

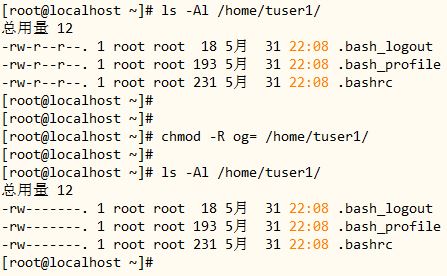
1、复制/etc/skel目录为/home/tuser1,要求/home/tuser1及其内部文件的属组和其它用户均没有任何访问权限。
● 实现命令
[root@localhost ~]#cp -r /etc/skel /home/tuser1
[root@localhost ~]#chmod -R og= /home/tuser1
● 命令分解
cp:复制命令,使用 -r 选项进行目录递归复制;
chmod:修改用户和组权限,使用 -R 选项进行递归修改,命令中 “o”表示其他用户,”g”表示组,等于空值即表示没有任何访问权限。
2、编辑/etc/group文件,添加组hadoop。
● 实现命令
[root@localhost ~]#vim /etc/group
添加:hadoop:x:2019:

● 命令分解
vim:编辑配置文件命令,添加组名、组ID。
3、手动编辑/etc/passwd文件新增一行,添加用户hadoop,其基本组ID为hadoop组的id号;其家目录为/home/hadoop。
● 实现命令
[root@localhost ~]#vim /etc/passwd
添加:hadoop:x:2003:2019::/home/hadoop:/bin/bash

● 命令分解
vim:编辑配置文件命令,添加用户名、用户ID、组ID、家目录和默认shell。
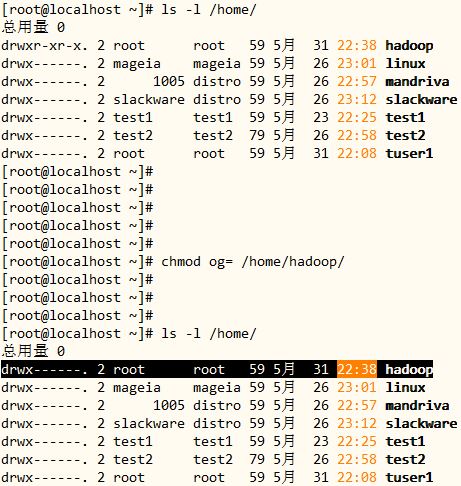
4、复制/etc/skel目录为/home/hadoop,要求修改hadoop目录的属组和其它用户没有任何访问权限。
● 实现命令
[root@localhost ~]# cp -r /etc/skel/ /home/hadoop
[root@localhost ~]# chmod og= /home/hadoop/
● 命令分解
cp:复制命令,使用 -r 选项进行目录递归复制;
chmod:修改用户和组权限,命令中 “o”表示其他用户,”g”表示组,等于空值即表示该目录没有任何访问权限。
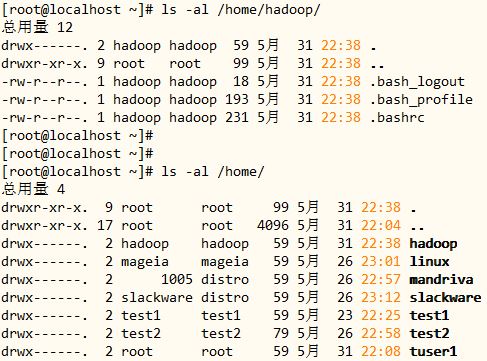
5、修改/home/hadoop目录及其内部所有文件的属主为hadoop,属组为hadoop。
● 实现命令
[root@localhost ~]# chown -R hadoop:hadoop /home/hadoop/
● 命令分解
chown:更改文件或目录的从属关系,使用 -R 选项进行递归修改;
6、显示/proc/meminfo文件中以大写或小写S开头的行,用两种方式;
● 实现命令
[root@localhost ~]# grep “^[sS]” /proc/meminfo
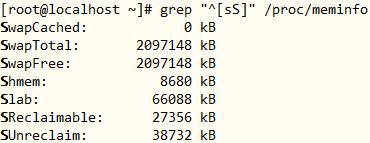
[root@localhost ~]# grep -i “^s” /proc/meminfo
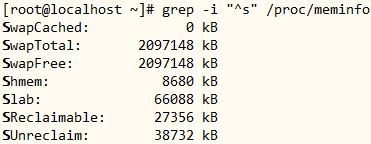
● 命令分解
grep:文本搜索工具,根据指定的过滤条件对目标文本逐行进行匹配检查;
正则表达式 ^:行首锚定;
正则表达式 []:匹配指定范围内的任意单个字符;
第二种方法中的 -i 选项:表示忽略字符的大小写。
7、显示/etc/passwd文件中其默认shell为非/sbin/nologin的用户;
● 实现命令
[root@localhost ~]# grep -v “/sbin/nologin$” /etc/passwd | cut -d “:” -f1
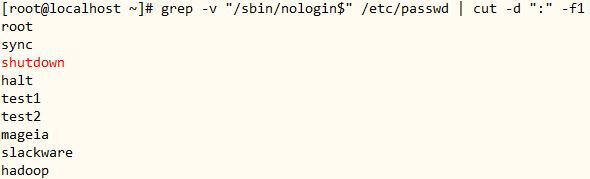
● 命令分解
grep:文本搜索,使用 -v 选项进行反向显示,即显示不能匹配到的文本内容;
正则表达式 $:行尾锚定;
cut:使用 -d 和 -f 选项截取出用户名。
8、显示/etc/passwd文件中其默认shell为/bin/bash的用户;
● 实现命令
[root@localhost ~]# grep “/bin/bash$” /etc/passwd | cut -d “:” -f1
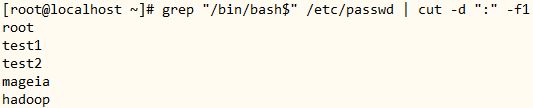
● 命令分解
grep:文本搜索;
正则表达式 $:行尾锚定;
cut:使用 -d 和 -f 选项截取出用户名。
9、找出/etc/passwd文件中的一位数或两位数;
● 实现命令
[root@localhost ~]# grep -o “\<[0-9]\{1,2\}\>” /etc/passwd

● 命令分解
grep:文本搜索,使用 -o 选项只显示匹配到的内容本身;
正则表达式 \< \>:词首、词尾锚定;
正则表达式 [0-9]:匹配指定范围内的数字;
正则表达式 \{1,2\}:表示前面的数字,出现1~2次。
10、显示/boot/grub2/grub.cfg中以至少一个空白字符开头的行;
● 实现命令
[root@localhost ~]# grep “^[[:space:]]\+” /boot/grub2/grub.cfg
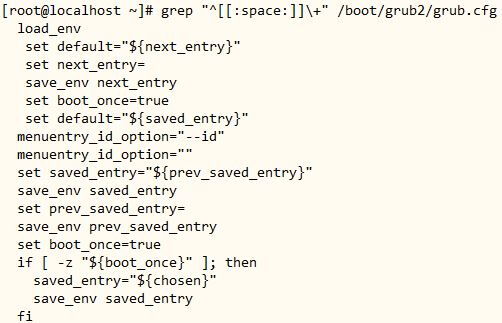
● 命令分解
grep:文本搜索;
正则表达式 ^:行首锚定;
正则表达式 [[:space:]]:空白字符;
正则表达式 \+:前面的内容至少出现一次。
11、显示/etc/rc.local文件中以#开头,后面跟至少一个空白字符,而后又有至少一个非空白字符的行;
● 实现命令
[root@localhost ~]# grep “^#[[:space:]]\+[^[:space:]]\+” /etc/rc.local
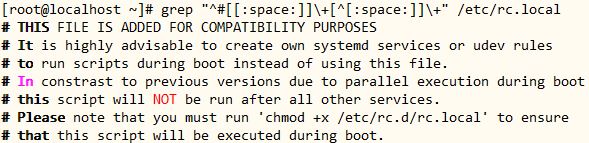
● 命令分解
grep:文本搜索;
正则表达式 ^:行首锚定;
正则表达式 \+:前面的内容至少出现一次;
正则表达式 [^]:匹配指定范围外的任意字符。
12、打出netstat -tan命令执行结果中以‘LISTEN’,后或跟空白字符结尾的行;
● 实现命令
[root@localhost ~]# netstat -tan | grep “LISTEN[[:space:]]\+”

● 命令分解
|grep:使用管道进行文本内容搜索;
正则表达式 [[:space:]]\+:表示前面的空格字符至少出现一次。
13、添加用户bash, testbash, basher, nologin (此一个用户的shell为/sbin/nologin),而后找出当前系统上其用户名和默认shell相同的用户的信息;
● 实现命令
[root@localhost ~]# useradd bash
[root@localhost ~]# useradd testbash
[root@localhost ~]# useradd basher
[root@localhost ~]# useradd -s /sbin/nologin nologin
[root@localhost ~]# grep -E “^([^:]+\>).*\1$” /etc/passwd
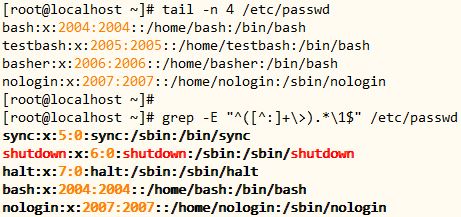
● 命令分解
grep:文本匹配,使用 -E 选项使用扩展正则表达式进行查找内容的匹配;
正则表达式 ^([^:]+\>):锚定行首及词尾,匹配非冒号的内容,并进行分组引用;
正则表达式 .*:中间是任意字符,出现任意次;
正则表达式 \1$:锚定行尾,内容是之前括号里匹配到的字符;
本文来自投稿,不代表Linux运维部落立场,如若转载,请注明出处:http://www.178linux.com/99875

