

知识框架图
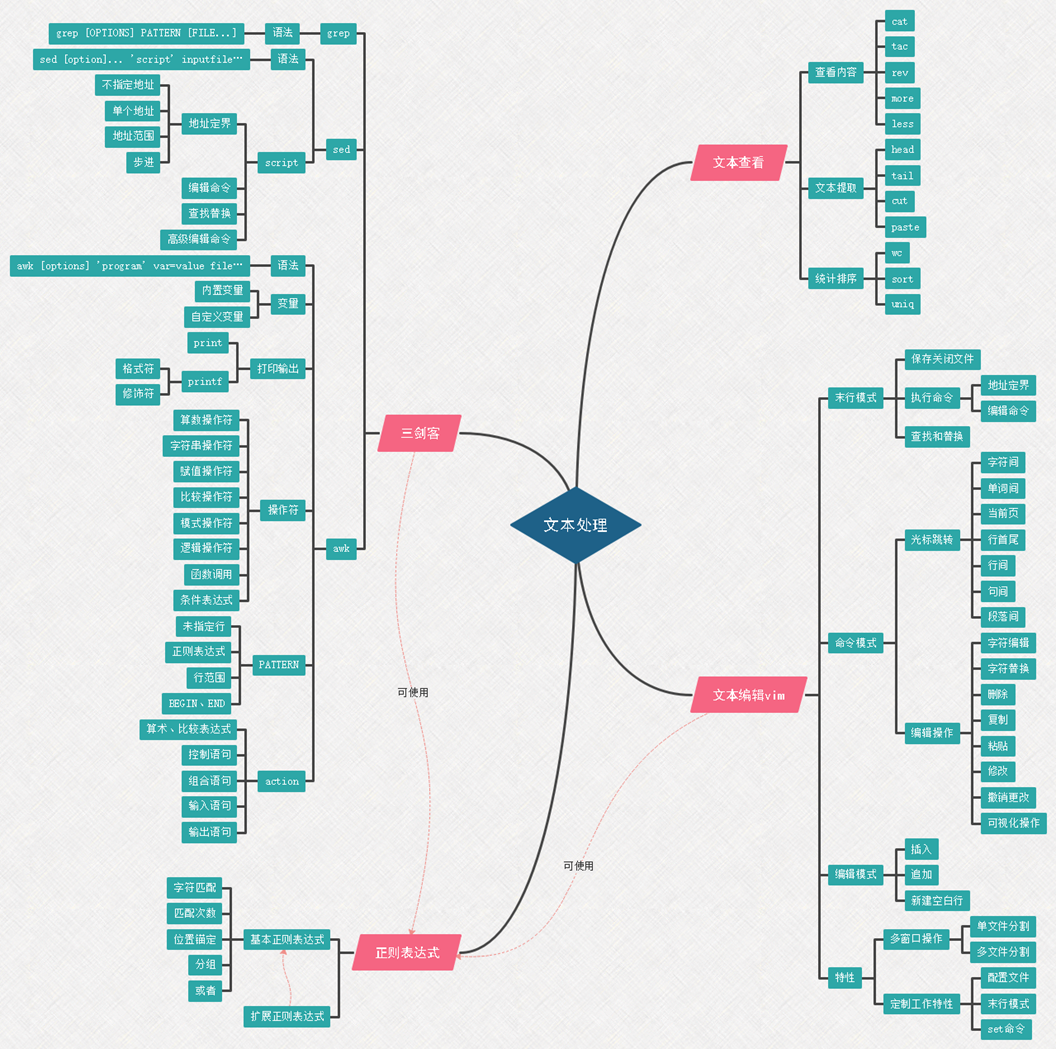
学习笔记
查看文本
查看文本内容
cat
-A:显示控制符
-E:显示行结束符$
-n:打印行号,显示空行
-b:打印行号,空行不编号
-s:压缩连续空白行
tac:反向查看文件内容
rev:文本每行倒序显示
分页查看
more
less
查看文件头尾内容
head
-c:前n个字节
-n:前n行
tail
-c
-n
-f:跟踪显示文件变化,常用于日志监控
watch -n 1 tail /var/log/massage
抽取文本内容
cut
-d:分隔符
-fN:指定字段
N:单个字段
,:多个离散字段
-:多个连续字段
混合使用
-c:按字符数
–output-delimiter=:指定输出分隔符
paste:合并两个文件的相同行的列为一行
-d 分隔符:默认TAB
-s:所有行合成一行显示
文本统计
wc
-l:行数
-w:单词数
-c:字节总数
-m:字符总数
-L:最长行的长度
文本排序
sort
-n:按数字大小排序
-r:逆序
-R:随机排序
–u:合并相同行
-f:忽略字符串中字符的大小写
-t c:字段界定符
-k N:指定列号
使用举例
echo {1..55} | tr ‘ ‘ ‘\n’ | sort -R | head -n 1
seq 55 | sort -R | head -n 1
echo $[RANDOM%55+1] | sort -R | head -n 1
cut -d’ ‘ -f1 access_log | sort -n | uniq -c | sort -nr | tr -s ‘ ‘ | cut -d’ ‘ -f3
last | sort | cut -d” ” -f1 | uniq -c | sort -nr
uniq
-c:显示连续重复行出现的次数
-d:仅显示重复过的行
-u:仅显示未重复过的行
文本处理三剑客
grep:文本过滤,过滤行
sed:行编辑器
awk:文本报告生成器
grep
根据指定模式搜索并打印匹配到的行
-v:反选
-i:忽略大小写
-n:显示匹配到的行号
-c:统计匹配到行的数量
-o:仅显示匹配到的字符串本身
-q:静默模式
-AN:当前行和后N行
-BN:当前行和前N行
-CN:当前行和前后各N行
nmap -v -sP 172.16.101.0/24 | grep -B1 up | grep “Nmap scan report for” | cut -d’ ‘ -f5
-e:多个模式之间实现逻辑or
-w:匹配整个单词
-E:使用正则表达式
-F:fgrep
df -h |grep “^/dev/sd” |grep -o ‘[[:digit:]]\+%’ |grep -o ‘[[:digit:]]\+’
正则表达式REGEXP
基本正则表达式
字符匹配
.:任意一个字符
[]:指定范围内的任意单个字符
[^]:指定范围外的任意单个字符
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] 小写字母 [:upper:] 大写字母
[:blank:] 空白字符(空格和制表符)
[:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广)
[:cntrl:] 不可打印的控制字符(退格、删除、警铃…)
[:digit:] 十进制数字 [:xdigit:]十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
匹配次数
*:任意次,工作于贪婪模式
.*:任意长度任意字符
\?:0次或1次
\+:1次或多次
\{m\}:m次
\{m,n\}:m-n次
\{,n\}:最多n次
\{m,\}:最少m次
位置锚定
^:行首锚定
$:行尾锚定
^PATTERN$
^$:空行
^[[:space:]]*$:空白行
\<或\b:词首锚定
\>或\b:词尾锚定
\<PATTERN\>
分组
\(\)
后向引用:\1、\2
或者 \|
ifconfig | grep ‘\(\([0-9]\{1,2\}\|1[0-9][0-9]\|2[0-4][0-9]\|25[0-5]\)\.\)\{3\}\([1-9]\|[1-9][0-9]\|1[0-9]\{2\}\|2[0-4][0-9]\|25[0-5]\)’
扩展正则表达式
字符匹配
.:任意单个字符
[]:指定范围内的单个字符
[^]:指定范围外的任意单个字符
次数匹配
*:任意次
?:最多1次
+:至少1次
{m}:m次
{m,n}:m-n次
位置锚定
^:行首锚定
$:行尾锚定
^PATTERN$
^$:空白行
\<或\b:词首锚定
\>或\b:词尾锚定
\<PATTERN\>
分组
()
后向引用:\1、\2
或者
|
ls *.rpm | grep -Eo “\.\<[[:alnum:]_]+\>\.rpm$” |cut -d. -f2 |sort |uniq -c
ls *.rpm | grep -Eo “\.[^.]+\.rpm$” |cut -d. -f2|sort |uniq -c
ifconfig | grep -E ‘(([0-9]{1,2}|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\.){3}([0-9]{1,2}|1[0-9][0-9]|2[0-4][0-9]|25[0-5])’
ls *.rpm |rev |cut -d. -f2|rev |sort |uniq -c
sed:行编辑器
语法
sed [option]… ‘script’ inputfile…
常用选项
-n:不输出模式空间内容到屏幕
-e:多点编辑
-f /path/to/script_file:从指定文件中读取编辑脚本
-r:支持使用扩展正则表达式
-i.bak:备份文件并原处编辑
script
‘地址+命令’
地址定界
不给地址:全文处理
单个地址
#:指定的行
$:最后一行
/PAT/:模式匹配到的每一行
地址范围
m,n
m,+n
/PAT1/,/PAT2/
m,/PAT/
步进:~
1~2:奇数行
2~2:偶数行
编辑命令
d:删除模式空间匹配的行,并进入下一轮循环
p:打印模式空间的内容,追加到默认输出后
a [\]text:在指定行后面追加文本,\n实现多行追加,\t为Tab
i [\]text:在行前面插入文本
c [\]text:替换行为单行或多行
w /path/to/somefile:保存模式匹配的行到指定文件
r /path/from/somefile:读取指定文件的文本至模式空间中匹配到行后
=:为模式空间中的行打印行号
!:模式空间中匹配行取反处理
查找替换
s///
替换标记
g:全局替换
p:显示替换成功的行
w /path/to/somefile:将替换成功的行保存在文件中
sed ‘s/quiet/& net.ifnames=0/’ /etc/default/grub
sed ‘/GRUB_CMDLINE_LINUX/s/”$/ net.ifnames=0 &/’ /etc/default/grub
sed -r ‘/GRUB_CMDLINE_LINUX/s/(.*)”/\1 net.ifnames=0″/’ /etc/default/grub
sed调用变量
“$VAR”
”’VAR”’
高级编辑命令
h:把模式空间中的内容覆盖至保持空间中
H:把模式空间中的内容追加至保持空间中
g:从保持空间中取出数据覆盖至模式空间
G:从保持空间中取出数据追加至模式空间
x:把模式空间和保持空间中的内容互换
n:读取匹配到的行的下一行至模式空间
N:追加匹配到的行的下一行至模式空间
d:删除模式空间中的行
D:删除多行模式空间的所有行
使用举例
sed -n ‘n;p’ FILE:显示偶数行
sed ‘1!G;h;$!d’ FILE:逆序显示文件内容
sed ‘$!N;$!D’ FILE:取出文件后两行
sed ‘$!d’ FILE:取出文件最后一行
sed ‘G’ FILE:每行后面追加空白行
sed ‘/^$/d;G’ FILE:将多个空白行合并成一个空白行,在每行后追加空白行
sed ‘n;d’ FILE:显示奇数行
sed -n ‘1!G;h;$p’ FILE:逆序显示文件内容
awk,报告生成器
基本用法
awk [options] ‘program’ var=value file…
awk [options] -f programfile var=value file…
awk [options] ‘BEGIN{ action;… } pattern{ action;… } END{ action;… }’ file …
awk 程序通常由:BEGIN语句块、能够使用模式匹配的通用语句块、 END语句块,共3部分组成
program通常是被单引号或双引号中
基本格式
awk [options] ‘program’ file…
options
-F 指明输入时用到的字段分隔符
-v var=value:自定义变量
program包括pattern{actions;…}
pattern部分指定语句的触发条件
BEGIN,END
actions指明对数据进行的处理操作
print,printf
分割符、域、记录
由分割符分割的字段(域)标记$1、$2…称为域标识,$0为所有域
文件的每一行称为记录
省略action,默认执行print $0操作
工作原理
1、执行BEGIN语句块中的语句,可选,进行如变量初始化、打印表头等操作
2、从文件或标准输入读取一行然后执行pattern{action;…}语句块,重复执行该操作直到文件最后一行。可选,没有提供pattern语句则默认执行{print}打印读取到的每一行
3、文件读取完毕后,执行END{action;…}语句块,可选,进行如打印所有行的分析结果的汇总信息等
print
print item1,item2…
,分隔符
输出的各item可以为字符串、数值、当前记录的字段、变量、awk表达式
省略item默认打印$0
变量
分为内置和自定义变量
内置变量
FS:输入字段分隔符,默认为空白字符
OFS:输出字段分隔符,默认为空白字符
RS:输入记录分隔符,指定输入时的换行符
ORS:输出记录分隔符,输出时用指定符号代替换行符
NF:字段数量
NR:记录号
FNR:各文件分别计数
FILENAME:当前文件名
ARGC:命令行参数个数,awk命令自己也是参数
ARGV:属组,保存命令行各参数
自定义变量
-v var=value
在program中直接定义
printf:格式化输出
printf “FORMAT”,item1,item2…
必须指定FORMAT
不自动换行,需显式指定\n
FORMAT中的格式符和各item一一对应
格式符
%c: 显示字符的ASCII码
%d, %i: 显示十进制整数
%e, %E:显示科学计数法数值
%f:显示为浮点数
%g, %G:以科学计数法或浮点形式显示数值
%s:显示字符串
%u:无符号整数
%%: 显示%自身
修饰符
m[.n]:m指定显示的宽度,n指定小数点后的精度
-:左对齐
+:显示数值的正负符号
操作符
算数操作符
x+y, x-y, x*y, x/y, x^y, x%y
-x: 转换为负数
+x: 转换为数值
字符串操作符:没有符号的操作符,字符串连接
赋值操作符
=, +=, -=, *=, /=, %=, ^=
++, —
比较操作符
==, !=, >, >=, <, <=
模式操作符
~:左边是否和右边匹配
!~:是否不匹配
逻辑操作符
&&、||、!
函数调用
function_name(argu1, argu2, …)
条件表达式
selector?if-true-expression:if-false-expression
awk -F: ‘{$3>=1000?usertype=”Common User”:usertype=”Sysadmin or SysUser”;printf “%15s:%-s\n”,$1,usertype}’ /etc/passwd
PATTERN
根据pattern条件过滤匹配的行,再做处理
未指定:空模式,匹配每一行
/正则表达式/
awk ‘/^UUID/{print $1}’ /etc/fstab
关系表达式,结果为真才会处理
真:非0,非空字符串
假:0,空字符串
awk -F: ‘$NF==”/bin/bash”{print $1,$NF}’ /etc/passwd
行范围
startline,endline:不支持直接给出数字格式
awk -F: ‘/^root\>/,/^nobody\>/{print $1}’ /etc/passwd
BEGIN、END
BEGIN{}:仅在开始处理文件中的文本之前执行一次
END{}:仅在文本处理完之后执行一次
awk -F: ‘BEGIN{print ” USER UID \n————— “}{print $1,$3}’END{print “==============”} /etc/passwd
action
常用分类
Expressions:算术,比较表达式等
Control statements:if, while等
Compound statements:组合语句
input statements
output statements:print等
控制语句
{ statements;… } 组合语句
if(condition) {statements;…}
if(condition) {statements;…} else {statements;…}
对awk取得的整行或某个字段做条件判断
awk -F: ‘{if($3>=1000) printf “Common user: %s\n”,$1;else printf “root or Sysuser: %s\n”,$1}’ /etc/passwd
while(conditon) {statments;…}
对一行内的多个字段逐一类似处理时使用
对数组中的各元素逐一处理时使用
awk ‘/^[[:space:]]*linux16/{i=1;while(i<=NF) {if(length($i)>=10){print $i,length($i)}; i++}}’ /etc/grub2.cfg
do {statements;…} while(condition)
不论真假,至少执行一次循环体
awk ‘BEGIN{ total=0;i=0;do{ total+=i;i++;}while(i<=100);print total}’
for(expr1;expr2;expr3) {statements;…}
awk ‘BEGIN{sum=0;for(i=1;i<=100;i++){sum+=i};print sum}’
awk ‘BEGIN{sum=0;i=1;while(i<=100){sum+=i;i++};print “sum=”sum” i=”i}’
for(variable assignment;condition;iteration process)
{for-body}
for(var in array) {for-body}:遍历属组元素
awk ‘/^[[:space:]]*linux16/{for(i=1;i<=NF;i++) {print $i,length($i)}}’ /etc/grub2.cfg
awk ‘{ips[$1]++}END{for(ip in ips){print ip,ips[ip]}}’ /var/log/httpd/access_log
break:结束所有循环
continue:结束本次循环,执行下一次循环
next:提前结束本次处理而直接进入下一次处理
awk -F: ‘{if($3%2!=0) next; print $1,$3}’ /etc/passwd
delete array[index]
delete array
exit
vim
打开文件
+N:打开文件后,光标处于第N行首
+/PATTERN:打开文件后,光标处于模式匹配到的第一行行首
-b:二进制方式打开文件
-d file… :比较多个文件
ex file或vim -e: 直接进入ex模式
vim三种模式
命令模式:默认,光标移动,剪切、粘贴文本
插入模式:编辑文本
末行模式:内置的命令行接口,保存、退出等
ESC退出当前模式
模式转换
命令模式–>插入模式
i:insert,在光标所在位置插入
I:在光标所在行首插入
a:append,在光标后面插入
A:在光标所在行尾插入
o:在光标所在行的下面新建一行插入
O:在光标所在行的上面新建一行插入
插入模式–>命令模式
ESC
命令模式–>末行模式
:
末行模式–命令模式
ESC
关闭文件
末行模式
:q
:q!
:wq
:x
命令模式
ZZ:保存退出
ZQ:不保存退出
命令模式
光标跳转
字符间:h、j、k、l,在命令前加数字可指定跳转的字符数
单词间
w:下一单词词首
e:当前或下一单词词尾
b:当前或下一单词词首
在命令前加数字可指定跳转的单词数
当前页
H:页首
M:中间行
L:页底
行首尾
^:行首第一个非空白字符
0:行首
$:行尾
行间
nG:第n行
G:最后一行
1G、gg:第一行
句间
(:上一句
):下一句
段落间
{:上一段
}:下一段
编辑操作
字符编辑
x:删除光标处字符,#x指定从光标处开始的字符数
xp:交换光标处和后一位字符的位置
~:转换大小写
J:删除当前行后的换行符
字符替换
r:替换光标处的字符
R:切换为”替换”模式
删除
d:结合跳转字符,实现指定范围删除
d$、d^、d0、dw、de、db
#CMD
dd:删除光标所在行,#dd删除多行
D:光标处删除至行尾,留空行
复制
y:结合跳转字符,实现指定范围复制
y$、y^、y0、yw、ye、yb
#CMD
yy:光标所在处整行复制,#yy复制多行
Y:整行复制
粘贴
p:若缓存区为整行,则粘贴到下一行;否则粘贴至光标后面
P:若缓存区为整行,则粘贴到上一行;否则粘贴至光标前面
修改
c:结合跳转字符,实现指定范围修改
c$、c^、c0、cw、ce、cb
#CMD
cc:删除当前行并输入新内容,#cc
C:删除光标到行尾并插入
撤销更改
u:最近一次更改,#n最近#次
U:光标落在该行后的所有更改
Ctrl-r:重做最后的撤销
.:重复前一操作
#.:重复前一操作#次
可视化操作
选择文本块
v:字符
V:行
Ctrl-v:块
结合字符跳转键使用
突出显示的文字可执行删除、复制、变更、过滤、搜索、替换等
末行模式
命令提示符为:
可用命令
w
wq
x
q
q!
r filename
w filename
!CMD:执行命令
r!CMD:读入命令的输出
地址定界
:start,end
#:第#行
m,n:m-n行
m,+n:m行和其后n行
.:当前行
$:最后一行
%:全文
/PAT1/,/PAT2/:PAT1到PAT2第一次匹配
#,/PAT/
/PAT/,#
使用方式:后跟编辑命令
d
y
w filename:指定范围另存到指定文件中
r filename:在指定范围出入指定文件中的内容
查找
/PAT:从光标处向文件尾部查找
?PAT:从光标处向文件首部查找
n:和命令同向
N:和命令反向
查找并替换
s/要查找的内容/替换为的内容/修饰符
要查找的内容:可用模式匹配
替换为的内容:不能使用模式,可使用\1、\2等后向引用,&引用前面查找到的整个内容
修饰符
i:忽略大小写
g:全局替换,默认只替换每行第一次匹配
gc:全局替换,替换前询问
分隔符/可使用其他字符
多个窗口
多文件分割
vim -o|O file1 file2
-o:水平分割
-O:垂直分割
窗口间切换:Ctrl-w,方向键
单文件分割
Ctrl-w,s:水平
Ctrl-w,v:垂直
Ctrl-w,q:取消相邻窗口
Ctrl-w,o:取消所有窗口
:wqall:退出
定制工作特性
配置文件
全局:/etc/vimrc
个人:~/.vimrc
末行模式:对当前vim进程有效
常用配置
行号
显示:set nu
不显示:set nonu
忽略字符大小写
忽略:set ic
不忽略:set noic
自动缩进
启用:set ai
禁用:set noai
智能缩进
启用:set si
禁用:set nosi
高亮搜索
启用:set hlsearch
禁用:set nohlsearch
语法高亮
启用:syntax on
禁用:syntax off
显示Tab和换行符
启用:set list
禁用:set nolist
文件格式
启用windows格式:set ff=dos
启用unix格式:set ff=unix
设置文本宽度
启用:set textwidth=65
禁用:set wrapmargin=15
设置光标所在行标识线
启用:set cul
禁用:set nocul
复制保留格式
启用:set paste
禁用:set nopaste
设置Tab为4个空格
set ts=4
set expandtab
set autoindent
原创文章,作者:ZBD20,如若转载,请注明出处:http://www.178linux.com/92545
