

用户组
passwd 用于设置用户的认证信息,包括用户密码、密码过期时间等。系统管理者则能用它管理系统用户的密码。只有管理者可以指定用户名称,一般用户只能变更自己的密码。
选项
d:删除密码,仅有系统管理者才能使用;
-f:强制执行;
-k:设置只有在密码过期失效后,方能更新;
-l:锁住密码;
-s:列出密码的相关信息,仅有系统管理者才能使用;
-u:解开已上锁的帐号。
实例
如果是普通用户执行passwd只能修改自己的密码。如果新建用户后,要为新用户创建密码,则用passwd用户名,注意要以root用户的权限来创建。
[root@localhost ~]# passwd linuxde //更改或创建linuxde用户的密码;
Changing password for user linuxde.
New UNIX password: //请输入新密码;
Retype new UNIX password: //再输入一次;
passwd: all authentication tokens updated successfully. //成功;
普通用户如果想更改自己的密码,直接运行passwd即可,比如当前操作的用户是linuxde。
[linuxde@localhost ~]$ passwd
Changing password for user linuxde. //更改linuxde用户的密码;
(current) UNIX password: //请输入当前密码;
New UNIX password: //请输入新密码;
Retype new UNIX password: //确认新密码;
passwd: all authentication tokens updated successfully. //更改成功;
比如我们让某个用户不能修改密码,可以用-l选项来锁定:
[root@localhost ~]# passwd -l linuxde //锁定用户linuxde不能更改密码;
Locking password for user linuxde.
passwd: Success //锁定成功;
[linuxde@localhost ~]# su linuxde //通过su切换到linuxde用户;
[linuxde@localhost ~]$ passwd //linuxde来更改密码;
Changing password for user linuxde.
Changing password for linuxde
(current) UNIX password: //输入linuxde的当前密码;
passwd: Authentication token manipulation error //失败,不能更改密码;
再来一例:
[root@localhost ~]# passwd -d linuxde //清除linuxde用户密码;
Removing password for user linuxde.
passwd: Success //清除成功;
[root@localhost ~]# passwd -S linuxde //查询linuxde用户密码状态;
Empty password. //空密码,也就是没有密码;
注意:当我们清除一个用户的密码时,登录时就无需密码,这一点要加以注意
useradd 用于Linux中创建的新的系统用户。useradd可用来建立用户帐号。帐号建好之后,再用passwd设定帐号的密码.而可用userdel删除帐号。使用useradd指令所建立的帐号,实际上是保存在/etc/passwd文本文件中。
选项
-c<备注>:加上备注文字。备注文字会保存在passwd的备注栏位中;
-d<登入目录>:指定用户登入时的启始目录;
-D:变更预设值;
-e<有效期限>:指定帐号的有效期限;
-f<缓冲天数>:指定在密码过期后多少天即关闭该帐号;
-g<群组>:指定用户所属的群组;
-G<群组>:指定用户所属的附加群组;
-m:自动建立用户的登入目录;
-M:不要自动建立用户的登入目录;
-n:取消建立以用户名称为名的群组;
-r:建立系统帐号;
-s<shell>:指定用户登入后所使用的shell;
-u<uid>:指定用户id。
实例
新建用户加入组:
useradd –g sales jack –G company,employees //-g:加入主要组、-G:加入次要组
建立一个新用户账户,并设置ID:
useradd caojh -u 544
需要说明的是,设定ID值时尽量要大于500,以免冲突。因为Linux安装后会建立一些特殊用户,一般0到499之间的值留给bin、mail这样的系统账号
usermod 用于修改用户的基本信息。usermod命令不允许你改变正在线上的使用者帐号名称。当usermod命令用来改变user id,必须确认这名user没在电脑上执行任何程序。你需手动更改使用者的crontab档。也需手动更改使用者的at工作档。采用NIS server须在server上更动相关的NIS设定。
选项
-c<备注>:修改用户帐号的备注文字;
-d<登入目录>:修改用户登入时的目录;
-e<有效期限>:修改帐号的有效期限;
-f<缓冲天数>:修改在密码过期后多少天即关闭该帐号;
-g<群组>:修改用户所属的群组;
-G<群组>;修改用户所属的附加群组;
-l<帐号名称>:修改用户帐号名称;
-L:锁定用户密码,使密码无效;
-s<shell>:修改用户登入后所使用的shell;
-u<uid>:修改用户ID;
-U:解除密码锁定。
实例
将newuser2添加到组staff中:
usermod -G staff newuser2
修改newuser的用户名为newuser1:
usermod -l newuser1 newuser
锁定账号newuser1:
usermod -L newuser1
解除对newuser1的锁定:
usermod -U newuser1
userdel 用于删除给定的用户,以及与用户相关的文件。若不加选项,则仅删除用户帐号,而不删除相关文件。
选项
-f:强制删除用户,即使用户当前已登录;
-r:删除用户的同时,删除与用户相关的所有文件。
实例
userdel命令很简单,比如我们现在有个用户linuxde,其家目录位于/var目录中,现在我们来删除这个用户:
userdel linuxde //删除用户linuxde,但不删除其家目录及文件;
userdel -r linuxde //删除用户linuxde,其家目录及文件一并删除;
请不要轻易用-r选项;他会删除用户的同时删除用户所有的文件和目录,切记如果用户目录下有重要的文件,在删除前请备份。
其实也有最简单的办法,但这种办法有点不安全,也就是直接在/etc/passwd中删除您想要删除用户的记录;但最好不要这样做,/etc/passwd是极为重要的文件,可能您一不小心会操作失误。
groupadd 用于创建一个新的工作组,新工作组的信息将被添加到系统文件中
选项
-g:指定新建工作组的id;
-r:创建系统工作组,系统工作组的组ID小于500;
-K:覆盖配置文件“/ect/login.defs”;
-o:允许添加组ID号不唯一的工作组。
实例
建立一个新组,并设置组ID加入系统:
groupadd -g 344 linuxde
此时在/etc/passwd文件中产生一个组ID(GID)是344的项目。
groupmod 更改群组识别码或名称。需要更改群组的识别码或名称时,可用groupmod指令来完成这项工作。
选项
-g<群组识别码>:设置欲使用的群组识别码;
-o:重复使用群组识别码;
-n<新群组名称>:设置欲使用的群组名称。
实例
[root@jb51.net ~]# groupadd linuxso
[root@jb51.net ~]# tail -1 /etc/group
linuxso:x:500:
[root@jb51.net ~]# tail -1 /etc/group
linuxso:x:500:
[root@jb51.net ~]# groupmod -n linux linuxso
[root@jb51.net ~]# tail -1 /etc/group
linux:x:500:
grouped 用于删除指定的工作组,本命令要修改的系统文件包括/ect/group和/ect/gshadow。若该群组中仍包括某些用户,则必须先删除这些用户后,方能删除群组。
实例
groupadd damon //创建damon工作组
groupdel damon //删除这个工作组
useradd 用于Linux中创建的新的系统用户。useradd可用来建立用户帐号。帐号建好之后,再用passwd设定帐号的密码.而可用userdel删除帐号。使用useradd指令所建立的帐号,实际上是保存在/etc/passwd文本文件中
选项
-c<备注>:加上备注文字。备注文字会保存在passwd的备注栏位中;
-d<登入目录>:指定用户登入时的启始目录;
-D:变更预设值;
-e<有效期限>:指定帐号的有效期限;
-f<缓冲天数>:指定在密码过期后多少天即关闭该帐号;
-g<群组>:指定用户所属的群组;
-G<群组>:指定用户所属的附加群组;
-m:自动建立用户的登入目录;
-M:不要自动建立用户的登入目录;
-n:取消建立以用户名称为名的群组;
-r:建立系统帐号;
-s<shell>:指定用户登入后所使用的shell;
-u<uid>:指定用户id。
实例
新建用户加入组:
useradd –g sales jack –G company,employees //-g:加入主要组、-G:加入次要组
建立一个新用户账户,并设置ID:
useradd caojh -u 544
需要说明的是,设定ID值时尽量要大于500,以免冲突。因为Linux安装后会建立一些特殊用户,一般0到499之间的值留给bin、mail这样的系统账号。
usermod 用于修改用户的基本信息。usermod命令不允许你改变正在线上的使用者帐号名称。当usermod命令用来改变user id,必须确认这名user没在电脑上执行任何程序。你需手动更改使用者的crontab档。也需手动更改使用者的at工作档。采用NIS server须在server上更动相关的NIS设定。
选项
-c<备注>:修改用户帐号的备注文字;
-d<登入目录>:修改用户登入时的目录;
-e<有效期限>:修改帐号的有效期限;
-f<缓冲天数>:修改在密码过期后多少天即关闭该帐号;
-g<群组>:修改用户所属的群组;
-G<群组>;修改用户所属的附加群组;
-l<帐号名称>:修改用户帐号名称;
-L:锁定用户密码,使密码无效;
-s<shell>:修改用户登入后所使用的shell;
-u<uid>:修改用户ID;
-U:解除密码锁定
实例
将newuser2添加到组staff中:
usermod -G staff newuser2
修改newuser的用户名为newuser1:
usermod -l newuser1 newuser
锁定账号newuser1:
usermod -L newuser1
解除对newuser1的锁定:
usermod -U newuser1
id 可以显示真实有效的用户ID(UID)和组ID(GID)。UID 是对一个用户的单一身份标识。组ID(GID)则对应多个UID。id命令已经默认预装在大多数Linux系统中。要使用它,只需要在你的控制台输入id。不带选项输入id会显示如下。结果会使用活跃用户。
选项
-g或–group 显示用户所属群组的ID。
-G或–groups 显示用户所属附加群组的ID。
-n或–name 显示用户,所属群组或附加群组的名称。
-r或–real 显示实际ID。
-u或–user 显示用户ID。
-help 显示帮助。
-version 显示版本信息。
实例
[root@localhost ~]# id
uid=0(root) gid=0(root) groups=0(root),1(bin),2(daemon),3(sys),4(adm),6(disk),10(wheel)
su 用于切换当前用户身份到其他用户身份,变更时须输入所要变更的用户帐号与密码。
选项
-c<指令>或–command=<指令>:执行完指定的指令后,即恢复原来的身份;
-f或——fast:适用于csh与tsch,使shell不用去读取启动文件;
-l或——login:改变身份时,也同时变更工作目录,以及HOME,SHELL,USER,logname。此外,也会变更PATH变量;
-m,-p或–preserve-environment:变更身份时,不要变更环境变量;
-s<shell>或–shell=<shell>:指定要执行的shell;
–help:显示帮助;
–version;显示版本信息。
实例
变更帐号为root并在执行ls指令后退出变回原使用者:
su -c ls root
变更帐号为root并传入-f选项给新执行的shell:
su root -f
变更帐号为test并改变工作目录至test的家目录:
su –test
chage 用来修改帐号和密码的有效期限
选项
-m:密码可更改的最小天数。为零时代表任何时候都可以更改密码。
-M:密码保持有效的最大天数。
-w:用户密码到期前,提前收到警告信息的天数。
-E:帐号到期的日期。过了这天,此帐号将不可用。
-d:上一次更改的日期。
-i:停滞时期。如果一个密码已过期这些天,那么此帐号将不可用。
-l:例出当前的设置。由非特权用户来确定他们的密码或帐号何时过期。
实例
可以编辑/etc/login.defs来设定几个参数,以后设置口令默认就按照参数设定为准:
PASS_MAX_DAYS 99999
PASS_MIN_DAYS 0
PASS_MIN_LEN 5
PASS_WARN_AGE 7
当然在/etc/default/useradd可以找到如下2个参数进行设置:
# useradd defaults file
GROUP=100
HOME=/home
INACTIVE=-1
EXPIRE=
SHELL=/bin/bash
SKEL=/etc/skel
CREATE_MAIL_SPOOL=yes
通过修改配置文件,能对之后新建用户起作用,而目前系统已经存在的用户,则直接用chage来配置。
我的服务器root帐户密码策略信息如下:
[root@linuxde ~]# chage -l root
最近一次密码修改时间 : 3月 12, 2013
密码过期时间 :从不
密码失效时间 :从不
帐户过期时间 :从不
两次改变密码之间相距的最小天数 :0
两次改变密码之间相距的最大天数 :99999
在密码过期之前警告的天数 :7
我可以通过如下命令修改我的密码过期时间:
[root@linuxde ~]# chage -M 60 root
[root@linuxde ~]# chage -l root
最近一次密码修改时间 : 3月 12, 2013
密码过期时间 : 5月 11, 2013
密码失效时间 :从不
帐户过期时间 :从不
两次改变密码之间相距的最小天数 :0
两次改变密码之间相距的最大天数 :60
在密码过期之前警告的天数 :9
然后通过如下命令设置密码失效时间:
[root@linuxde ~]# chage -I 5 root
[root@linuxde ~]# chage -l root
最近一次密码修改时间 : 3月 12, 2013
密码过期时间 : 5月 11, 2013
密码失效时间 : 5月 16, 2013
帐户过期时间 :从不
两次改变密码之间相距的最小天数 :0
两次改变密码之间相距的最大天数 :60
在密码过期之前警告的天数 :9
gpasswd 是Linux下工作组文件/etc/group和/etc/gshadow管理工具。
选项
-a:添加用户到组;
-d:从组删除用户;
-A:指定管理员;
-M:指定组成员和-A的用途差不多;
-r:删除密码;
-R:限制用户登入组,只有组中的成员才可以用newgrp加入该组
实例
如系统有个peter账户,该账户本身不是groupname群组的成员,使用newgrp需要输入密码即可。
gpasswd groupname
让使用者暂时加入成为该组成员,之后peter建立的文件group也会是groupname。所以该方式可以暂时让peter建立文件时使用其他的组,而不是peter本身所在的组。
所以使用gpasswd groupname设定密码,就是让知道该群组密码的人可以暂时切换具备groupname群组功能的。
gpasswd -A peter users
这样peter就是users群组的管理员,就可以执行下面的操作:
gpasswd -a mary users
gpasswd -a allen users
注意:添加用户到某一个组 可以使用usermod -G group_name user_name这个命令可以添加一个用户到指定的组,但是以前添加的组就会清空掉。
所以想要添加一个用户到一个组,同时保留以前添加的组时,请使用gpasswd这个命令来添加操作用户:
gpasswd -a user_name group_name
chown 改变某个文件或目录的所有者和所属的组,该命令可以向某个用户授权,使该用户变成指定文件的所有者或者改变文件所属的组。用户可以是用户或者是用户D,用户组可以是组名或组id。文件名可以使由空格分开的文件列表,在文件名中可以包含通配符。
选项
-c或——changes:效果类似“-v”参数,但仅回报更改的部分;
-f或–quite或——silent:不显示错误信息;
-h或–no-dereference:只对符号连接的文件作修改,而不更改其他任何相关文件;
-R或——recursive:递归处理,将指定目录下的所有文件及子目录一并处理;
-v或——version:显示指令执行过程;
–dereference:效果和“-h”参数相同;
–help:在线帮助;
–reference=<参考文件或目录>:把指定文件或目录的拥有者与所属群组全部设成和参考文件或目录的拥有者与所属群组相同;
–version:显示版本信息。
实例
将目录/usr/meng及其下面的所有文件、子目录的文件主改成 liu:
chown -R liu /usr/meng
umask 用来设置限制新建文件权限的掩码。当新文件被创建时,其最初的权限由文件创建掩码决定。用户每次注册进入系统时,umask命令都被执行, 并自动设置掩码mode来限制新文件的权限。用户可以通过再次执行umask命令来改变默认值,新的权限将会把旧的覆盖掉。
选项
-p:输出的权限掩码可直接作为指令来执行;
-S:以符号方式输出权限掩码。
实例
利用umask命令可以指定哪些权限将在新文件的默认权限中被删除。例如,可以使用下面的命令创建掩码,使得组用户的写权限,其他用户的读、写和执行权限都被取消:
umask u=, g=w, o=rwx
执行该命令以后,对于下面创建的新文件,其文件主的权限未做任何改变,而组用户没有写权限,其他用户的所有权限都被取消。
应注意:操作符“=”在umask命令和chmod命令中的作用恰恰相反。在chmod命令中,利用它来设置指定的权限,而其余权限则被删除;但是在umask命令中,它将在原有权限的基础上删除指定的权限。
不能直接利用umask命令创建一个可执行的文件,用户只能在其后利用chmod命令使它具有执行权限。假设执行了命令umask u=, g=w, o=rwx,虽然在命令行中,没有删去文件主和组用户的执行权限,但默认的文件权限还是640(即 rw-r—–),而不是750(rwxr-x—)。但是,如果创建的是目录或者通过编译程序创建的一个可执行文件,将不受此限制。在这种情况 下,会设置文件的执行权限。
也可以使用八进制数值来设置mode。由于在umask中所指定的权限是要从文件中删除的,所以,如果该文件原来的初始化权限是777,那么执行命令umask 022以后,该文件的权限将变为755:如果该文件原来的初始化权限是666,那么该文件的权限将变为644。
可以使用下面的命令检查新创建文件的默认权限:
umask –s
选项-s表示以字符形式显示当前的掩码。如果直接输入umask命令,不带任何参数,那么将以八进制形式显示当前的掩码。系统默认的掩码是0022
Chattr 用来改变文件属性。这项指令可改变存放在ext2文件系统上的文件或目录属性,这些属性共有以下8种模式
a:让文件或目录仅供附加用途;
b:不更新文件或目录的最后存取时间;
c:将文件或目录压缩后存放;
d:将文件或目录排除在倾倒操作之外;
i:不得任意更动文件或目录;
s:保密性删除文件或目录;
S:即时更新文件或目录;
u:预防意外删除。
选项
-R:递归处理,将指令目录下的所有文件及子目录一并处理;
-v<版本编号>:设置文件或目录版本;
-V:显示指令执行过程;
+<属性>:开启文件或目录的该项属性;
-<属性>:关闭文件或目录的该项属性;
=<属性>:指定文件或目录的该项属性。
实例
用chattr命令防止系统中某个关键文件被修改:
chattr +i /etc/fstab
然后试一下rm、mv、rename等命令操作于该文件,都是得到Operation not permitted的结果。
让某个文件只能往里面追加内容,不能删除,一些日志文件适用于这种操作:
chattr +a /data1/user_act.log
tac 用于将文件已行为单位的反序输出,即第一行最后显示,最后一行先显示
选项
-a或——append:将内容追加到文件的末尾;
-i或——ignore-interrupts:忽略中断信号
实例
rev 将文件中的每行内容以字符为单位反序输出,即第一个字符最后输出,最后一个字符最先输出,依次类推。
实例
[root@localhost ~]# cat iptables.bak
# Generated by iptables-save v1.3.5 on Thu Dec 26 21:25:15 2013
*filter
:INPUT DROP [48113:2690676]
:FORWARD accept [0:0]
:OUTPUT ACCEPT [3381959:1818595115]
-A INPUT -i lo -j ACCEPT
-A INPUT -p tcp -m tcp –dport 22 -j ACCEPT
-A INPUT -p tcp -m tcp –dport 80 -j ACCEPT
-A INPUT -m state –state RELATED,ESTABLISHED -j ACCEPT
-A INPUT -p icmp -j ACCEPT
-A OUTPUT -o lo -j ACCEPT
COMMIT
# Completed on Thu Dec 26 21:25:15 2013
[root@localhost ~]# rev iptables.bak
3102 51:52:12 62 ceD uhT no 5.3.1v evas-selbatpi yb detareneG #
retlif*
]6760962:31184[ PORD TUPNI:
]0:0[ TPECCA DRAWROF:
]5115958181:9591833[ TPECCA TUPTUO:
TPECCA j- ol i- TUPNI A-
TPECCA j- 22 tropd– pct m- pct p- TUPNI A-
TPECCA j- 08 tropd– pct m- pct p- TUPNI A-
TPECCA j- DEHSILBATSE,DETALER etats– etats m- TUPNI A-
TPECCA j- pmci p- TUPNI A-
TPECCA j- ol o- TUPTUO A-
TIMMOC
3102 51:52:12 62 ceD uhT no detelpmoC #
More 是一个基于vi编辑器文本过滤器,它以全屏幕的方式按页显示文本文件的内容,支持vi中的关键字定位操作。more名单中内置了若干快捷键,常用的有H(获得帮助信息),Enter(向下翻滚一行),空格(向下滚动一屏),Q(退出命令)。
该命令一次显示一屏文本,满屏后停下来,并且在屏幕的底部出现一个提示信息,给出至今己显示的该文件的百分比:–More–(XX%)可以用下列不同的方法对提示做出回答:
按Space键:显示文本的下一屏内容。
按Enier键:只显示文本的下一行内容。
按斜线符|:接着输入一个模式,可以在文本中寻找下一个相匹配的模式。
按H键:显示帮助屏,该屏上有相关的帮助信息。
按B键:显示上一屏内容。
按Q键:退出rnore命令。
选项
-<数字>:指定每屏显示的行数;
-d:显示“[press space to continue,’q’ to quit.]”和“[Press ‘h’ for instructions]”;
-c:不进行滚屏操作。每次刷新这个屏幕;
-s:将多个空行压缩成一行显示;
-u:禁止下划线;
+<数字>:从指定数字的行开始显示
实例
显示文件file的内容,但在显示之前先清屏,并且在屏幕的最下方显示完核的百分比。
more -dc file
显示文件file的内容,每10行显示一次,而且在显示之前先清屏。
more -c -10 file
less 的作用与more十分相似,都可以用来浏览文字档案的内容,不同的是less命令允许用户向前或向后浏览文件,而more命令只能向前浏览。用less命令显示文件时,用PageUp键向上翻页,用PageDown键向下翻页。要退出less程序,应按Q键
选项
-e:文件内容显示完毕后,自动退出;
-f:强制显示文件;
-g:不加亮显示搜索到的所有关键词,仅显示当前显示的关键字,以提高显示速度;
-l:搜索时忽略大小写的差异;
-N:每一行行首显示行号;
-s:将连续多个空行压缩成一行显示;
-S:在单行显示较长的内容,而不换行显示;
-x<数字>:将TAB字符显示为指定个数的空格字符。
Head 命令用于显示文件的开头的内容。在默认情况下,head命令显示文件的头10行内容。
选项
-n<数字>:指定显示头部内容的行数;
-c<字符数>:指定显示头部内容的字符数;
-v:总是显示文件名的头信息;
-q:不显示文件名的头信息。
tail 命令用于输入文件中的尾部内容。tail命令默认在屏幕上显示指定文件的末尾10行。如果给定的文件不止一个,则在显示的每个文件前面加一个文件名标题。如果没有指定文件或者文件名为“-”,则读取标准输入。
选项
–retry:即是在tail命令启动时,文件不可访问或者文件稍后变得不可访问,都始终尝试打开文件。使用此选项时需要与选项“——follow=name”连用;
-c<N>或——bytes=<N>:输出文件尾部的N(N为整数)个字节内容;
-f<name/descriptor>或;–follow<nameldescript>:显示文件最新追加的内容。“name”表示以文件名的方式监视文件的变化。“-f”与“-fdescriptor”等效;
-F:与选项“-follow=name”和“–retry”连用时功能相同;
-n<N>或——line=<N>:输出文件的尾部N(N位数字)行内容。
–pid=<进程号>:与“-f”选项连用,当指定的进程号的进程终止后,自动退出tail命令;
-q或——quiet或——silent:当有多个文件参数时,不输出各个文件名;
-s<秒数>或——sleep-interal=<秒数>:与“-f”选项连用,指定监视文件变化时间隔的秒数;
-v或——verbose:当有多个文件参数时,总是输出各个文件名;
–help:显示指令的帮助信息;
–version:显示指令的版本信息。
实例
ail file (显示文件file的最后10行)
tail +20 file (显示文件file的内容,从第20行至文件末尾)
tail -c 10 file (显示文件file的最后10个字符)
cut 命令用来显示行中的指定部分,删除文件中指定字段。cut经常用来显示文件的内容,类似于下的type命令。
选项
-b:仅显示行中指定直接范围的内容;
-c:仅显示行中指定范围的字符;
-d:指定字段的分隔符,默认的字段分隔符为“TAB”;
-f:显示指定字段的内容;
-n:与“-b”选项连用,不分割多字节字符;
–complement:补足被选择的字节、字符或字段;
–out-delimiter=<字段分隔符>:指定输出内容是的字段分割符;
–help:显示指令的帮助信息;
–version:显示指令的版本信息。
实例
例如有一个学生报表信息,包含No、Name、Mark、Percent:
[root@localhost text]# cat test.txt
No Name Mark Percent
01 tom 69 91
02 jack 71 87
03 alex 68 98
使用 -f 选项提取指定字段:
[root@localhost text]# cut -f 1 test.txt
No
01
02
03
[root@localhost text]# cut -f2,3 test.txt
Name Mark
tom 69
jack 71
alex 68
–complement 选项提取指定字段之外的列(打印除了第二列之外的列):
[root@localhost text]# cut -f2 –complement test.txt
No Mark Percent
01 69 91
02 71 87
03 68 98
使用 -d 选项指定字段分隔符:
[root@localhost text]# cat test2.txt
No;Name;Mark;Percent
01;tom;69;91
02;jack;71;87
03;alex;68;98
[root@localhost text]# cut -f2 -d”;” test2.txt
Name
tom
jack
alex
指定字段的字符或者字节范围
cut命令可以将一串字符作为列来显示,字符字段的记法:
N-:从第N个字节、字符、字段到结尾;
N-M:从第N个字节、字符、字段到第M个(包括M在内)字节、字符、字段;
-M:从第1个字节、字符、字段到第M个(包括M在内)字节、字符、字段。
上面是记法,结合下面选项将摸个范围的字节、字符指定为字段:
-b 表示字节;
-c 表示字符;
-f 表示定义字段。
示例
[root@localhost text]# cat test.txt
abcdefghijklmnopqrstuvwxyz
abcdefghijklmnopqrstuvwxyz
abcdefghijklmnopqrstuvwxyz
abcdefghijklmnopqrstuvwxyz
abcdefghijklmnopqrstuvwxyz
打印第1个到第3个字符:
[root@localhost text]# cut -c1-3 test.txt
abc
abc
abc
abc
abc
打印前2个字符:
[root@localhost text]# cut -c-2 test.txt
ab
ab
ab
ab
ab
打印从第5个字符开始到结尾:
[root@localhost text]# cut -c5- test.txt
efghijklmnopqrstuvwxyz
paste 命令用于将多个文件按照列队列进行合并
选项
-d<间隔字符>或–delimiters=<间隔字符>:用指定的间隔字符取代跳格字符;
-s或——serial串列进行而非平行处理。
Wc 命令用来计算数字。利用wc指令我们可以计算文件的Byte数、字数或是列数,若不指定文件名称,或是所给予的文件名为“-”,则wc指令会从标准输入设备读取数据。
选项
-c或–bytes或——chars:只显示Bytes数;
-l或——lines:只显示列数;
-w或——words:只显示字数
Sort 命令是在Linux里非常有用,它将文件进行排序,并将排序结果标准输出。sort命令既可以从特定的文件,也可以从stdin中获取输入
选项
-b:忽略每行前面开始出的空格字符;
-c:检查文件是否已经按照顺序排序;
-d:排序时,处理英文字母、数字及空格字符外,忽略其他的字符;
-f:排序时,将小写字母视为大写字母;
-i:排序时,除了040至176之间的ASCII字符外,忽略其他的字符;
-m:将几个排序号的文件进行合并;
-M:将前面3个字母依照月份的缩写进行排序;
-n:依照数值的大小排序;
-o<输出文件>:将排序后的结果存入制定的文件;
-r:以相反的顺序来排序;
-t<分隔字符>:指定排序时所用的栏位分隔字符;
+<起始栏位>-<结束栏位>:以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位。
实例
sort将文件/文本的每一行作为一个单位,相互比较,比较原则是从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出。
[root@mail text]# cat sort.txt
aaa:10:1.1
ccc:30:3.3
ddd:40:4.4
bbb:20:2.2
eee:50:5.5
eee:50:5.5
[root@mail text]# sort sort.txt
aaa:10:1.1
bbb:20:2.2
ccc:30:3.3
ddd:40:4.4
eee:50:5.5
eee:50:5.5
忽略相同行使用-u选项或者uniq:
[root@mail text]# cat sort.txt
aaa:10:1.1
ccc:30:3.3
ddd:40:4.4
bbb:20:2.2
eee:50:5.5
eee:50:5.5
[root@mail text]# sort -u sort.txt
aaa:10:1.1
bbb:20:2.2
ccc:30:3.3
ddd:40:4.4
eee:50:5.5
或者
[root@mail text]# uniq sort.txt
aaa:10:1.1
ccc:30:3.3
ddd:40:4.4
bbb:20:2.2
eee:50:5.5
sort的-n、-r、-k、-t选项的使用:
[root@mail text]# cat sort.txt
AAA:BB:CC
aaa:30:1.6
ccc:50:3.3
ddd:20:4.2
bbb:10:2.5
eee:40:5.4
eee:60:5.1
#将BB列按照数字从小到大顺序排列:
[root@mail text]# sort -nk 2 -t: sort.txt
AAA:BB:CC
bbb:10:2.5
ddd:20:4.2
aaa:30:1.6
eee:40:5.4
ccc:50:3.3
eee:60:5.1
#将CC列数字从大到小顺序排列:
[root@mail text]# sort -nrk 3 -t: sort.txt
eee:40:5.4
eee:60:5.1
ddd:20:4.2
ccc:50:3.3
bbb:10:2.5
aaa:30:1.6
AAA:BB:CC
# -n是按照数字大小排序,-r是以相反顺序,-k是指定需要爱排序的栏位,-t指定栏位分隔符为冒号
-k选项的具体语法格式:
-k选项的语法格式:
FStart.CStart Modifie,FEnd.CEnd Modifier
——-Start——–,——-End——–
FStart.CStart 选项 , FEnd.CEnd 选项
这个语法格式可以被其中的逗号,分为两大部分,Start部分和End部分。Start部分也由三部分组成,其中的Modifier部分就是我们之前说过的类似n和r的选项部分。我们重点说说Start部分的FStart和C.Start。C.Start也是可以省略的,省略的话就表示从本域的开头部分开始。FStart.CStart,其中FStart就是表示使用的域,而CStart则表示在FStart域中从第几个字符开始算“排序首字符”。同理,在End部分中,你可以设定FEnd.CEnd,如果你省略.CEnd,则表示结尾到“域尾”,即本域的最后一个字符。或者,如果你将CEnd设定为0(零),也是表示结尾到“域尾”。
从公司英文名称的第二个字母开始进行排序:
$ sort -t ‘ ‘ -k 1.2 facebook.txt
baidu 100 5000
sohu 100 4500
google 110 5000
guge 50 3000
使用了-k 1.2,表示对第一个域的第二个字符开始到本域的最后一个字符为止的字符串进行排序。你会发现baidu因为第二个字母是a而名列榜首。sohu和 google第二个字符都是o,但sohu的h在google的o前面,所以两者分别排在第二和第三。guge只能屈居第四了。
只针对公司英文名称的第二个字母进行排序,如果相同的按照员工工资进行降序排序:
$ sort -t ‘ ‘ -k 1.2,1.2 -nrk 3,3 facebook.txt
baidu 100 5000
google 110 5000
sohu 100 4500
guge 50 3000
由于只对第二个字母进行排序,所以我们使用了-k 1.2,1.2的表示方式,表示我们“只”对第二个字母进行排序。(如果你问“我使用-k 1.2怎么不行?”,当然不行,因为你省略了End部分,这就意味着你将对从第二个字母起到本域最后一个字符为止的字符串进行排序)。对于员工工资进行排 序,我们也使用了-k 3,3,这是最准确的表述,表示我们“只”对本域进行排序,因为如果你省略了后面的3,就变成了我们“对第3个域开始到最后一个域位置的内容进行排序” 了
Uniq 命令用于报告或忽略文件中的重复行,一般与sort命令结合使用。
选项
-c或——count:在每列旁边显示该行重复出现的次数;
-d或–repeated:仅显示重复出现的行列;
-f<栏位>或–skip-fields=<栏位>:忽略比较指定的栏位;
-s<字符位置>或–skip-chars=<字符位置>:忽略比较指定的字符;
-u或——unique:仅显示出一次的行列;
-w<字符位置>或–check-chars=<字符位置>:指定要比较的字符。
实例
删除重复行:
uniq file.txt
sort file.txt | uniq
sort -u file.txt
只显示单一行:
uniq -u file.txt
sort file.txt | uniq -u
统计各行在文件中出现的次数:
sort file.txt | uniq -c
在文件中找出重复的行:
sort file.txt | uniq –d
diff 命令在最简单的情况下,比较给定的两个文件的不同。如果使用“-”代替“文件”参数,则要比较的内容将来自标准输入。diff命令是以逐行的方式,比较文本文件的异同处。如果该命令指定进行目录的比较,则将会比较该目录中具有相同文件名的文件,而不会对其子目录文件进行任何比较操作。
选项
-<行数>:指定要显示多少行的文本。此参数必须与-c或-u参数一并使用;
-a或——text:diff预设只会逐行比较文本文件;
-b或–ignore-space-change:不检查空格字符的不同;
-B或–ignore-blank-lines:不检查空白行;
-c:显示全部内容,并标出不同之处;
-C<行数>或–context<行数>:与执行“-c-<行数>”指令相同;
-d或——minimal:使用不同的演算法,以小的单位来做比较;
-D<巨集名称>或ifdef<巨集名称>:此参数的输出格式可用于前置处理器巨集;
-e或——ed:此参数的输出格式可用于ed的script文件;
-f或-forward-ed:输出的格式类似ed的script文件,但按照原来文件的顺序来显示不同处;
-H或–speed-large-files:比较大文件时,可加快速度;
-l<字符或字符串>或–ignore-matching-lines<字符或字符串>:若两个文件在某几行有所不同,而之际航同时都包含了选项中指定的字符或字符串,则不显示这两个文件的差异;
-i或–ignore-case:不检查大小写的不同;
-l或——paginate:将结果交由pr程序来分页;
-n或——rcs:将比较结果以RCS的格式来显示;
-N或–new-file:在比较目录时,若文件A仅出现在某个目录中,预设会显示:Only in目录,文件A 若使用-N参数,则diff会将文件A 与一个空白的文件比较;
-p:若比较的文件为C语言的程序码文件时,显示差异所在的函数名称;
-P或–unidirectional-new-file:与-N类似,但只有当第二个目录包含了第一个目录所没有的文件时,才会将这个文件与空白的文件做比较;
-q或–brief:仅显示有无差异,不显示详细的信息;
-r或——recursive:比较子目录中的文件;
-s或–report-identical-files:若没有发现任何差异,仍然显示信息;
-S<文件>或–starting-file<文件>:在比较目录时,从指定的文件开始比较;
-t或–expand-tabs:在输出时,将tab字符展开;
-T或–initial-tab:在每行前面加上tab字符以便对齐;
-u,-U<列数>或–unified=<列数>:以合并的方式来显示文件内容的不同;
-v或——version:显示版本信息;
-w或–ignore-all-space:忽略全部的空格字符;
-W<宽度>或–width<宽度>:在使用-y参数时,指定栏宽;
-x<文件名或目录>或–exclude<文件名或目录>:不比较选项中所指定的文件或目录;
-X<文件>或–exclude-from<文件>;您可以将文件或目录类型存成文本文件,然后在=<文件>中指定此文本文件;
-y或–side-by-side:以并列的方式显示文件的异同之处;
–help:显示帮助;
–left-column:在使用-y参数时,若两个文件某一行内容相同,则仅在左侧的栏位显示该行内容;
–suppress-common-lines:在使用-y参数时,仅显示不同之处。
实例
将目录/usr/li下的文件”test.txt”与当前目录下的文件”test.txt”进行比较,输入如下命令:
diff /usr/li test.txt #使用diff指令对文件进行比较
上面的命令执行后,会将比较后的不同之处以指定的形式列出,如下所示:
n1 a n3,n4
n1,n2 d n3
n1,n2 c n3,n4
其中,字母”a”、”d”、”c”分别表示添加、删除及修改操作。而”n1″、”n2″表示在文件1中的行号,”n3″、”n4″表示在文件2中的行号。
注意:以上说明指定了两个文件中不同处的行号及其相应的操作。在输出形式中,每一行后面将跟随受到影响的若干行。其中,以<开始的行属于文件1,以>开始的行属于文件。
Patch 命令被用于为开放源代码软件安装补丁程序。让用户利用设置修补文件的方式,修改,更新原始文件。如果一次仅修改一个文件,可直接在命令列中下达指令依序执行。如果配合修补文件的方式则能一次修补大批文件,这也是Linux系统核心的升级方法之一。
选项
-b或–backup:备份每一个原始文件;
-B<备份字首字符串>或–prefix=<备份字首字符串>:设置文件备份时,附加在文件名称前面的字首字符串,该字符串可以是路径名称;
-c或–context:把修补数据解译成关联性的差异;
-d<工作目录>或–directory=<工作目录>:设置工作目录;
-D<标示符号>或–ifdef=<标示符号>:用指定的符号把改变的地方标示出来;
-e或–ed:把修补数据解译成ed指令可用的叙述文件;
-E或–remove-empty-files:若修补过后输出的文件其内容是一片空白,则移除该文件;
-f或–force:此参数的效果和指定”-t”参数类似,但会假设修补数据的版本为新版本;
-F<监别列数>或–fuzz<监别列数>:设置监别列数的最大值;
-g<控制数值>或–get=<控制数值>:设置以RSC或SCCS控制修补作业;
-i<修补文件>或–input=<修补文件>:读取指定的修补问家你;
-l或–ignore-whitespace:忽略修补数据与输入数据的跳格,空格字符;
-n或–normal:把修补数据解译成一般性的差异;
-N或–forward:忽略修补的数据较原始文件的版本更旧,或该版本的修补数据已使 用过;
-o<输出文件>或–output=<输出文件>:设置输出文件的名称,修补过的文件会以该名称存放;
-p<剥离层级>或–strip=<剥离层级>:设置欲剥离几层路径名称;
-f<拒绝文件>或–reject-file=<拒绝文件>:设置保存拒绝修补相关信息的文件名称,预设的文件名称为.rej;
-R或–reverse:假设修补数据是由新旧文件交换位置而产生;
-s或–quiet或–silent:不显示指令执行过程,除非发生错误;
-t或–batch:自动略过错误,不询问任何问题;
-T或–set-time:此参数的效果和指定”-Z”参数类似,但以本地时间为主;
-u或–unified:把修补数据解译成一致化的差异;
-v或–version:显示版本信息;
-V<备份方式>或–version-control=<备份方式>:用”-b”参数备份目标文件后,备份文件的字尾会被加上一个备份字符串,这个字符串不仅可用”-z”参数变更,当使用”-V”参数指定不同备份方式时,也会产生不同字尾的备份字符串;
-Y<备份字首字符串>或–basename-prefix=–<备份字首字符串>:设置文件备份时,附加在文件基本名称开头的字首字符串;
-z<备份字尾字符串>或–suffix=<备份字尾字符串>:此参数的效果和指定”-B”参数类似,差别在于修补作业使用的路径与文件名若为src/linux/fs/super.c,加上”backup/”字符串后,文件super.c会备份于/src/linux/fs/backup目录里;
-Z或–set-utc:把修补过的文件更改,存取时间设为UTC;
–backup-if-mismatch:在修补数据不完全吻合,且没有刻意指定要备份文件时,才备份文件;
–binary:以二进制模式读写数据,而不通过标准输出设备;
–help:在线帮助;
–nobackup-if-mismatch:在修补数据不完全吻合,且没有刻意指定要备份文件时,不要备份文件;
–verbose:详细显示指令的执行过程。
Linux中文本处理三剑客
grep:文本过滤(模式:pattern)工具
grep, egrep, fgrep(不支持正则表达式搜索)
sed:stream editor,文本编辑工具
awk:Linux上的实现gawk,文本报告生成器
grep 全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
选项
-a 不要忽略二进制数据。
-A<显示列数> 除了显示符合范本样式的那一行之外,并显示该行之后的内容。
-b 在显示符合范本样式的那一行之外,并显示该行之前的内容。
-c 计算符合范本样式的列数。
-C<显示列数>或-<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。
-d<进行动作> 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep命令将回报信息并停止动作。
-e<范本样式> 指定字符串作为查找文件内容的范本样式。
-E 将范本样式为延伸的普通表示法来使用,意味着使用能使用扩展正则表达式。
-f<范本文件> 指定范本文件,其内容有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每一列的范本样式。
-F 将范本样式视为固定字符串的列表。
-G 将范本样式视为普通的表示法来使用。
-h 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。
-H 在显示符合范本样式的那一列之前,标示该列的文件名称。
-i 忽略字符大小写的差别。
-l 列出文件内容符合指定的范本样式的文件名称。
-L 列出文件内容不符合指定的范本样式的文件名称。
-n 在显示符合范本样式的那一列之前,标示出该列的编号。
-q 不显示任何信息。
-R/-r 此参数的效果和指定“-d recurse”参数相同。
-s 不显示错误信息。
-v 反转查找。
-w 只显示全字符合的列。
-x 只显示全列符合的列。
-y 此参数效果跟“-i”相同。
-o 只输出文件中匹配到的部分。
实例
文件中搜索一个单词,命令会返回一个包含“match_pattern”的文本行:
grep match_pattern file_name
grep “match_pattern” file_name
在多个文件中查找:
grep “match_pattern” file_1 file_2 file_3 …
输出除之外的所有行 -v 选项:
grep -v “match_pattern” file_name
标记匹配颜色 –color=auto 选项:
grep “match_pattern” file_name –color=auto
使用正则表达式 -E 选项:
grep -E “[1-9]+”
或
egrep “[1-9]+”
只输出文件中匹配到的部分 -o 选项:
echo this is a test line. | grep -o -E “[a-z]+\.”
line.
echo this is a test line. | egrep -o “[a-z]+\.”
line.
统计文件或者文本中包含匹配字符串的行数 -c 选项:
grep -c “text” file_name
输出包含匹配字符串的行数 -n 选项:
grep “text” -n file_name
或
cat file_name | grep “text” -n
#多个文件
grep “text” -n file_1 file_2
打印样式匹配所位于的字符或字节偏移:
echo gun is not unix | grep -b -o “not”
7:not
#一行中字符串的字符便宜是从该行的第一个字符开始计算,起始值为0。选项 -b -o 一般总是配合使用。
搜索多个文件并查找匹配文本在哪些文件中:
grep -l “text” file1 file2 file3…
grep递归搜索文件
在多级目录中对文本进行递归搜索:
grep “text” . -r -n
# .表示当前目录。
忽略匹配样式中的字符大小写:
echo “hello world” | grep -i “HELLO”
hello
选项 -e 制动多个匹配样式:
echo this is a text line | grep -e “is” -e “line” -o
is
line
#也可以使用-f选项来匹配多个样式,在样式文件中逐行写出需要匹配的字符。
cat patfile
aaa
bbb
echo aaa bbb ccc ddd eee | grep -f patfile -o
在grep搜索结果中包括或者排除指定文件:
#只在目录中所有的.php和.html文件中递归搜索字符”main()”
grep “main()” . -r –include *.{php,html}
#在搜索结果中排除所有README文件
grep “main()” . -r –exclude “README”
#在搜索结果中排除filelist文件列表里的文件
grep “main()” . -r –exclude-from filelist
使用0值字节后缀的grep与xargs:
#测试文件:
echo “aaa” > file1
echo “bbb” > file2
echo “aaa” > file3
grep “aaa” file* -lZ | xargs -0 rm
#执行后会删除file1和file3,grep输出用-Z选项来指定以0值字节作为终结符文件名(\0),xargs
-0 读取输入并用0值字节终结符分隔文件名,然后删除匹配文件,-Z通常和-l结合使用。grep静默输出:
grep -q “test” filename
#不会输出任何信息,如果命令运行成功返回0,失败则返回非0值。一般用于条件测试。
打印出匹配文本之前或者之后的行:
#显示匹配某个结果之后的3行,使用 -A 选项:
seq 10 | grep “5” -A 3
5
6
7
8
#显示匹配某个结果之前的3行,使用 -B 选项:
seq 10 | grep “5” -B 3
2
3
4
5
#显示匹配某个结果的前三行和后三行,使用 -C 选项:
seq 10 | grep “5” -C 3
2
3
4
5
6
7
8
#如果匹配结果有多个,会用“–”作为各匹配结果之间的分隔符:
echo -e “a\nb\nc\na\nb\nc” | grep a -A 1
a
b
—
a
b
基本正则表达式元字符
字符匹配:
. 匹配任意单个字符
[] 匹配指定范围内的任意单个字符
[^] 匹配指定范围外的任意单个字符
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] 小写字母
[:upper:] 大写字母
[:blank:] 空白字符(空格和制表符)
[:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广)
[:cntrl:] 不可打印的控制字符(退格、删除、警铃…)
[:digit:] 十进制数字 [:xdigit:]十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
正则表达式
匹配次数:用在要指定次数的字符后面,用于指定前面的字符要出现的次数
* 匹配前面的字符任意次,包括0次
贪婪模式:尽可能长的匹配
.* 任意长度的任意字符
\? 匹配其前面的字符0或1次
\+ 匹配其前面的字符至少1次
\{n\} 匹配前面的字符n次
\{m,n\} 匹配前面的字符至少m次,至多n次
\{,n\} 匹配前面的字符至多n次
\{n,\} 匹配前面的字符至少n次
正则表达式
位置锚定:定位出现的位置
^ 行首锚定,用于模式的最左侧
$ 行尾锚定,用于模式的最右侧
^PATTERN$ 用于模式匹配整行
^$ 空行
^[[:space:]]*$ 空白行
\< 或 \b 词首锚定,用于单词模式的左侧
\> 或 \b 词尾锚定;用于单词模式的右侧
\<PATTERN\> 匹配整个单词
正则表达式
分组:\(\) 将一个或多个字符捆绑在一起,当作一个整体进行处理,如: \(root\)\+
分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这 些变量的命名方式为: \1, \2, \3, …
\1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符
示例: \(string1\+\(string2\)*\)
\1 :string1\+\(string2\)*
\2 :string2
后向引用:引用前面的分组括号中的模式所匹配字符,而非模式本身
或者:\|
示例:a\|b: a或b C\|cat: C或cat \(C\|c\)at:Cat或cat
Vim 文本编辑器
击键行为是依赖于vim 的“模式”
三种主要模式:
命令(Normal)模式:默认模式,移动光标,剪切/粘贴文本
插入(Insert)或编辑模式: 修改文本 扩展命令(extended command )模式: 保存,退出等
Esc键 退出当前模式
Esc键 Esc键 总是返回到命令模式
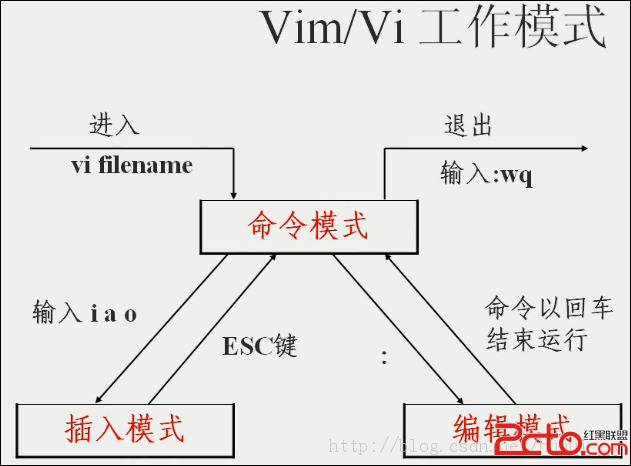
vim键盘图
本文来自投稿,不代表Linux运维部落立场,如若转载,请注明出处:http://www.178linux.com/95547

