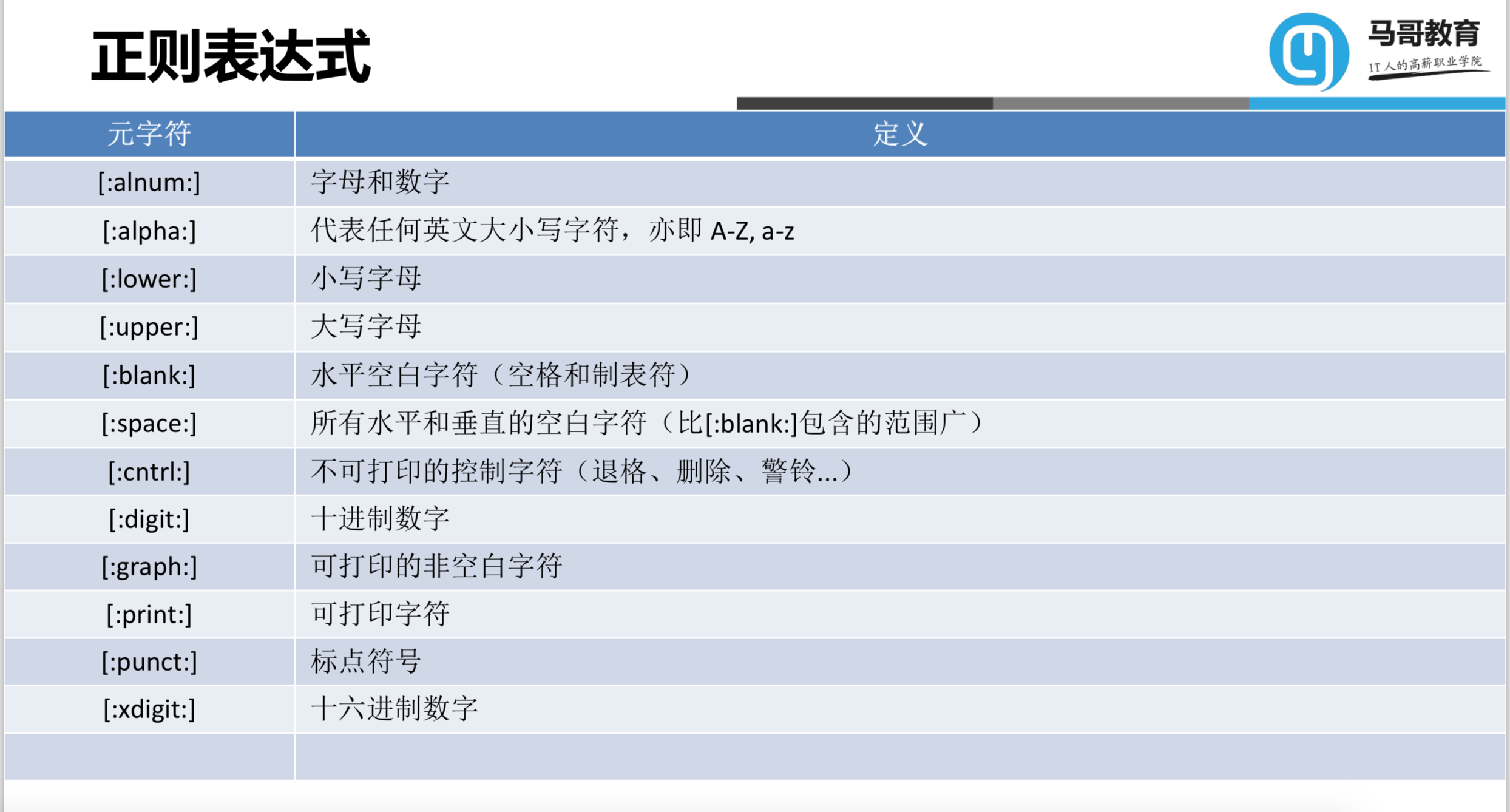
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:blank:] 空白字符(空格和制表符)
[:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广)
[:cntrl:] 不可打印的控制字符(退格、删除、警铃…)
[:digit:] 十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
次数匹配:
*:匹配前面出现的字符n次
.*:表示任意长度的任意字符串
\?:匹配前面出现的字符最多1次
\+:匹配前面出现的字符最少1次
\{n\}:匹配前面出现的字符n次
\{m,n\}:匹配前面出现的字符最少m次最多不超过n次
\{,n\}:匹配前面出现的字符最多n次
\{n,\}:匹配前面出现的字符最少n次
位置锚定:
^:匹配行首
$:匹配行尾
^$:空行
^[[:space:]]$:空白行
\<\>:锚定一个单词
\<:锚定词首
\>:锚定词尾
分组:
echo AAAxxxxBBAAABBB|grep “\(A\)\{3\}.*\(B\)\+\1.*\2”
示例:嵌套分组 \(string1\+\(string2\)*\)
\1 :string1\+\(string2\)*
\2 :string2
后向引用:引用前面的分组括号中的模式所匹配字符,而非模式本身
\1:对分组的内容进行引用,第一个括号就是\1,第二个括号为\2,依此类推
或者:\|
示例:a\|b:a或b C\|cat:C或cat \(C\|c)at:Cat或cat - 扩展正则表达式:Extended REGular EXPression
字符匹配:
.:任意单个字符
[]:指定范围的字符
[^]:不在指定范围的字符
次数匹配:
*:匹配前面字符任意次
?:0次或1次
+:1次或多次
{m}:匹配m次
{m,n}:至少m,至多n次
位置锚定
^:行首
$:行尾
\<,\b:语首
\>,\b:语尾
分组:
()
反向引用:
\1,\2, …
或者:
a|b:a或b
C|cat:C或cat
(C|c)at:Cat或cat
本文来自投稿,不代表Linux运维部落立场,如若转载,请注明出处:http://www.178linux.com/92508

