

一、并发
1、基本概念
并发和并行的区别:
1)并行,parallel
同时做某些事,可以互不干扰的同一时刻做几件事。(解决并发的一种方法)
高速公路多个车道,车辆都在跑。同一时刻。
2)并发 concurrency
同时做某些事,一个时段内有事情要处理。(遇到的问题)
高并发,同一时刻内,有很多事情要处理。
2、并发的解决
1)队列、缓冲区
排队就是把人排成队列,先进先出,解决了资源使用的问题。
排成的队列,其实就是一个缓冲地带,就是缓冲区。
Queue模块的类queue、lifoqueue、priorityqueue。
2)争抢的
会有一个人占据窗口,其他人会继续争抢,可以锁定窗口,窗口不在为其他人服务,这就是锁机制。(锁的概念,排他性锁,非排他性锁)。
3)预处理
一种提前加载用户需要的数据的思路,预处理思想,缓存常用。
4)并行
日常可以通过购买更多的服务器,或者开多线程,实现并行处理,来解决并发问题。
水平扩展思想。
如果在但CPU上处理,就不是并行了。
但是多数服务都是多CPU的,服务的部署就是多机、分布式的,都是并行处理。
(串行比并行快)
5)提速
提高单个CPU性能,或单个服务器安装更多的CPU
这就是一种垂直扩展思想。
6)消息中间件
例如地跌站外的九曲回肠的走廊,缓冲人流。
常见的消息中间件有RabbitMQ,ActiveMQ(Apache)、RocketMQ(Apache)。
3、进程和线程
在实现了线程的操作系统中,线程是操作系统能够进行运算调度的最小单位。他包含在进程中,是进程中的实际运作单位。一个程序执行实例就是一个进程。
进程(process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。
进程和程序的关系
程序是源代码编译后的文件,而这些文件存放在磁盘上。当程序被操作系统加载到内存
中,就是进程,进程中存放着指令和数据(资源),也是线程的容器。
Linux进程有父进程、子进程,Windows的进程是平等关系。
线程,有时被称为轻量级进程,是程序执行流的最小单元,一个标准的线程由线程ID,当前指令指针(pc),寄存器集合和堆栈组成。每个线程有自己独立的栈。
在许多系统中,创建一个线程比创建一个进程快10-100倍。
进程、线程的理解
现代操作系统提出的进程的概念,每一个进程都认为自己是独占所有的计算机硬件资源。
进程就是独立的王国,进程间不可以随便的共享数据。
线程就是省份,同一个进程内的线程可以共享进程的资源,每一个线程拥有自己独立的堆栈。
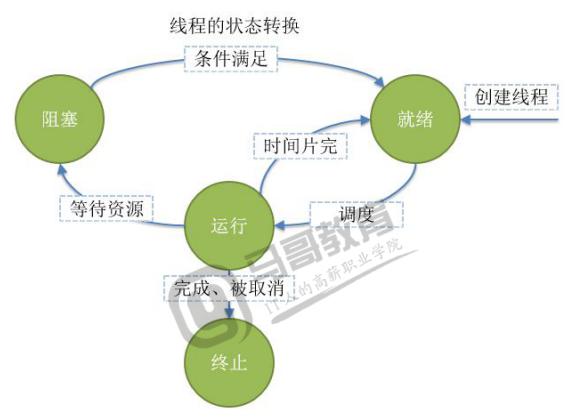
4、线程状态
| 状态 | 含义 |
| 就绪(ready) | 线程能够运行,但在等待被调度,可能线程刚刚创建启动,或刚刚从阻塞恢复,或者被其他线程抢占。 |
| 运行(running) | 线程正在运行 |
| 阻塞(Blocked) | 线程等待外部事件发生而无法运行,如I/O操作。 |
| 终止(Terminated) | 线程完成,或退出,或被取消。 |
5、Python中的线程和进程
进程会启动一个解释器进程,线程会共享一个解释器进程。
1)Python的线程开发
Python的线程开发使用标准库threading
2)Thread类
签名:
def __init__(self, group: None = …,
target: Optional[Callable[…, None]] = …,
name: Optional[str] = …,
args: Iterable = …,
kwargs: Mapping[str, Any] = …,
*, daemon: Optional[bool] = …) -> None: …
| 参数名 | 含义 |
| target | 线程调用对象,就是目标函数 |
| name | 为线程起名字 |
| args | 为目标函数传递实参,元组 |
| Kwargs | 为目标函数关键词传参,字典 |
3)线程启动
import threading
import time
def worker():
print(‘before’)
time.sleep(3)
print(‘finished’)
t = threading.Thread(target=worker) #线程对象
t.start() #启动
通过threading.Thread创建一个线程对象,target是目标函数,name可以指定名称。
需要调用start方法启动函数。
线程之所以执行函数,是因为线程中就是用来执行代码的,所以还是函数调用。
函数执行完毕后,线程也就退出了。
如果想让一个线程一直工作,不让线程退出就要利用到while循环。
import threading
import time
def worker():
count = 0
while True:
count += 1
print(‘before’)
time.sleep(3)
if count >5:
print(‘finished’)
break
t = threading.Thread(target=worker) #线程对象
t.start() #启动
4)线程退出
Python中没有提供终止线程的方法。线程在下面情况下退出。
- 线程函数内语句执行完毕
- 线程函数中抛出未处理的异常。
import threading
import time
def worker():
count = 0
while True:
if count >5:
break
#return
#raise RuntimeError(count)
time.sleep(3)
print(‘before’)
count += 1
print(‘finished’)
t = threading.Thread(target=worker) #线程对象
t.start() #启动
print(‘end’)
线程没有优先级,没有线程组的概念。也不能被销毁、停止、挂起,那么就是没有恢复和中断了。
5)线程的传参
import threading
import time
def add(x,y):
print(‘{}+{}={}’.format(x,y,x+y))
t1 = threading.Thread(target=add,name=’1′,args=(4,5))
t1.start()
time.sleep(2)
t2 = threading.Thread(target=add,name = ‘2’,args=(4,),kwargs={‘y’:6})
t2.start()
time.sleep(2)
t3 = threading.Thread(target=add,name=’3′,kwargs={‘x’:4,’y’:7})
t3.start()
线程中的传参,和函数传参没有什么区别,本质上就是函数传承。
6)threading的属性和方法
| 名称 | 含义 |
| current_thread() | 返回当前主线程 |
| main_thread() | 返回主线程对象 |
| active_count() | 当前处于alive状态的线程个数 |
| enumerate() | 返回所有活着的线程的列表,不包括已经终止的线程和未开始的线程 |
| git_ident() | 返回当前线程的ID,非0整数。 |
active_count、enumerate方法返回的值还包括主线程。
import threading
import time
def showinfo():
print(‘currentthread = {}’.format(threading.current_thread()))
print(‘main thread = {}’.format(threading.main_thread()))
print(‘active count = {}’.format(threading.active_count()))
def worker():
count = 0
showinfo()
while True:
if count>5:
break
time.sleep(5)
count += 1
print(‘finsh’)
t = threading.Thread(target=worker,name=’work’)
showinfo()
t.start()
print(‘end’)
currentthread = <_MainThread(MainThread, started 4048)>
main thread = <_MainThread(MainThread, started 4048)>
active count = 1
currentthread = <Thread(work, started 9084)>
end
main thread = <_MainThread(MainThread, stopped 4048)>
active count = 2
finsh
finsh
finsh
finsh
finsh
Finsh
| 名称 | 含义 |
| Name | 他只是一个名字,只是一个标识符,名字可以重名,getname()获取,setname()设置这个名词 |
| Ident | 线程id,是非0的整数,线程启动后才会有ID,否则为None,线程退出,此id依旧可以访问,此id可以重复访问。 |
| Is_alive() | 返回线程是否或者 |
线程的name只是一个名称,可以重复;id必须唯一,但可以在线程退出后在利用。
import threading
import time
def worker():
count = 0
while True:
if count > 5:
break
time.sleep(2)
count += 1
print(threading.current_thread().name)
t = threading.Thread(name=’work’,target=worker)
print(t.ident)
t.start()
while True:
time.sleep(1)
if t.is_alive():
print(‘{}{}alive’.format(t.name,t.ident))
else:
print(‘{}{}dead’.format(t.name,t.ident))
| 名称 | 含义 |
| Start() | 启动线程,每一个线程必须且只能执行该方法一次 |
| Run() | 运行线程函数 |
Start()启动线程,只能执行一次。操作系统。开辟新的线程。
Run()直接做的是主线程。函数调用。
(1)start()
import threading
import time
def worker():
count = 0
while True:
if count > 5:
break
time.sleep(3)
count += 1
print(‘running’)
class Mythread(threading.Thread):
def start(self):
print(‘start—-‘)
super().start()
def run(self):
print(‘run—-‘)
super().run()
t = Mythread(target=worker,name=’work’)
t.start()
start方法运行结果是start—-
run—-
Running
按照线程进行执行。
(2)run()
import threading
import time
def worker():
count = 0
while True:
if count>3:
break
time.sleep(2)
count += 1
print(‘runing’)
class Mythread(threading.Thread):
def start(self):
print(‘start—-‘)
super().start()
def run(self):
print(‘run—-‘)
super().run()
t = Mythread(target=worker,name=’work1’)
t.run()
# run—-
# runing
总结:run()执行结果就是直接是函数,调用,调用run函数。
Start()方法会调用run()方法,而run()方法可以运行函数。
- start和run的区别
Start方法启动线程,启动了一个新的线程,名字叫做worker运行,但是run方法,并没有启动新的线程,只是在主线程内调用了一个普通的函数。
7)多线程
多线程,一个进程中如果有多个线程,就是多线程,是先一种并发。
import threading
import time
def worker():
count = 0
while True:
if count>3:
break
time.sleep(2)
count += 1
print(‘runing’)
print(threading.current_thread().name,threading.current_thread().ident)
class Mythread(threading.Thread):
def start(self):
print(‘start—-‘)
super().start()
def run(self):
print(‘run—-‘)
super().run()
t1 = Mythread(target=worker,name=’work1′)
t2 = Mythread(target=worker,name=’work2’)
# t1.run()
# t2.run()
####runing
# MainThread 1380
# runing
# MainThread 1380
# runing
# MainThread 1380
t1.start()
t2.start()
# start—-
# run—-
# start—-
# run—-
# runing
# work2 5048
# runing
# work1 9048
Start()方法work1和work2交替执行。启动线程后,进程内多个活动的线程并行工作,就是多线程。
Run()方法中没有开启新的线程,就是普通函数调用,所以执行完t1.run()
,然后执行t2.run(),run()方法就不是多线程。
一个进程中至少有一个线程,并作为程序的入口,这个线程就是主线程,一个线程必须有一个主线程。
其他线程成为工作线程。
8)线程安全
import threading
def worker():
for x in range(100):
print(‘{}is running’.format(threading.current_thread().name))
for x in range(1,4):
name = ‘worker{}’.format(x)
t = threading.Thread(name=name,target=worker)
t.start()
利用ipython执行的结果是不是一行行的打印,而是很多字符串打印在了一起。
这样说明了print函数被打断了,被线程切换打断了,print函数分为两步,第一步是打印字符串,第二部是换行,就在这个期间,发生了线程的切换,说明了print函数是线程不安全的。
线程安全:线程执行一段代码,不会产生不确定的结果,那么这段代码是线程安全的。
解决上面打印的问题:
(1)不让print打印换行
import threading
def worker():
for x in range(100):
print(‘{} is running.\n’.format(threading.current_thread().name),end=”)
for x in range(1,5):
name = ‘worker{}’.format(x)
t = threading.Thread(name=name,target=worker)
t.start()
利用字符串是不可变类型,可以作为一个整体不可分割输出,end=’’就不在print输出换行了。
- 使用logging
标准库里面的logging模块,是日志处理模块,线程安全的,生产环境代码都使用logging。
import threading
import logging
def worker():
for x in range(100):
# print(‘{} is running.\n’.format(threading.current_thread().name),end=”)
logging.warning(‘{}is running’.format(threading.current_thread().name))
for x in range(1,5):
name = ‘worker{}’.format(x)
t = threading.Thread(name=name,target=worker)
t.start()
9)daemon线程和non-daemon线程
daemon不是Linux里面的守护进程。
进程靠线程执行代码,至少有一个主线程,其他线程是工作线程。
主线程是第一个启动的线程。
父线程:如果A中启动了一个线程B,那么A就是B的父线程。
子线程:B就是A的子线程。
源码Thread的__init__ 方法中。
If deamon is not None:
Self._daemonic = daemon
else:
Self._daemonic = current_thread().daemon
Self._ident = None
线程daemon属性,如果设定就是用户的设置,否则,就取当前线程的daemon的值。
主线程是non-daemon线程,即daemon = False。
import time
import threading
def foo():
time.sleep(5)
for i in range(20):
print(i)
t = threading.Thread(target=foo,daemon=False)
t.start()
print(‘end’)
daemon设置False值,主线程执行完毕后,等待工作线程。
import time
import threading
def foo():
time.sleep(5)
for i in range(20):
print(i)
t = threading.Thread(target=foo,daemon=True)
t.start()
print(‘end’)
Daemon值改为true,主线程执行完毕后直接退出。
| 名称 | 含义 |
| Daemon | 表示线程是否是daemon,这个值必须在start()之前设置,否则引发RuntimeError异常 |
| IsDaemon() | 是否是daemon线程 |
| SetDaemon | 设置daemon线程,必须在start方法之前设置。 |
总结:线程阿具有一个daemon属性,可以显示设置为True或者False,也可以不设置,则取默认值None。
如果不设置daemon,就取当前线程的daemon来设置他。
主线程是non-daemon线程,即daemon = False。
从主线程创建的所有线程的不设置daemon属性,则默认daemon = False,也就是non-daemon线程。
程序在没有活着的non-daemon线程运行时推出,也是就剩下的只是daemon线程,主线程才能推出。否则主线程只能等待。
构造线程的时候,可以设置daemon属性,这个属性必须在start方法前设置好。
daemon=True主线程不等。工作线程
daemon=False主线程等。只要有一个non-daemon就会等待。
控制一个属性的。
在start之前。
只是有一个non-daemon就会等待,没有的话直接不等,直接结束线程。
总结:
线程具有daemon属性,可以设置为True或者False。
(激活的non-daemon,主线程才会等待工作线程。)
import time
import threading
def bar():
time.sleep(10)
print(‘bar’)
def foo():
for i in range(20):
print(i)
t = threading.Thread(target=bar,daemon=False)
t.start()
t = threading.Thread(target=foo,daemon=True)
t.start()
print(‘end’)
这样不会执行bar的,因为主线程的daemon设置的值为True,改为False就好了。
活着让主线程sleep几秒。
import time
import threading
def bar():
time.sleep(10)
print(‘bar’)
def foo(n):
for i in range(n):
print(i)
t1 = threading.Thread(target=foo,args=(10,),daemon=True)
t1.start()
t2 = threading.Thread(target=foo,args=(20,),daemon=False)
t2.start()
time.sleep(6)
print(‘end’)
如果non-daemon线程的时候,主线程退出,也不会结束所有的daemon线程,直到所有的non-daemon线程全部结束,如果还有daemon线程,主线程需要退出,会结束所有的daemon线程,退出。
主线程是non-daemon。其他线程靠传参。
决定的是是否需要等待。如果有激活的non-daemon,就需要等待,没有激活的,主线程直接退出。
- join方法
import time
import threading
def foo(n):
for i in range(n):
print(i)
time.sleep(1)
t1 = threading.Thread(target=foo,args=(10,),daemon=True)
t1.start()
t1.join()
利用join,主线程被迫等待他。把当前线程阻塞住了,x.join就等待谁。保证代码的执行顺序。
使用了join方法后,daemon线程执行完了,主线程才退出了。
Join(timeout= None),是线程的标准方法之一。
一个线程中调用另一个线程的join方法,调用者将被阻塞,直到被调用线程终止。
一个线程可以被join多次。
Timeout参数指定调用者等待多久,没有设置超时的,就会一直等待到调用的线程结束。
调用谁的join方法,就是join谁,就要等睡。
- daemon线程应用场景
简单来说,本来并没有daemon Thread,这个概念唯一的作用是,当把一个线程设置为daemon,他会随着主线程的退出而退出。
主要应用场景为:
- 后台任务。发送心跳包,监控。
- 主线程工作才有用的线程。如主线程中维护着公共的资源,主线程已经清理了,准备退出,而工作线程使用这些资源工作没有意义了,一起退出最合适。
- 随时可以被终止的线程。
如果主线程退出,想所有其他工作线程一起退出,就使用daemon=True来创建工作线程。
import time
import threading
def bar():
while True:
time.sleep(1)
print(‘bar’)
def foo():
print(‘t1 daemon = {}’.format(threading.current_thread().isDaemon()))
t2 = threading.Thread(target=bar)
t2.start()
print(‘t2 daemon = {}’.format(t2.isDaemon()))
t1 = threading.Thread(target=foo,daemon=True)
t1.start()
time.sleep(3)
print(‘Main end’)
改造成一直执行的:
import time
import threading
def bar():
while True:
time.sleep(1)
print(‘bar’)
def foo():
print(‘t1 daemon = {}’.format(threading.current_thread().isDaemon()))
t2 = threading.Thread(target=bar)
t2.start()
t2.join()
print(‘t2 daemon = {}’.format(t2.isDaemon()))
t1 = threading.Thread(target=foo,daemon=True)
t1.start()
t1.join()
time.sleep(3)
print(‘Main end’)
Daemon线程,简化了手动关闭线程的工作。
12)threading.local 类
局部变量的实现:
import threading
import time
def worker():
x = 0
for i in range(10):
time.sleep(0.01)
x += 1
print(threading.current_thread(),x)
for i in range(10):
threading.Thread(target=worker).start()
利用全局变量实现:
import threading
import time
globals_data = threading.local()
def worker():
globals_data.x = 0
for i in range(10):
time.sleep(0.01)
globals_data.x += 1
print(threading.current_thread(),globals_data.x)
for i in range(10):
threading.Thread(target=worker).start()
import threading
X = ‘abc’
ctx = threading.local()
ctx.x = 123
print(ctx,type(ctx),ctx.x)
def worker():
print(X)
print(ctx)
print(ctx.x) #打印的时候出错,表示x不能跨线程
print(‘working’)
worker()
print()
threading.Thread(target=worker).start() #另一个线程启动
threading.local类构建了一个大字典,其元素是每一线程实例地址为key和线程对象引用线程单独的字典的映射。
通过threading.local实例就可在不同的线程中,安全的使用线程独有的数据,做到了线程间数据隔离,如同本地变量一样安全。
Local和线程相关的大字典,每次利用的时候利用线程的小字典来顶替local实例的大字典。
不利用的话,全局变量的话直接就是threading.local和本地线程相关的数据。
13)定时器timer延迟执行
Threading.Timer继承自thread,这个类用来另一多久执行一个函数。
Class threading.Timer(interval,function,args=None,kwargs=None)
Start方法执行以后,Timer对象会处于等待状态,等待了interval之后,开始执行function函数的。如果在执行函数之前的等待阶段,使用了cancel方法,就会跳过执行函数结果。
本质上就是一个Thread,只是没有提供name,daemon。
import threading
import logging
import time
def worker():
logging.info(‘in worker’)
time.sleep(2)
t = threading.Timer(5,worker)
t.start() #启动
print(threading.enumerate())
t.cancel() #取消
time.sleep(1)
print(threading.enumerate())
[<_MainThread(MainThread, started 7512)>, <Timer(Thread-1, started 6644)>]
[<_MainThread(MainThread, started 7512)>]
import threading
import logging
import time
def worker():
logging.info(‘in worker’)
time.sleep(2)
t = threading.Timer(5,worker)
t.cancel() #取消
t.start() #启动
print(threading.enumerate())
time.sleep(1)
print(threading.enumerate())
[<_MainThread(MainThread, started 7512)>]
[<_MainThread(MainThread, started 7512)>]
二、线程同步
1、概念
线程同步,线程间协同,通过某种技术,让一个线程访问某些数据时候,其他线程不能访问这些数据,直到该线程完成对数据的操作。
不同操作系统实现技术有所不同,有临界区、互斥量、信号量、事件Event。
2、Event
Event事件,是线程间通信机制中最简单的实现,使用一个内部的标记flag,通过flag的True或False的变化来进行操作。
| 名称 | 含义 |
| set() | 标记为True |
| clear() | 标记为False |
| is_set() | 标记是否为True |
| Wait(timeout=None) | 设置等待标记为True的时长,None为无限等待,等到返回True,未等到超时了返回False。 |
课堂练习:老板雇佣了一个工人,让他生产杯子,老板一直等着这个工人,直到上产了十个杯子。
1)利用join
import threading
import time
import logging
def worker(count=10):
cups = []
while len(cups)<count:
logging.info(‘wprking’)
time.sleep(0.01)
cups.append(1)
print(len(cups))
logging.info(‘I am finished’)
w = threading.Thread(target=worker)
w.start()
w.join()
2)利用event
import threading
import logging
import time
def boss(event:threading.Event):
logging.info(‘I am boss,waiting’)
event.wait()
logging.info(‘good job’)
def worker(event:threading.Event,count=10):
logging.info(‘I am working for u’)
cups = []
while True:
logging.info(‘makeing’)
time.sleep(1)
cups.append(1)
if len(cups) >= count:
print(len(cups))
event.set()
break
logging.info(‘finished my job.cups={}’.format(cups))
event = threading.Event()
w = threading.Thread(target=worker,args=(event,))
b = threading.Thread(target=boss,args=(event,))
w.start()
b.start()
- wait的应用
import threading
import logging
logging.basicConfig(level=logging.INFO)
def do(event:threading.Event,interval:int):
while not event.wait(interval): #没有置set,所以是False。 不是False的时候就不能进入循环了。
logging.info(‘do sth’) #没三秒打印一次。 not False执行此语句
e = threading.Event()
threading.Thread(target=do,args=(e,10)).start()
e.wait(12) #整体停留了十秒。
e.set() #重置为True。
print(‘end’)
- 练习,实现timer。
总结:
使用同一个Event用来做标记。
Event的wait优于time.sleep,更快的切换到其他线程,提高并发效率。
import threading
import time
class MyTimer:
def __init__(self,interval,function,args,kwargs):
self.interval = interval
self.target = function
self.args = args
self.kwargs = kwargs
self.event = threading.Event()
self.thread = threading.Thread(target=self.target,args=self.args,kwargs=self.kwargs)
def start(self):
self.event.wait(self.interval)
if not self.event.is_set(): #如果没有置False,那么就是False,not False为True,执行run语句。
self.run()
def run(self):
self.start()
self.event.set()
def cancel(self):
self.event.set()
三、Lock锁
1)锁,凡是存在共享资源争抢的地方都可以使用锁。从而保证只有一个使用者可以完全使用这个资源。
lock.acquire 上锁 lock.release 解锁
import threading
import logging
import time
FORMAT = ‘%(asctime)s %(threadName)s %(thread)d %(message)s’
logging.basicConfig(format=FORMAT,level=logging.INFO)
cups = []
def worker(count=10):
logging.info(‘i am work’)
while len(cups) < count:
time.sleep(0.1)
cups.append(1)
logging.info(‘i am finsh.cups={}’.format(len(cups)))
for _ in range(10):
threading.Thread(target=worker,args=(1000,)).start()
2018-05-26 15:38:25,913 Thread-1 32 i am work
2018-05-26 15:38:25,913 Thread-2 4332 i am work
2018-05-26 15:38:25,913 Thread-3 9992 i am work
2018-05-26 15:38:25,914 Thread-4 8464 i am work
2018-05-26 15:38:25,914 Thread-5 9968 i am work
2018-05-26 15:38:25,915 Thread-6 8712 i am work
2018-05-26 15:38:25,915 Thread-7 4412 i am work
2018-05-26 15:38:25,915 Thread-8 8456 i am work
2018-05-26 15:38:25,915 Thread-9 8316 i am work
2018-05-26 15:38:25,915 Thread-10 9772 i am work
2018-05-26 15:38:35,925 Thread-8 8456 i am finsh.cups=1000
2018-05-26 15:38:36,023 Thread-7 4412 i am finsh.cups=1001
2018-05-26 15:38:36,023 Thread-1 32 i am finsh.cups=1002
2018-05-26 15:38:36,023 Thread-6 8712 i am finsh.cups=1003
2018-05-26 15:38:36,024 Thread-5 9968 i am finsh.cups=1004
2018-05-26 15:38:36,024 Thread-4 8464 i am finsh.cups=1005
2018-05-26 15:38:36,024 Thread-10 9772 i am finsh.cups=1006
2018-05-26 15:38:36,024 Thread-2 4332 i am finsh.cups=1007
2018-05-26 15:38:36,025 Thread-3 9992 i am finsh.cups=1008
2018-05-26 15:38:36,025 Thread-9 8316 i am finsh.cups=1009
运行结果来看,多线程调度,导致了判断失误,多生产了杯子只有用到了锁。
Lock,锁,一旦线程获得锁,其他要获得锁的线程将被阻塞。
| 名称 | 含义 |
| acquire(blocking=True,timeout=-1) | 默认阻塞,阻塞可以设置超时时间,非阻塞时,timeout禁止设置,成果获取锁,返回True,否则返回None |
| Release | 释放锁,可以从任何线程调用释放,
已上锁的锁,会被重置到unlocked未上锁的锁上调用,抛出RuntimeError异常。 |
import threading
import logging
import time
FORMAT = ‘%(asctime)s %(threadName)s %(thread)d %(message)s’
logging.basicConfig(format=FORMAT,level=logging.INFO)
cups = []
lock = threading.Lock()
def worker(count=10):
logging.info(‘i am work’)
lock.acquire()
while len(cups) < count:
print(threading.current_thread(),len(cups))
time.sleep(0.000001)
cups.append(1)
logging.info(‘i am finsh.cups={}’.format(len(cups)))
lock.release()
for _ in range(10):
threading.Thread(target=worker,args=(1000,)).start()
上锁位置不对,由一个线程抢占,并独自占锁并完成任务。
import threading
import logging
import time
FORMAT = ‘%(asctime)s %(threadName)s %(thread)d %(message)s’
logging.basicConfig(format=FORMAT,level=logging.INFO)
cups = []
lock = threading.Lock()
def worker(count=10):
logging.info(‘i am work’)
flag= False
while True:
lock.acquire() #获取锁
if len(cups) >= count:
flag = True
# print(threading.current_thread(),len(cups))
time.sleep(0.000001)
if not flag:
cups.append(1)
print(threading.current_thread(),len(cups))
lock.release() #追加后释放锁
if flag:
break
logging.info(‘i am finsh.cups={}’.format(len(cups)))
for _ in range(10):
threading.Thread(target=worker,args=(1000,)).start()
锁保证了数据完整性,但是性能下降好多。
If flag:break是为了保证release方法被执行,否则就出现了死锁,得到锁的永远没有释放。
计数器类,可以加可以减。
2)加锁、解锁
一般加锁就需要解锁,但是加锁后解锁前,还要有一些代码执行,就有可能抛出异常,一旦出现异常锁是无法释放的,但是当前线程可能因为这个就异常终止了,这就产生了死锁。
加锁。解锁常用语句:
- 使用..finally语句保证锁的释放。
- With上下文管理,锁对象支持上下文管理。
import threading
import time
class Counter:
def __init__(self):
self._val = 0
self.__lock = threading.Lock()
@property
def value(self):
return self._val
def inc(self):
try:
self.__lock.acquire()
self._val += 1
finally:
self.__lock.release()
def dec(self):
with self.__lock:
self._val -= 1
def run(c:Counter,count=1000):
for _ in range(10):
for i in range(-50,50):
if i<0:
c.dec()
else:
c.inc()
c = Counter()
c1 = 10
c2 = 10
for i in range(c1):
threading.Thread(target=run,args=(c,c2)).start()
while True:
time.sleep(1)
if threading.active_count() == 1:
print(threading.enumerate())
print(c.value)
break
else:
print(threading.enumerate())
不影响其他线程的切换,但是上锁后其他线程被阻塞了。只能等待。
3)锁的应用场景
适用于访问和修改同一个共享资源的时候,读写同一个资源的时候。
全部是读取同一个共享资源需要锁吗?
因为共享资源是不可变的,每一次读取都是一样的值,所以不用加锁。
使用锁的注意事项:
少用锁必要时用锁,使用了锁,多线程访问被锁的资源时候,就成了串行,要么排队执行,要么争抢执行。
加锁时间越短越好,不需要拍就立即释放锁。
一定要避免死锁。
不使用锁,有了效率,但是结果是错的。
使用了锁,效率低下,但是结果是对的。
4)非阻塞锁使用
import threading
import logging
import time
FORMAT = ‘%(asctime)s %(threadName)s %(thread)d %(message)s’
logging.basicConfig(format=FORMAT,level=logging.INFO)
def worker(tasks):
for task in tasks:
time.sleep(0.01)
if task.lock.acquire(False):
logging.info(‘{}{}begin to start’.format(threading.current_thread(),task.name))
else:
logging.info(‘{}{}is working’.format(threading.current_thread(),task.name))
class Task:
def __init__(self,name):
self.name = name
self.lock = threading.Lock()
tasks = [Task(‘task-{}’.format(x))for x in range(10)]
for i in range(5):
threading.Thread(target=worker,name=’worker-{}’.format(i),args=(tasks,)).start()
5)可重入锁RLock:
是线程相关的锁
线程A可重复锁,并可以多次成功获取,不会阻塞 ,最后要在线程A中做和acquire次数相同的release。
拿到这把锁的线程可以多次使用。
别的线程拿到的话也是被阻塞的。
一个线程占用锁的时候,其他线程不能拿到,只能的是阻塞。直到当前线程次有的锁全部释放完,其他线程才可以获取。
可重入锁,与线程相关,可在一个线程中获取锁,并可继续在同一线程中不阻塞获取锁,当锁未释放完,其他线程获取锁就会阻塞。直到当前持有锁的线程释放完了锁。
四、Condition
构造方法:condition(lock=None),可以传入一个lock对象或Rlock对象,默认是Rlock。
| 名称 | 含义 |
| Acquire(*args) | 获取锁 |
| Wait(self,timeout=None) | 等待超时 |
| Notify(n=1) | 唤醒之多指定书目个数的等待的线程,没有等待的线程就没有任何操作 |
| Notify_all() | 唤醒所有等待的线程。 |
用于生产者、消费者模型,为了解决生产者消费者速度匹配的问题:
import threading
import logging
import random
FORMAT = ‘%(asctime)s %(threadName)s %(thread)d %(message)s’
logging.basicConfig(format=FORMAT,level=logging.INFO)
class Dispatcher:
def __init__(self):
self.data = None
self.event = threading.Event()
def produce(self,total):
for _ in range(total):
data = random.randint(0,100)
logging.info(data)
self.data = data
self.event.wait(1)
self.event.set()
def consume(self):
while not self.event.is_set():
data = self.data
logging.info(‘recieved{}’.format(data))
self.data = None
self.event.wait(0.5)
d = Dispatcher()
p = threading.Thread(target=d.produce,args=(10,),name=’producer’)
c = threading.Thread(target=d.consume,name=’consume’)
c.start()
p.start()
消费者采用主动消费,消费者浪费了大量的时间,主动来查看有没有数据。换成通知的机制。
import threading
import logging
import random
FORMAT = ‘%(asctime)s %(threadName)s %(thread)d %(message)s’
logging.basicConfig(format=FORMAT,level=logging.INFO)
class Dispatcher:
def __init__(self):
self.data = None
self.event = threading.Event()
self.cond = threading.Condition()
def produce(self,total):
for _ in range(total):
data = random.randint(0,100)
with self.cond:
logging.info(data)
self.data = data
self.cond.notify_all()
self.event.wait(1)
self.event.set()
def consume(self):
while not self.event.is_set():
with self.cond:
self.cond.wait()
logging.info(‘recieved{}’.format(self.data))
self.data = None
self.event.wait(0.5)
d = Dispatcher()
p = threading.Thread(target=d.produce,args=(10,),name=’producer’)
c = threading.Thread(target=d.consume,name=’consume’)
c.start()
p.start()
如果是一个生产者,多个消费者呢:
import threading
import logging
import random
FORMAT = ‘%(asctime)s %(threadName)s %(thread)d %(message)s’
logging.basicConfig(format=FORMAT,level=logging.INFO)
class Dispatcher:
def __init__(self):
self.data = None
self.event = threading.Event()
self.cond = threading.Condition()
def produce(self,total):
for _ in range(total):
data = random.randint(0,100)
with self.cond:
logging.info(data)
self.data = data
self.cond.notify_all()
self.event.wait(1) #模拟生产速度
self.event.set()
def consume(self):
while not self.event.is_set():
with self.cond:
self.cond.wait() #阻塞等通知
logging.info(‘recieved{}’.format(self.data))
self.data = None
self.event.wait(0.5) #模拟消费 的速度
d = Dispatcher()
p = threading.Thread(target=d.produce,args=(10,),name=’producer’)
for i in range(5):
c = threading.Thread(target=d.consume, name=’consume{}’.format(i))
c.start()
p.start()
Self.cond.notify_all()发通知:
修改为self.cond.notify(n=2) 随机通知两个消费者。
Condition总结:
用于生产者消费者模型中,解决生产者,消费者速度匹配的问题。
采用了通知机制,非常有效率。
使用方式:
使用condition,必须先acquire,用完了要release。因为内部实现了锁,默认使用了RLock锁。最好的方式就是使用上下文。
消费者wait,等待通知。
生产者生产好消息,对消费者发出通知,可以使用notify或者notify_all方法。
本文来自投稿,不代表Linux运维部落立场,如若转载,请注明出处:http://www.178linux.com/99570

