

grep 是一个文本过滤工具
egrp:基本正则表达式
fgrp:扩展正则表达式
grep的命令格式 “grep 目标 文件”
grep还支持变量 “grep $ 变量 文件”
grep还支持命令 “grep 命令 文件”
grep数标准输入,所有可以和管道符结合
标准输出 | grep标准输入
“grep 命令 文件” grep命令格式的示例
![]()
![]()
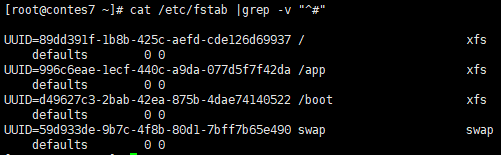
“grep -v 目标 文件” 显示不包含目标的其他内容 。 下面表示非#号开头的行

“grep -i 目标 文件” 忽略目标的大小写
![]()
![]()
“grep -n 目标 文件” 目标文件在第几行 ,并显示序列号
,并显示序列号
![]()
![]()
“grep -c 目标 文件” 查看目标这个有几行
![]()
![]()
“grep -o 目标 文件” 只显示相关的字符,一行的其他不显示

“grep -q 目标 文件” 不显示输出的内容,可以用 echo $?查看, 非0代表没有找到目标![]()
![]()
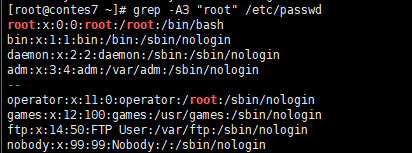
“grep -A 目标 文件” A后面加个数字包含目标的后几行
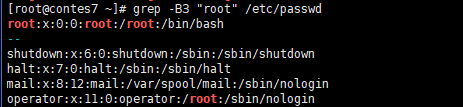
“grep -B 目标 文件” B后面加数字显示包含目标的前几行
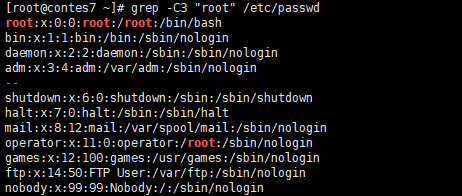
“grep -C 目标 文件” C前面加个数字显示包含目标的前后几行
“grep -e 目标1 -e 目标2 文件” 包括目标1或者目标2 或者的关系,一行不显示两目标
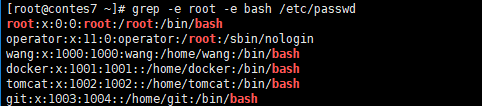
“”grep -w 单词 文件“” 在文件里面是单词的目标 
![]()
![]()
字母数字加下划线都是字母的一部分,其他都不是字母的一部分
![]()
![]()
grep -f 后面是跟的文件,将目标放在几个文件里面 ,然后执行grep -f 


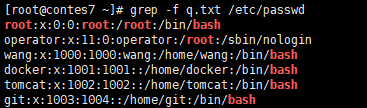
正则表达式
处理文本内容 通过特定的符号来匹配或者控制
BRE 基本正则表达式
ERE 扩展正则表达式
元字符分类:字符匹配 ,匹配次数, 位置锚定, 分组
字符匹配
. 表示文件内容任意一个字符“a..d” abcd 两个..表示两个字符。a代表一个字符,.代表一个字符,c代表一个字符
![]()
![]()
[ . ] 点放在中括号 代表.点的本意
转义 \ . 代表. 点字符的本意,中间的点转义到原来.的意思
![]()
![]()
grep “r[abc]t” 取中括号里面的任意的一个字符
![]()
![]()
grep “r[^abc]t” 除了中括号里面的任意字符
![]()
![]()
匹配次数 :某一个字符出现的次数
*表示字符前面出现任意次或者0次? *表示前面出现的相同字符是不确定的

.* 代表任意长度的任意字符串, .代表一个字符,* 表示字符前面出现任意次或者0次
![]()
![]()
\ ? 匹配字符前面出现一次或者0次 
![]()
![]()
\ + 匹配字符前面出现一次或者一次以上
![]()
![]()
\ {数字 \ } 精确单词匹配多少次,前面的o必须出现22次
![]()
![]()
\ {数字,\ } 大于多少次 ,前面的o必须出现10次以上
![]()
![]()
\ [数字 , 数字 \ } 前面取得数字必须出现的次数大于多少并小于多少次:
![]()
![]()
多个位置锚定
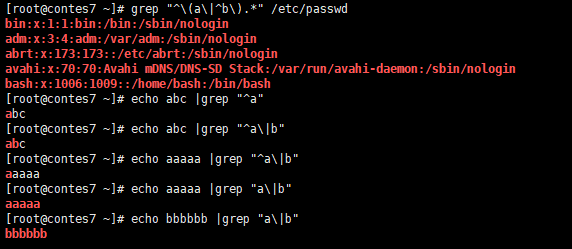
^ 表示行首 锚定 ^ root root开头的行
![]()
![]()
$ 表示行尾 的行
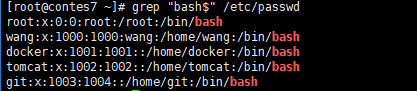
“\ < root” root位于一行的行左 以root词开头的行 

“\ > root” root位于一行的行左右 词尾 

“\ b目标 \b” 表示单词的边界
![]()
![]()
分组 表示的是一个单词出现几次
\ (wang\ ) 表示分组 , \ {3\ } 表示wang出现3次

![]()
![]()
后向引用 \1 必须和前面的目标一样

![]()
![]()


本文来自投稿,不代表Linux运维部落立场,如若转载,请注明出处:http://www.178linux.com/95322

