

1、 通配符
通配符是shell在做PathnameExpansion时用到的。说白了一般只用于文件名匹配,它是由shell解析的,比如find,ls,cp,mv等。
1、1 Shell常见通配符:
|
通配符 |
含义 |
实例 |
|
* |
匹配 0 或多个字符 |
a*b a与b之间可以有任意长度的任意字符, 也可以一个也没有, 如aabcb, axyzb, a012b, ab。 |
|
? |
匹配任意一个字符 |
a?b a与b之间必须也只能有一个字符, 可以是任意字符, 如aab, abb, acb, a0b。 |
|
[list] |
匹配 list 中的任意单一字符 |
a[xyz]b a与b之间必须也只能有一个字符, 但只能是 x 或 y 或 z, 如: axb, ayb, azb。 |
|
[!list]或[^list] |
匹配 除list 中的任意单一字符 |
a[!0-9]b a与b之间必须也只能有一个字符, 但不能是阿拉伯数字, 如axb, aab, a-b。 |
|
[c1-c2] |
匹配 c1-c2 中的任意单一字符 如:[0-9] [a-z] |
a[0-9]b 0与9之间必须也只能有一个字符 如a0b, a1b… a9b。 |
|
[!c1-c2]或[^c1-c2] |
匹配不在c1-c2的任意字符 |
a[!0-9]b 如acb adb |
|
{string1,string2,…} |
匹配 sring1 或 string2 (或更多)其一字符串 |
a{abc,xyz,123}b 列出aabcb,axyzb,a123b |
1、2 shell Meta字符(元字符)
shell 除了有通配符之外,还有一系列自己的其他特殊字符。
|
字符 |
说明 |
|
IFS |
由 <space> 或 <tab> 或 <enter> 三者之一组成(我们常用 space ) |
|
CR |
由 <enter> 产生 |
|
= |
设定变量 |
|
$ |
取变量值或取运算值 |
|
> |
重定向 stdout |
|
< |
重定向 stdin |
|
| |
管道符号 |
|
& |
重导向 file descriptor ,或将命令置于背景执行 |
|
( ) |
将其内的命令置于 nested subshell 执行,或用于运算或命令替换 |
|
{ } |
将其内的命令置于 non-named function 中执行,或用在变量替换的界定范围 |
|
; |
在前一个命令结束时,而忽略其返回值,继续执行下一个命令 |
|
&& |
在前一个命令结束时,若返回值为 true,继续执行下一个命令 |
|
|| |
在前一个命令结束时,若返回值为 false,继续执行下一个命令 |
|
! |
运算意义上的非(not)的意思 |
|
# |
注释,常用在脚本中 |
|
\ |
转移字符,去除其后紧跟的元字符或通配符的特殊意义 |
1、3 转义字符
有时候,我们想让 通配符,或者元字符 变成普通字符,不需要使用它。那么这里我们就需要用到转义符了。 shell提供转义符有三种。
|
字符 |
说明 |
|
‘’(单引号) |
硬转义,其内部所有的shell 元字符、通配符都会被关掉。 |
|
“”(双引号) |
软转义,其内部只允许出现特定的shell 元字符:$用于参数替换 `(反单引号,esc键下面)用于命令替换 |
|
\(反斜杠) |
又叫转义,去除其后紧跟的元字符或通配符的特殊意义 |
举例:

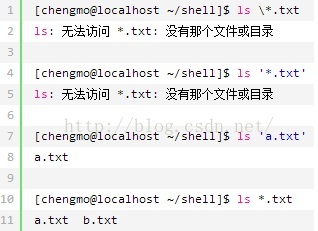
2、正则表达式
正则表达式是用来匹配字符串的,针对文件内容的文本过滤工具里,大都用到正则表达式,如vi,grep,awk,sed等。
另外,这篇文章只针对Linux下的文本过滤工具的正则表达式进行讨论,其他的一些编程语言,如C++(c regex,c++ regex,boost regex),java,python等都有自己的正则表达式库。
简单点来说,正则表达式是对一组正在处理的文本的描述。
例1:查找文件test中出现单词hi,并且若干字符后出现单词Jerry的行
$ grep -E”\<hi\>.+\<Jerry\>” test
ni hao hi nihao Jerrydsfds
例2:查找文件test中出现以hi开头的单词,并且若干字符后出现以Jerry结尾的单词的行
grep -E “\<hi.+Jerry\>”test
ni hao hi nihao Jerrydsfds
wo buhao hiwuyanpingjfkjk Jerry
wo henhao hiwuyanJerry
在正则表达式的使用过程中,一些字符是以特定方式处理的。最常使用的特殊字符如下:
| 字符 | 含义 |
| ^ | 指向一行的开头 |
| $ | 指向一行的结尾 |
| . | 任意单个字符 |
| [] | 字符范围。如[a-z] |
如果想将上述字符用作普通字符,就需要在它们前面加上\字符。例如,如果想使用$字符,你需要将它写为\$
在方括号中还可以使用一些有用的特殊匹配模式,如下:
| 匹配模式 | 含义 |
| [:alnum:] | 字母与数字字符,如grep[[:alnum:]] words.txt |
| [:alpha:] | 字母 |
| [:ascii:] | ASCII字符 |
| [:blank:] | 空格或制表符 |
| [:cntrl:] | ASCII控制字符 |
| [:digit:] | 数字 |
| [:graph:] | 非控制、非空格字符 |
| [:lower:] | 小写字母 |
| [:print:] | 可打印字符 |
| [:punct:] | 标点符号字符 |
| [:space:] | 空白字符,包括垂直制表符 |
| [:upper:] | 大写字母 |
| [:xdigit:] | 十六进制数字 |
另外,如果指定了用于扩展的-E选项,那些用于控制匹配完成的其他字符可能会遵循正则表达式的规则,对于grep命令,我们还需要在这些字符前面加上\,下表是扩展部分一览:
| 选项 | 含义 |
| ? | 最多一次 |
| * | 必须匹配0次或多次 |
| + | 必须匹配1次或多次 |
| {n} | 必须匹配n次 |
| {n,} | 必须匹配n次或以上 |
| {n,m} | 匹配次数在n到m之间,包括边界 |
3、通配符和正则表达式比较
(1)通配符和正则表达式看起来有点像,不能混淆。可以简单的理解为通配符只有*,?,[],{}这4种,而正则表达式复杂多了。
(2)*在通配符和正则表达式中有其不一样的地方,在通配符中*可以匹配任意的0个或多个字符,而在正则表达式中他是重复之前的一个或者多个字符,不能独立使用的。比如通配符可以用*来匹配任意字符,而正则表达式不行,他只匹配任意长度的前面的字符。
4、grep
引自:http://hi.baidu.com/hzslqt/blog/item/dbd0ea4e5145f819b3de05d6.html
1. grep简介
grep (global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。Unix的grep家族包括grep、egrep和fgrep。egrep和fgrep的命令只跟grep有很小不同。egrep是grep的扩展,支持更多的re元字符, fgrep就是fixed grep或fast grep,它们把所有的字母都看作单词,也就是说,正则表达式中的元字符表示回其自身的字面意义,不再特殊。linux使用GNU版本的grep。它功能更强,可以通过–G、–E、–F命令行选项来使用egrep和fgrep的功能。
grep的工作方式是这样的,它在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。搜索的结果被送到屏幕,不影响原文件内容。
grep可用于shell脚本,因为grep通过返回一个状态值来说明搜索的状态,如果模板搜索成功,则返回0,如果搜索不成功,则返回1,如果搜索的文件不存在,则返回2。我们利用这些返回值就可进行一些自动化的文本处理工作。
2. grep正则表达式元字符集(基本集)
^ :锚定行的开始 如:’^grep’匹配所有以grep开头的行。
$ :锚定行的结束 如:’grep$’匹配所有以grep结尾的行。
. :匹配一个非换行符的字符 如:’gr.p’匹配gr后接一个任意字符,然后是p。
* :匹配零个或多个先前字符 如:’*grep’匹配所有一个或多个空格后紧跟grep的行。 .*一起用代表任意字符。
[] :匹配一个指定范围内的字符,如'[Gg]rep’匹配Grep和grep。
[^] :匹配一个不在指定范围内的字符,如:'[^A-FH-Z]rep’匹配不包含A–R和T–Z的一个字母开头,紧跟rep的行。
.. :标记匹配字符,如’love’,love被标记为1。
\< :锚定单词的开始,如:‘\<grep’匹配包含以grep开头的单词的行。
\> :锚定单词的结束,如’grep\>’匹配包含以grep结尾的单词的行。
x\{m\} :重复字符x,m次,如:’o\{5\}’匹配包含5个o的行。
x\{m,\} :重复字符x,至少m次,如:’o\{5,\}’匹配至少有5个o的行。
x\{m,n\} :重复字符x,至少m次,不多于n次,如:’o\{5,10\}’匹配5–10个o的行。
\w :匹配文字和数字字符,也就是[A–Za–z0–9],如:’G\w*p’匹配以G后跟零个或多个文字或数字字符,然后是p。
\W :\w的反置形式,匹配一个或多个非单词字符,如点号句号等。
\b :单词锁定符,如: ‘\bgrepb\’只匹配grep。
3. 用于egrep和 grep –E的元字符扩展集
+ :匹配一个或多个先前的字符。如:'[a-z]+able’,匹配一个或多个小写字母后跟able的串,如loveable,enable,disable等。
? :匹配零个或多个先前的字符。如:’gr?p’匹配gr后跟一个或没有字符,然后是p的行。
a|b|c :匹配a或b或c。如:grep|sed匹配grep或sed
() :分组符号,如:love(able|rs)ov+匹配loveable或lovers,匹配一个或多个ov。
x{m},x{m,},x{m,n} :作用同x\{m\},x\{m,\},x\{m,n\}
5. Grep命令选项
–a或—text 不要忽略二进制的数据。
–A <显示列数>或—after–context=<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之后的内容。
–b或—byte–offset 在显示符合范本样式的那一列之前,标示出该列第一个字符的位编号。
–B<显示列数>或—before–context=<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之前的内容。
–c或—count 计算符合范本样式的列数。
–C<显示列数>或—context=<显示列数>或-<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。
–d<进行动作>或—directories=<进行动作> 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
–e<范本样式>或—regexp=<范本样式> 指定字符串做为查找文件内容的范本样式。
–E或—extended–regexp 将范本样式为延伸的普通表示法来使用。
–f<范本文件>或—file=<范本文件> 指定范本文件,其内容含有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每列一个范本样式。
–F或—fixed–regexp 将范本样式视为固定字符串的列表。
–G或—basic–regexp 将范本样式视为普通的表示法来使用。
–h或—no–filename 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。
–H或–with-filename 在显示符合范本样式的那一列之前,表示该列所属的文件名称。
–i或—ignore–case 忽略字符大小写的差别。
–l或—file-with-matches 列出文件内容符合指定的范本样式的文件名称。
–L或—files–without–match 列出文件内容不符合指定的范本样式的文件名称。
–n或—line–number 在显示符合范本样式的那一列之前,标示出该列的列数编号。
–q或—quiet或—silent 不显示任何信息。
–r或—recursive 此参数的效果和指定“–d recurse”参数相同。
–s或—no–messages 不显示错误信息。
–v或—revert–match 反转查找。
–V或—version 显示版本信息。
–w或—word–regexp 只显示全字符合的列。
–x或—line–regexp 只显示全列符合的列。
–y 此参数的效果和指定“–i”参数相同。
—help 在线帮助。
6. 实例
要用好grep这个工具,其实就是要写好正则表达式,下面列几个例子,讲解正则表达式的写法。
$ ls –l | grep ‘^a’
通过管道过滤ls –l输出的内容,只显示以a开头的行。
$ grep ‘test’ d*
显示所有以d开头的文件中包含test的行。
$ grep ‘test’ aa bb cc
显示在aa,bb,cc文件中匹配test的行。
$ grep ‘[a-z]\{5\}’ aa
显示所有包含每个字符串至少有5个连续小写字符的字符串的行。
$ grep ‘west.*\1’ aa
如果west被匹配,则es就被存储到内存中,并标记为1,然后搜索任意个字符(.*),这些字符后面紧跟着另外一个es(\1),找到就显示该行。如果用egrep或grep –E,就不用”\”号进行转义,直接写成’w(es)t.*\1’就可以了。
再讲解一个具体应用的例子。
查询所有位于当前目录下的.cs文件中的Main,通过grep,可以轻松快速地完成这项任务,命令如下:
grep ‘Main’ *.cs
输出结果为:
ChineseDemo.cs: publicstatic void Main()
RegDemo1.cs: static voidMain(string[] args)
RegDemo2.cs: public static void Main()
RegDemo3.cs: publicstatic void Main()
可见,通过grep真的可以找到相关目录中符合条件的所有文件,并能打印出查询到的字符串所位于的那行内容。如果只想确定哪些文件含有Main,而不需打印相应行的内容,那么可以使用以下命令:?
grep –l‘Main’ *.cs
输出结果为:
ChineseDemo.cs
RegDemo1.cs
RegDemo2.cs
RegDemo3.cs
只有相应的文件名称被显示。
在找到了含有Main字符串的几个文件后,如果想粗略地查看某一具体文件的里源代码的相关信息,比如查看RegDemo1.cs文件中含有Main这一行的前后三行,相关的命令如下:
grep –C 3 ‘Main’ RegDemo1.cs
输出结果为:
class GroupingApp
{
static void Main(string[] args)
{
Reg7();
}
输出结果完全符合需求,static void Main(string[] args)这一行前后三行范围内的所有代码被全部打印出来(第一行是空行)。
以上的查询字符串没有对查找结果是否为一个完整的单词进行限制,也就是说TheMain和Main_Func都会被认定为查询目标。如果想限定该查询字符串为一个完整单词,那么可以使用\w参数,相关命令如下:
grep –w‘Main’ *.cs
结果为:
ChineseDemo.cs: publicstatic void Main()
RegDemo1.cs: static voidMain(string[] args)
RegDemo2.cs: publicstatic void Main()
RegDemo3.cs: publicstatic void Main()
另外举例如下:
1)显示/etc/passwd中的一位数或两位数(锚定词首、记尾、分组、转义、次数匹配)
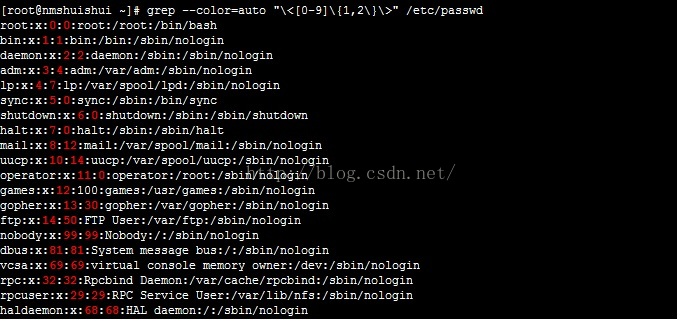
2)找出当前系统上用户名和默认shell相同的用户(行首、行尾锚定)(开始单词和结束单词一样)

3)grep配合其它命令的用法,找出本机的IP地址,只显示IP段(管道、cut)
[root@nmshuishui ~]# ifconfig eth0 | grep “inet addr:” | cut -d:-f2 | cut -d’ ‘ -f1
192.168.1.102
参考:
1、http://www.cnblogs.com/chengmo/archive/2010/10/17/1853344.html
2、http://blog.csdn.net/huiguixian/article/details/6284834
3、http://blog.csdn.net/wealoong/article/details/8015576
摘抄自:https://blog.csdn.net/swjtuwyp/article/details/51817472
本文来自投稿,不代表Linux运维部落立场,如若转载,请注明出处:http://www.178linux.com/96491
