

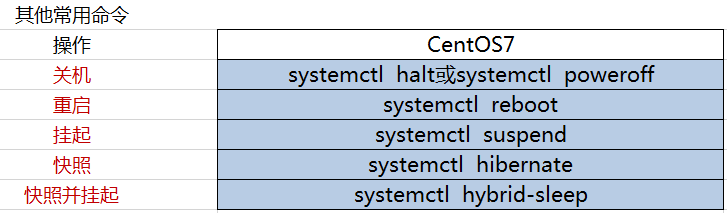
一、简述systemd的新特性及unit常见类型分析,能够实现编译安装的如nginx\apache实现通过systemd来管理。
1、Systemd的新特性:
- 系统引导时实现服务并行启动;
- 按需激活进程;
- 系统状态快照;
- 基于依赖关系定义服务控制逻辑;
- 支持快照和系统恢复;
- 维护挂载点和自动挂载点;
2、核心概念:unit
- unit由其相关配置文件进行标识、识别和配置;文件中主要包含了系统服务、监听的socket、保存的快照以及其它与init相关的信息;
- 这些配置文件主要保存在以下目录中:
/usr/lib/systemd/system
/run/systemd/system
/etc/systemd/system
3、unit的常见类型:

- Service unit:文件扩展名为.service,用于定义系统服务;
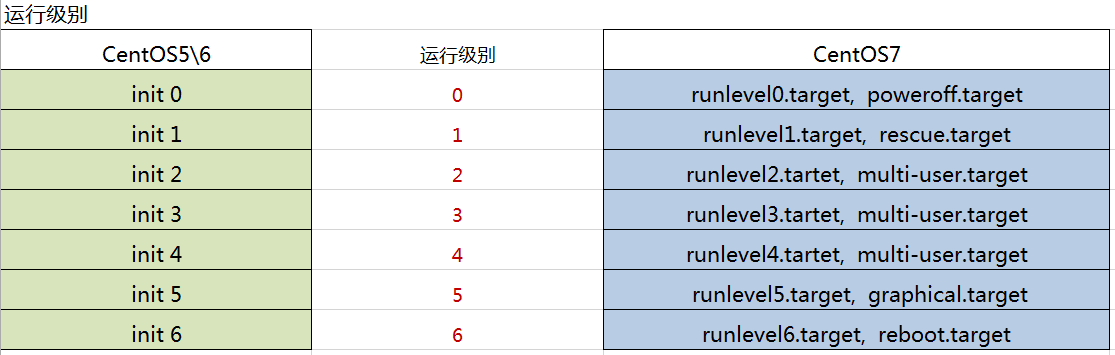
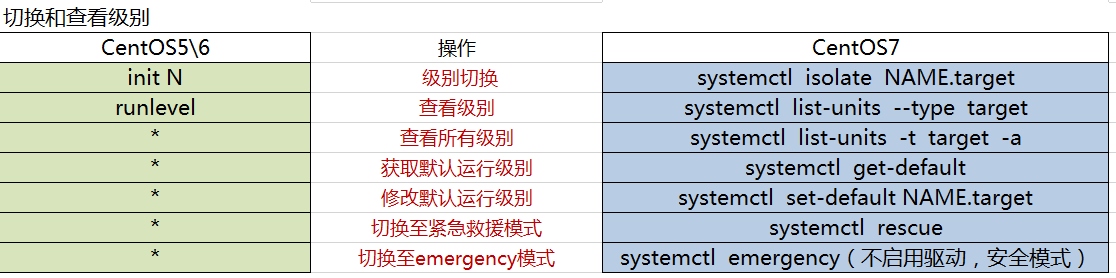
- Target unit:文件扩展为.target,用于模拟实现“运行级别”;(centos7 实际上是没有运行级别的默认都是不启动的)
- Device unit:后缀名为.device,用于定义内核识别的设备;
- Mount unit:后缀名为.mount,定义文件系统挂载点;
- Socket unit:后缀名为.socket,用于标识进程间通信用到的socket文件;
- Snapshot unit:后缀名为 .snapshot,管理系统快照;
- Swap unit:后缀名为.swap, 用于标识swap设备;
- Automount unit:后缀名为.automount,文件系统自动点设备;
- Path unit:后缀名为.path, 用于定义文件系统中的一文件或目录;
4、关键特性:
- 基于socket的激活机制:socket与程序分离,将套接字先分配但时程序本身未启动
- 基于bus的激活机制:基于总线的请求来激活设备
- 基于device的激活机制:设备插入时候自动挂载激活设备,挂载点不存在自动创建
- 基于Path的激活机制:监控目录文件是否存在来激活服务或者进程
- 系统快照:保存各unit的当前状态信息于持久存储设备中;
- 向后兼容sysv init脚本; /etc/init.d/下的脚本也能兼容
注意:也存在不兼容情况:
1)systemctl的命令是固定不变的;
2)非由systemd启动的服务,systemctl无法与之通信;
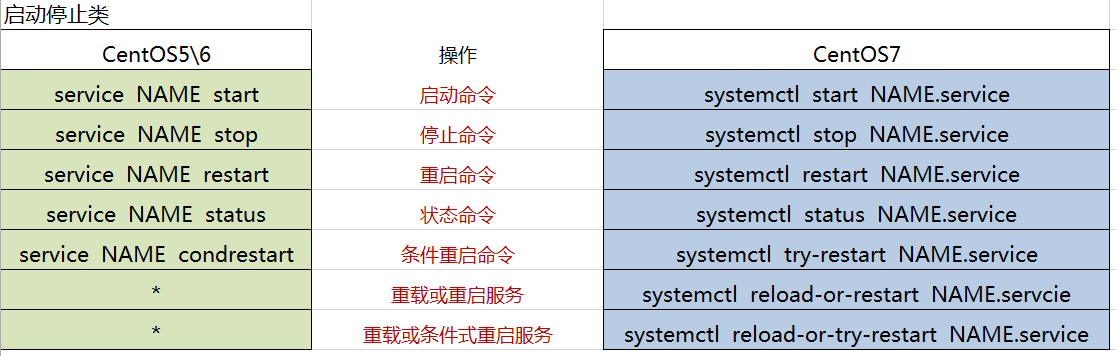
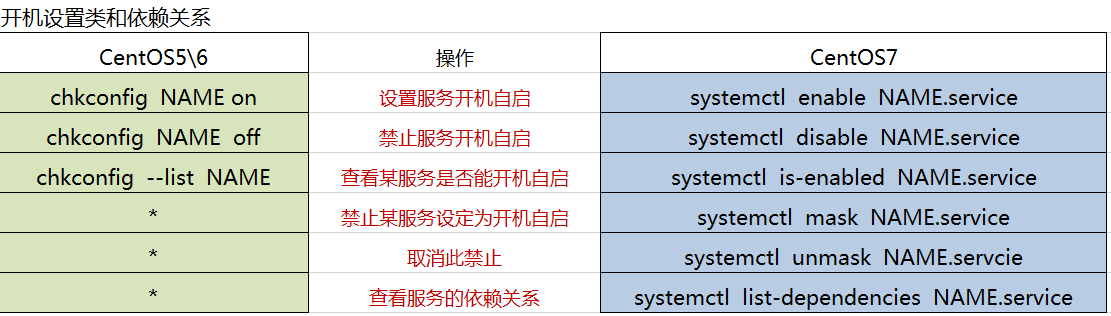
5、管理系统服务:
CentOS 7: service类型的unit文件;
- syscemctl命令:控制systemd系统和服务管理
- 格式:systemctl [OPTIONS…] COMMAND [NAME…]

6、服务单元模块
文件通常由三部分组成:
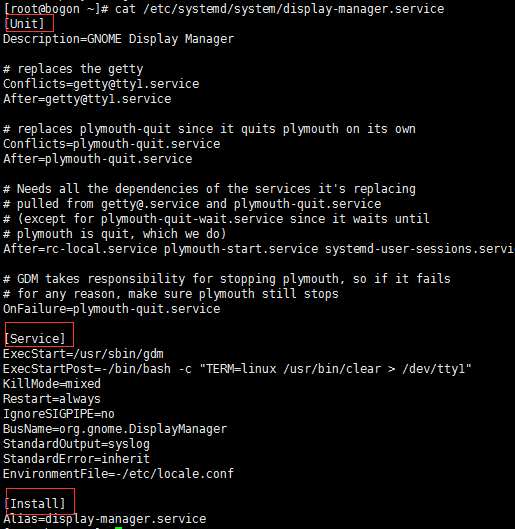
(1)[Unit]:定义与Unit类型无关的通用选项;用于提供unit的描述信息、unit行为及依赖关系等;
Unit段的常用选项:
- Description:描述信息;意义性描述;
- After:定义unit的启动次序;表示当前unit应该晚于哪些unit启动;其功能与Before相反;
- Requies:依赖到的其它units;强依赖,被依赖的units无法激活时,当前unit即无法激活;
- Wants:依赖到的其它units;弱依赖
- Conflicts:定义units间的冲突关系;
(2) [Service]:与特定类型相关的专用选项;此处为Service类型;
Service段的常用选项:
- Type:用于定义影响ExecStart及相关参数的功能的unit进程启动类型;
- 类型种类:
- simple:默认。由ExecStart指明的进程所启动起来进程为主进程
- forking:由ExecStart所启动的进程生成的一个子进程为主,父进程退出
- oneshot:一次性的启动,后续的unit进程启动后,该进程退出
- dbus:仅在得到dbus之后才推出
- notify:发送通知以后才能运行
- idle:类似于simple
- 类型种类:
- EnvironmentFile:环境配置文件,为ExecStart提供一些变量;
- ExecStart:指明启动unit要运行命令或脚本;ExecStartPre, ExecStartPost
- ExecStop:指明停止unit要运行的命令或脚本;
- Restart:启动此项,意外终止会自动重启脚本
(3) [Install]:定义由“systemctl enable”以及”systemctl disable“命令在实现服务启用或禁用时用到的一些选项;
- Install段的常用选项:
Alias:当前unit的别名
RequiredBy:被哪些units所依赖;
WantedBy:被哪些units所依赖;
(4)注意:对于新创建的unit文件或,修改了的unit文件,要通知systemd重载此配置文件;
- #systemctl daemon-reload
7、源码安装apache实现通过systemd来管理
(1)源码编译安装Apache至少需要apr、apr-util、pcre组件的支持。
源码的安装一般由3个步骤组成:配置(configure)、编译(make)、安装(make install)。
(2)查询是否安装了apache服务器httpd
[root@localhost ]# rpm -qa | grep httpd
httpd-2.4.6-45.el7.centos.x86_64
httpd-tools-2.4.6-45.el7.centos.x86_64
(3)卸载系统自动装的apache服务器httpd
[root@localhost ]# httpd -k stop #停止httpd服务器
[root@localhost ]# yum remove httpd #卸载httpd服务器
(4)下载apr、apr-util、pcre组件和Apache源码
[root@localhost ]# wget http://archive.apache.org/dist/apr/apr-1.6.2.tar.gz #下载apr
[root@localhost ]# wget http://archive.apache.org/dist/apr/apr-util-1.6.0.tar.dz2 #下载apr-util
[root@localhost ]# wget http://archive.apache.org/dist/httpd/httpd-2.4.27.tar.bz2 #下载httpd
[root@localhost ]# wget https://ftp.pcre.org/pub/pcre/pcre-8.41.tar.gz #下载pcre
(5)安装expat-devel和编译环境包
[root@localhost ]# yum install expat-devel #安装expat-deval
[root@localhost ]# yum groupinstall “Development Tools”#安装包含gcc的包组
(6)安装apr组件
[root@localhost ]# tar xvf apr-1.6.2.tar.gz #解压缩 apr
[root@localhost ]# cd apr-1.6.2 #切换目录
[root@localhost apr-1.6.2]# ./configure –prefix=/usr/local/apr #配置安装路径和相关组件路径
[root@localhost apr-1.6.2]# make #编译
[root@localhost apr-1.6.2]# make install #安装
(7)安装apr-util组件
[root@localhost ]# tar xvf apr-util-1.6.0.tar.bz2 #解压缩 apr-util
[root@localhost ]# cd apr-util-1.6.0 #切换目录
[root@localhost apr-util-1.6.0]# ./configure –prefix=/usr/local/apr-util –with-apr=/usr/local/apr #配置安装路径和相关组件路径
[root@localhost apr-util-1.6.0]# make #编译
[root@localhost apr-util-1.6.0]# make install #安装
(8)安装pcre组件
[root@localhost ]# tar xvf pcre-8.41.tar.gz #解压缩 pcre
[root@localhost ]# cd pcre-8.41 #切换目录
[root@localhost pcre-8.41]# ./configure –prefix=/usr/local/pcre #配置安装路径和相关组件路径
[root@localhost pcre-8.41]# make #编译
[root@localhost pcre-8.41]# make install #安装
(9)安装Apache
[root@localhost ]# tar xvf httpd-2.4.27.tar.bz2 #解压缩httpd
[root@localhost ]# cd httpd-2.4.27 #切换目录
[root@localhost httpd-2.4.27]#./configure –prefix=/usr/local/apache –with-apr=/usr/local/apr –with-apr-util=/usr/local/apr-util –with-pcre=/usr/local/pcre #配置安装路径和相关组件路径
[root@localhost httpd-2.4.27]# make #编译
[root@localhost httpd-2.4.27]# make install #安装
(10)配置httpd脚本
[root@localhost ~]# vim /usr/local/apache/conf/httpd.conf #修改httpd.conf
[root@localhost ~]# /usr/local/apache/bin/apachectl start #测试启动httpd
httpd (pid 106576) already running #启动成功
[root@localhost ~]# cd /etc/rc.d/init.d #切换目录
[root@localhost init.d]# ls #查找是否有httpd文件
functions netconsole network README
[root@localhost init.d]# vim httpd #新建编辑httpd文件写入脚本
#!/bin/bash## httpd Startup script for the Apache HTTP Server## chkconfig: – 85 15# description: The Apache HTTP Server is an efficient and extensible \# server implementing the current HTTP standards.if [ -f /etc/sysconfig/httpd ]; then. /etc/sysconfig/httpdfiprog=${HTTPD-/usr/local/apache/bin/httpd}[ -L /usr/sbin/httpd ] || ln -sv $prog /usr/sbinlockfile=${LOCKFILE-/var/lock/subsys/httpd}prog=$(basename $prog)check_prog() {[ -f $lockfile ] && RETVAL=0 || RETVAL=1return $RETVAL}lcc_start() {check_progif [ $RETVAL -eq 0 ]; thenecho “$prog is started.”else#$prog $OPTIONS -DFOREGROUND$prog $OPTIONSif [ $? -eq 0 ]; thentouch $lockfileecho “$prog start ok”elseecho “$prog start fail”fifi}lcc_stop() {check_progif [ $RETVAL -eq 0 ]; thenkill -9 `pgrep $prog` &> /dev/nullrm -f $lockfile[ $? -eq 0 ] && echo “$prog stop finished.” || echo “$prog stop fail.”elseecho “$prog is stopped.”fi}lcc_restart() {lcc_stoplcc_start}lcc_status() {check_prog[ $? -eq 0 ] && echo “$prog is running.” || echo “$prog is stopping”}case “$1“ instart|stop|restart|status)lcc_$1;;*)echo $“Usage: $prog {start|stop|restart|status}”RETVAL=2;;esacexit $RETVAL
二、描述awk命令用法及示例
1、什么是gawk
gawk 是模式扫描和实现处理的语言,主要功能是实现文本格式化输出
2、基本用法:
- 格式:gawk [options] ‘program’ FILE …
- program: PATTERN{ACTION STATEMENTS}
语句之间用分号分隔
print, printf实现文本格式化输出 - 选项:
-F:指明输入时用到的字段分隔符;
-v var=value: 自定义变量;
- program: PATTERN{ACTION STATEMENTS}
3、print
- 格式 print item1, item2, …
示例:
- 要点:
(1) 逗号分隔符;
(2) 输出的各item可以字符串,也可以是数值;当前记录的字段、变量或awk的表达式;
(3) 如省略item,相当于print $0;
4、变量
内建变量
- FS:input field seperator,输入默认为空白字符;
- FS:output field seperator,输出默认为空白字符;
- RS:input record seperator,输入时的换行符;
- ORS:output record seperator,输出时的换行符;
- NF:number of field,每一行的字段数量
{print NF}, {print $NF} - NR:number of record, 行数;
- FNR:各文件分别计数;行数;
- FILENAME:当前文件名;
- ARGC:命令行参数的个数;
- ARGV:数组,保存的是命令行所给定的各参数;
示例:
- (1) -v var=value
变量名区分字符大小写; - (2) 在program中直接定义
6、printf命令
- 格式化输出:printf FORMAT, item1, item2, …
- (1) FORMAT格式符必须给出;
- (2) 不会自动换行,需要显式给出换行控制符,\n
- (3) FORMAT中需要分别为后面的每个item指定一个格式化符号;
- 格式符:
%c: 显示字符的ASCII码;
%d, %i: 显示十进制整数;
%e, %E: 科学计数法数值显示;
%f:显示为浮点数;
%g, %G:以科学计数法或浮点形式显示数值;
%s:显示字符串;
%u:无符号整数;
%%: 显示%自身; - 修饰符:
#[.#]:第一个数字控制显示的宽度;第二个#表示小数点后的精度;
%3.1f
-: 左对齐
+:显示数值的符号 - 示例:
- 算术操作符:x+y, x-y, x*y, x/y, x^y, x%y ,-x,+x: 转换为数值;
- 字符串操作符:没有符号的操作符,字符串连接
- 赋值操作符:=, +=, -=, *=, /=, %=, ^=++, –
- 比较操作符:>, >=, <, <=, !=, ==
- 模式匹配符:
- ~:是否匹配
- !~:是否不匹配
- 逻辑操作符:&&,||,!
示例:判断用户id大于1000的为系统用户:
- (1) empty:空模式,匹配每一行;
- (2) /regular expression/:仅处理能够被此处的模式匹配到的行;
- (3) relational expression: 关系表达式;结果有“真”有“假”;结果为“真”才会被处理;真:结果为非0值,非空字符串;
- (4) line ranges:行范围,
startline,endline:/pat1/,/pat2/
BEGIN{}: 仅在开始处理文件中的文本之前执行一次;
END{}:仅在文本处理完成之后执行一次;
(1)if语句
格式:
- if(condition) {statments}
- if(condition) {statments} else {statements}
- while(conditon) {statments}
- do {statements} while(condition)
- for(expr1;expr2;expr3) {statements}
- break
- continue
- delete array[index]
- delete array
- exit
(2)判断语句 if-else
- 语法:if(condition) statement [else statement]
- 使用场景:对awk取得的整行或某个字段做条件判断;
(3)、 while循环
- 语法:while(condition) statement
条件“真”,进入循环;条件“假”,退出循环; - 使用场景:对一行内的多个字段逐一类似处理时使用;对数组中的各元素逐一处理时使用;
(4)、do-while循环
- 语法:do statement while(condition)
意义:至少执行一次循环体
(5)、 for循环
- 语法:for(expr1;expr2;expr3) statement
- 格式:for(variable assignment;condition;iteration process) {for-body}
- 特殊用法:
能够遍历数组中的元素;
语法:for(var in array) {for-body}
(6) switch语句
- 语法:switch(expression) {case VALUE1 or /REGEXP/: statement; case VALUE2 or /REGEXP2/: statement; …; default: statement}
(7) break和continue
- break [n]:跳出循环
- continue:提前结束本次循环,进入下一次循环
(8) next
- 提前结束对本行的处理而直接进入下一行;
10、array关联数组
- 关联数组:array[index-expression]
- index-expression:
(1) 可使用任意字符串;字符串要使用双引号;
(2) 如果某数组元素事先不存在,在引用时,awk会自动创建此元素,并将其值初始化为“空串”; - 若要判断数组中是否存在某元素,要使用”index in array”格式进行;
- 用法:
- weekdays[mon]=”Monday”
- 若要遍历数组中的每个元素,要使用for循环;
- for(var in array) {for-body}
- 注意:var会遍历array的每个索引;
state[“LISTEN”]++数组state
state[“ESTABLISHED”]++数组establish
示例:统计/etc/fstab文件中每个文件系统类型出现的次数;
示例:统计指定文件中每个单词出现的次数;
三、描述awk函数示例
- 内置函数
- 数值处理:
rand():返回0和1之间一个随机数;
- 数值处理:
- 字符串处理:
- length([s]):返回指定字符串的长度;
- sub(r,s,[t]):以r表示的模式来查找t所表示的字符中的匹配的内容,并将其第一次出现替换为s所表示的内容;
- gsub(r,s,[t]):以r表示的模式来查找t所表示的字符中的匹配的内容,并将其所有出现均替换为s所表示的内容;
- split(s,a[,r]):以r为分隔符切割字符s,并将切割后的结果保存至a所表示的数组中;
示例:
本文来自投稿,不代表Linux运维部落立场,如若转载,请注明出处:http://www.178linux.com/97967

